Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
作者: Liang-Hsuan Tseng, Zih-Ching Chen, Wei-Shun Chang, Cheng-Kuang Lee, Tsung-Ren Huang, Hung-yi Lee
分类: eess.AS, cs.CL, cs.SD
发布日期: 2024-07-15
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出K²D方法,利用无标注数据蒸馏,提升代码切换语音识别效率与精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码切换语音识别 知识蒸馏 语音识别 模型压缩 无监督学习
📋 核心要点
- 大型语音基础模型在语音识别中表现出色,但计算资源需求高,在代码切换等复杂场景中问题尤为突出。
- K²D方法通过知识蒸馏,结合教师模型知识和辅助模型洞察,在无标注真实数据上训练高效的CS-ASR模型。
- 实验表明,K²D方法在模型大小和速度上显著提升,并在多个数据集上超越了基线和教师模型。
📝 摘要(中文)
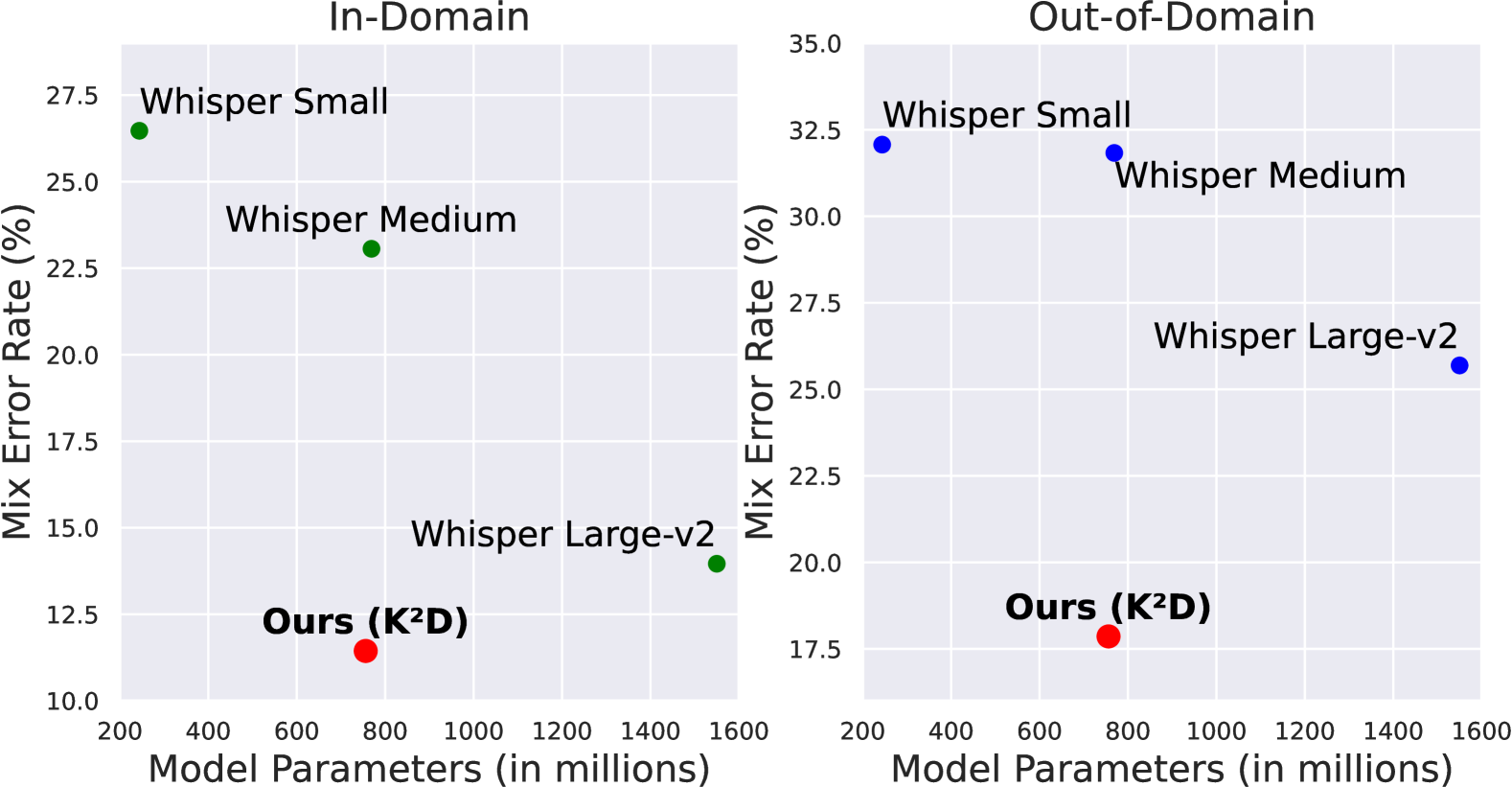
本文提出了一种名为“不遗漏知识的知识蒸馏”(K²D)的框架,旨在利用现实语音数据,为代码切换语音识别(CS-ASR)开发更高效的模型。该方法充分利用教师模型的知识,并结合小型辅助模型的额外洞察。在两个领域内和两个领域外的数据集上的评估表明,K²D方法是有效的。通过在未标注的真实数据上进行K²D,成功获得了一个体积缩小2倍、生成速度提高5倍的模型,并在所有测试集上优于基线方法和教师模型。该模型已在Hugging Face上公开。
🔬 方法详解
问题定义:代码切换语音识别(CS-ASR)任务面临着计算资源有限的挑战,尤其是在实际应用场景中。现有方法通常依赖大型语音基础模型,但这些模型的部署成本很高,难以在资源受限的环境中使用。因此,需要开发一种更高效的CS-ASR模型,能够在保持甚至提升性能的同时,显著降低计算需求。
核心思路:论文的核心思路是利用知识蒸馏技术,将大型教师模型的知识迁移到小型学生模型中。为了更有效地利用教师模型的知识,并避免信息损失,论文引入了一个小型辅助模型,从另一个角度提供知识。通过结合教师模型和辅助模型的知识,学生模型能够学习到更全面的信息,从而提升性能。
技术框架:K²D框架包含三个主要组成部分:大型教师模型、小型学生模型和小型辅助模型。首先,使用大型教师模型生成未标注真实数据的伪标签。然后,利用这些伪标签,同时结合辅助模型的输出,训练学生模型。训练过程中,学生模型不仅要学习模仿教师模型的输出,还要学习辅助模型的知识。
关键创新:K²D的关键创新在于同时利用教师模型和辅助模型的知识进行知识蒸馏。传统的知识蒸馏方法通常只依赖教师模型的输出,可能会忽略一些重要的信息。通过引入辅助模型,K²D能够从不同的角度提取知识,从而更全面地指导学生模型的学习。
关键设计:辅助模型是一个小型模型,其结构与学生模型相似,但参数量较少。在训练过程中,辅助模型与教师模型一起,对未标注数据进行预测。学生模型的损失函数包含两部分:一部分是模仿教师模型输出的损失,另一部分是模仿辅助模型输出的损失。通过调整这两个损失的权重,可以控制学生模型对教师模型和辅助模型的依赖程度。论文中具体使用的损失函数和权重设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,通过K²D方法训练得到的学生模型,在模型大小缩小2倍、生成速度提高5倍的同时,在所有测试集上均优于基线方法和教师模型。这表明K²D方法能够有效地将知识从大型模型迁移到小型模型,并在实际应用中取得显著的性能提升。具体的性能指标提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要高效代码切换语音识别的场景,例如移动设备上的语音助手、实时语音翻译、以及资源受限的嵌入式系统。通过降低模型大小和提高推理速度,K²D方法使得CS-ASR技术能够更广泛地部署和应用,从而提升用户体验和拓展应用领域。
📄 摘要(原文)
Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).