TCM-FTP: Fine-Tuning Large Language Models for Herbal Prescription Prediction
作者: Xingzhi Zhou, Xin Dong, Chunhao Li, Yuning Bai, Yulong Xu, Ka Chun Cheung, Simon See, Xinpeng Song, Runshun Zhang, Xuezhong Zhou, Nevin L. Zhang
分类: cs.CL, cs.AI, cs.CE
发布日期: 2024-07-15 (更新: 2024-12-12)
备注: Camera-ready version to be published in BIBM 2024
💡 一句话要点
TCM-FTP:通过微调大型语言模型进行中药处方预测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中药处方预测 大型语言模型 微调 数据增强 消化系统疾病 中医 自然语言处理
📋 核心要点
- 中药处方预测面临高质量数据稀缺和症状-草药关系复杂两大挑战,现有方法难以有效应对。
- TCM-FTP通过在消化系统疾病数据集DigestDS上微调预训练LLM,并结合数据增强来提升预测性能。
- 实验表明,TCM-FTP在处方预测和剂量预测上均显著优于现有方法,F1值达到0.8031,NMSE达到0.0604。
📝 摘要(中文)
传统中医药依赖于特定的草药组合来治疗各种症状和体征。预测中药处方是一个引人入胜的技术挑战,具有重要的实际意义。然而,由于高质量临床数据集的稀缺以及症状与草药之间复杂的关系,这项任务面临着限制。为了解决这些问题,我们引入了 extit{DigestDS},这是一个包含经验丰富的消化系统疾病专家提供的实际医疗记录的新数据集。我们还提出了一种名为TCM-FTP(TCM Fine-Tuning Pre-trained)的方法,通过在 extit{DigestDS}上进行监督微调来利用预训练的大型语言模型(LLM)。此外,我们使用低秩适应技术来提高计算效率。而且,TCM-FTP通过置换处方中的草药来结合数据增强,利用了它们的顺序无关性。令人印象深刻的是,TCM-FTP实现了0.8031的F1分数,显著优于以前的方法。此外,它在剂量预测方面表现出卓越的准确性,实现了0.0604的归一化均方误差。相比之下,未经微调的LLM表现不佳。虽然LLM已经展示了广泛的能力,但我们的工作强调了微调对于中药处方预测的必要性,并提出了一种有效的方法来实现这一点。
🔬 方法详解
问题定义:论文旨在解决中药处方预测问题,即根据患者的症状和体征,预测合适的草药组合及其剂量。现有方法受限于高质量临床数据集的匮乏,以及症状与草药之间复杂且非线性的关系,导致预测准确率较低。此外,直接应用大型语言模型(LLM)进行中药处方预测,未经针对性训练,效果不佳。
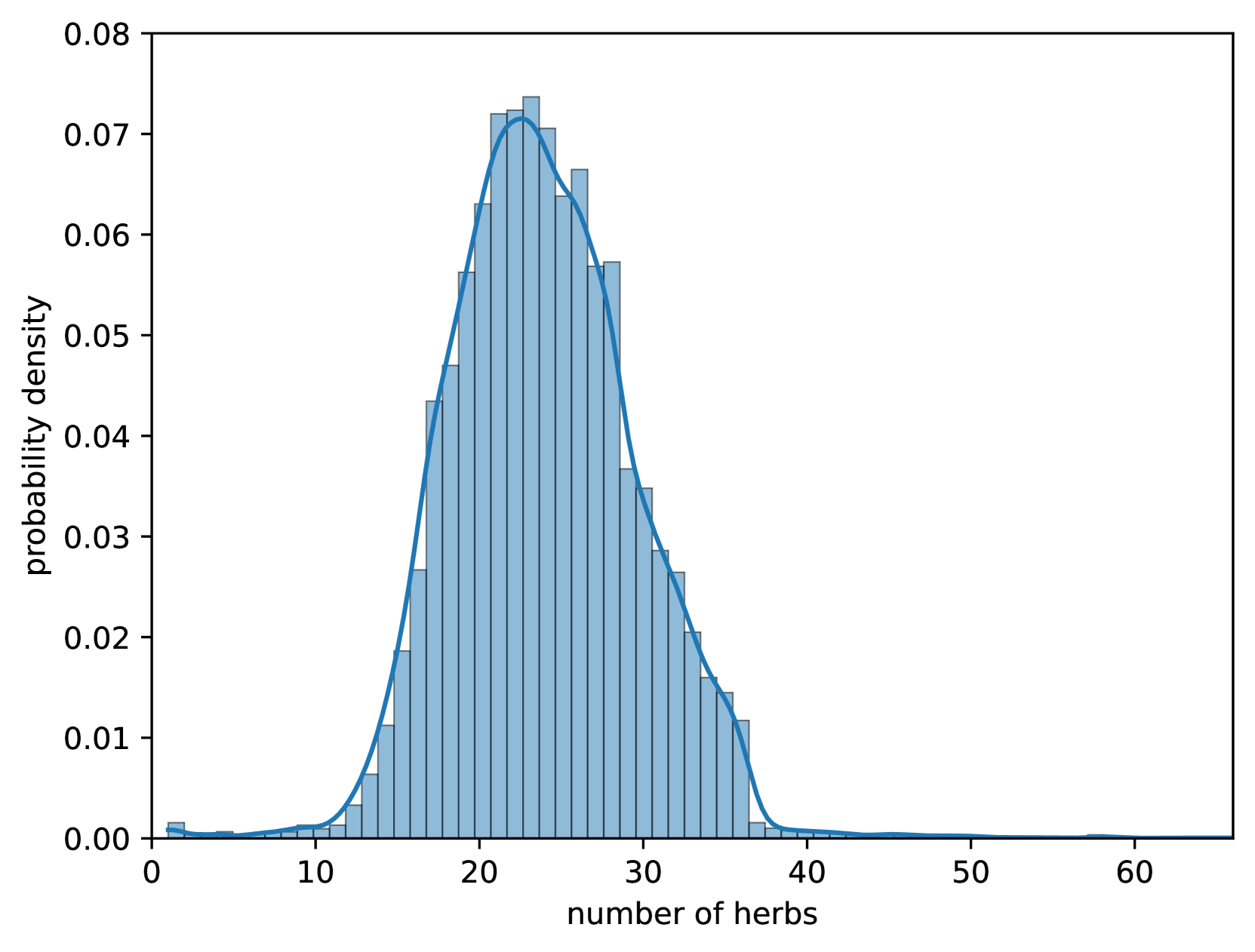
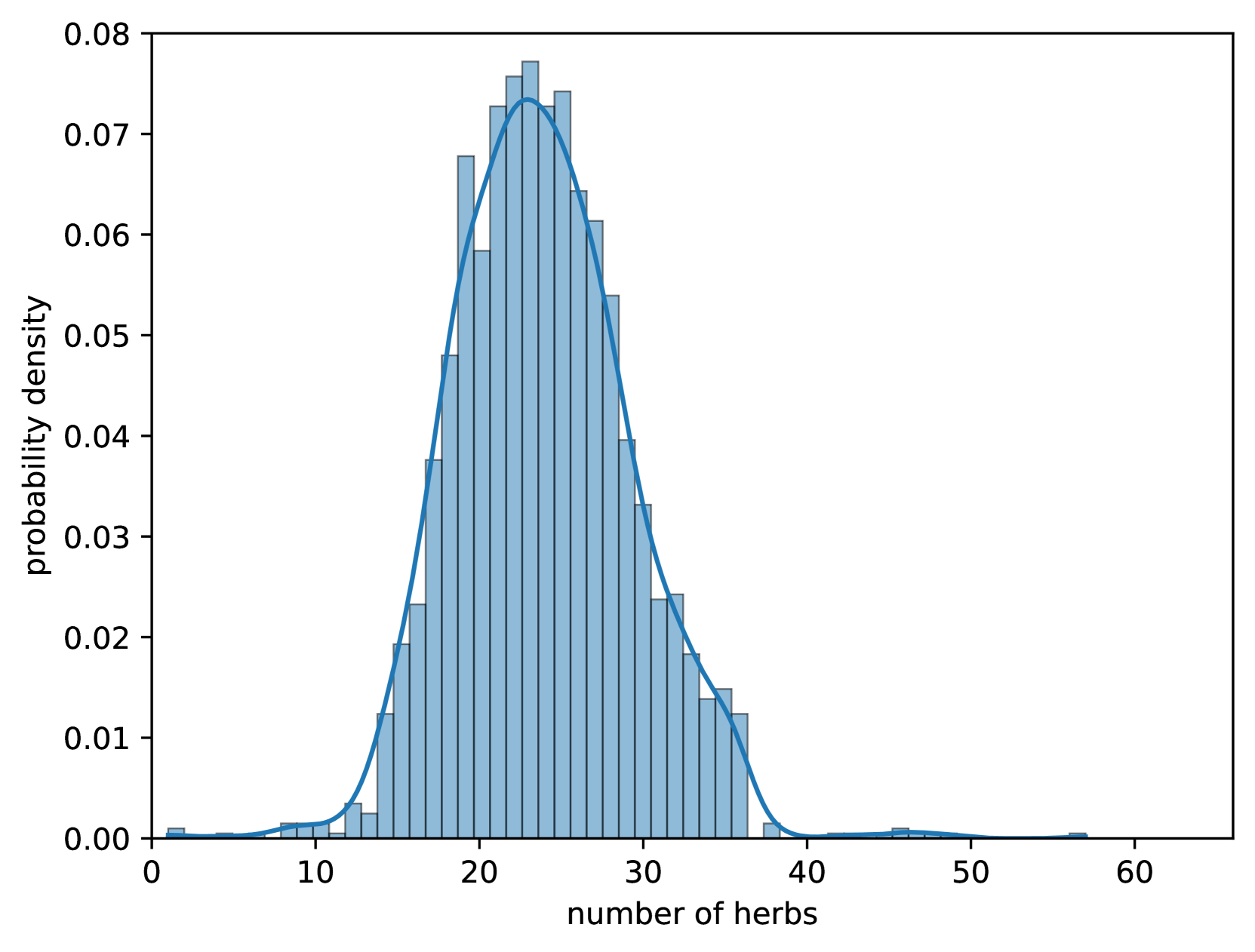
核心思路:论文的核心思路是利用预训练的大型语言模型(LLM)的强大语言理解和生成能力,通过在特定领域的数据集上进行微调,使其适应中药处方预测任务。同时,考虑到中药处方中草药的顺序通常不影响药效,采用数据增强技术,通过置换处方中的草药顺序来增加训练数据,提高模型的泛化能力。
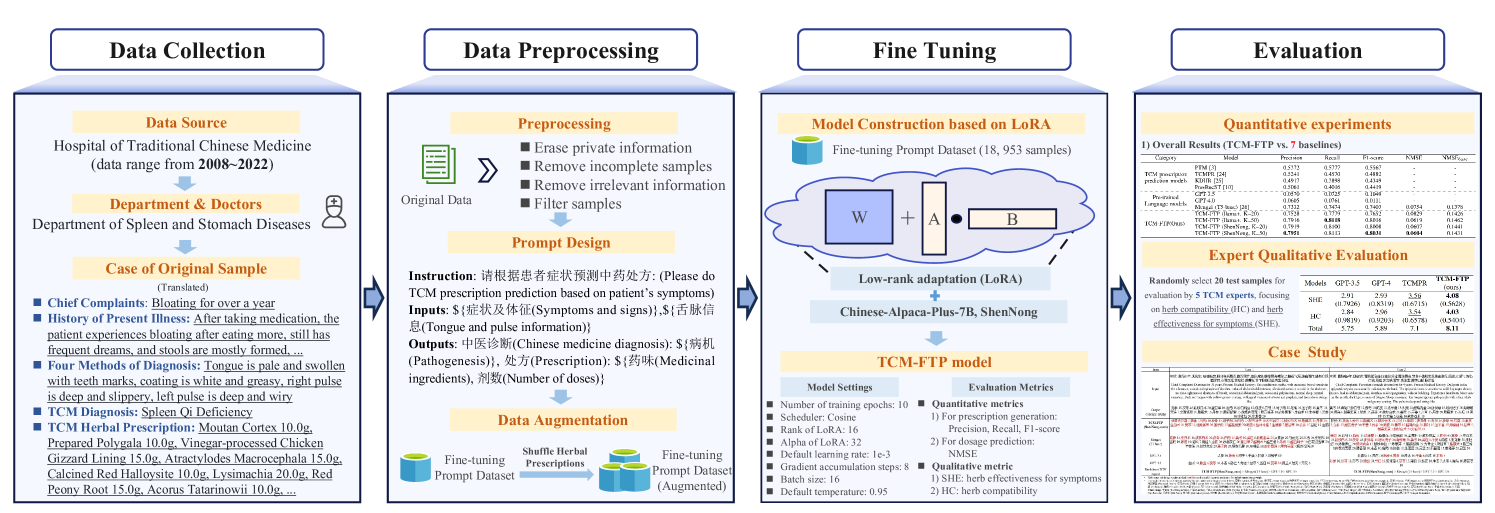
技术框架:TCM-FTP方法主要包含以下几个阶段:1) 构建消化系统疾病数据集DigestDS,包含专家经验的医疗记录;2) 选择合适的预训练LLM作为基础模型;3) 在DigestDS数据集上对LLM进行监督微调,使其学习中药处方预测的知识;4) 采用低秩适应(LoRA)技术,减少微调过程中的计算量;5) 使用数据增强技术,通过置换处方中的草药顺序来扩充训练数据。
关键创新:论文的关键创新点在于:1) 构建了高质量的消化系统疾病数据集DigestDS,为中药处方预测提供了宝贵的数据资源;2) 提出了TCM-FTP方法,通过微调预训练LLM,有效利用了LLM的强大能力,显著提高了中药处方预测的准确率;3) 结合了数据增强技术,进一步提升了模型的泛化能力。与现有方法相比,TCM-FTP方法能够更好地捕捉症状与草药之间的复杂关系,从而实现更准确的处方预测。
关键设计:在微调过程中,采用了监督学习的方式,使用DigestDS数据集中的处方作为标签。损失函数方面,可能采用了交叉熵损失函数或类似的损失函数,用于衡量模型预测的处方与真实处方之间的差异。在数据增强方面,采用了随机置换处方中草药顺序的方法,增加了训练数据的多样性。此外,论文还采用了低秩适应(LoRA)技术,通过冻结预训练模型的大部分参数,只训练少量参数,从而减少了计算量,提高了训练效率。具体的参数设置和网络结构细节可能在论文正文中给出,此处未知。
🖼️ 关键图片
📊 实验亮点
TCM-FTP在处方预测任务上取得了显著的性能提升,F1分数达到0.8031,显著优于之前的模型。在剂量预测方面,TCM-FTP也表现出色,归一化均方误差(NMSE)仅为0.0604。实验结果表明,通过在特定领域数据集上微调预训练LLM,可以有效提高中药处方预测的准确率。
🎯 应用场景
该研究成果可应用于智能中医辅助诊疗系统,辅助医生进行处方决策,提高诊疗效率和准确性。同时,该方法也可推广到其他中医领域,例如针灸、推拿等,促进中医药的现代化和智能化发展。未来,结合患者的基因组信息、生活习惯等,有望实现个性化定制的中药处方。
📄 摘要(原文)
Traditional Chinese medicine (TCM) has relied on specific combinations of herbs in prescriptions to treat various symptoms and signs for thousands of years. Predicting TCM prescriptions poses a fascinating technical challenge with significant practical implications. However, this task faces limitations due to the scarcity of high-quality clinical datasets and the complex relationship between symptoms and herbs. To address these issues, we introduce \textit{DigestDS}, a novel dataset comprising practical medical records from experienced experts in digestive system diseases. We also propose a method, TCM-FTP (TCM Fine-Tuning Pre-trained), to leverage pre-trained large language models (LLMs) via supervised fine-tuning on \textit{DigestDS}. Additionally, we enhance computational efficiency using a low-rank adaptation technique. Moreover, TCM-FTP incorporates data augmentation by permuting herbs within prescriptions, exploiting their order-agnostic nature. Impressively, TCM-FTP achieves an F1-score of 0.8031, significantly outperforming previous methods. Furthermore, it demonstrates remarkable accuracy in dosage prediction, achieving a normalized mean square error of 0.0604. In contrast, LLMs without fine-tuning exhibit poor performance. Although LLMs have demonstrated wide-ranging capabilities, our work underscores the necessity of fine-tuning for TCM prescription prediction and presents an effective way to accomplish this.