How and where does CLIP process negation?
作者: Vincent Quantmeyer, Pablo Mosteiro, Albert Gatt
分类: cs.CL, cs.AI
发布日期: 2024-07-15
备注: Accepted at the 3rd Workshop on Advances in Language and Vision Research (ALVR 2024)
💡 一句话要点
深入剖析CLIP如何处理否定概念,揭示多模态模型内部机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: CLIP模型 否定概念 可解释性 多模态学习 视觉-语言模型
📋 核心要点
- 现有视觉-语言基准测试侧重于性能评估,缺乏对模型内部处理机制的深入理解。
- 本文借鉴语言模型可解释性方法,深入分析CLIP模型文本编码器如何处理否定概念。
- 通过实验,定位了CLIP中处理否定的模块,并分析了注意力头的作用,揭示了模型内部机制。
📝 摘要(中文)
本文旨在研究预训练视觉-语言(VL)模型对语言理解的能力,特别是对否定概念的处理。研究基于VALSE基准测试中的存在性任务,评估模型对否定的理解。与以往侧重于性能评估的VL基准测试不同,本文着重于揭示模型内部的处理机制。通过深入分析CLIP模型文本编码器的行为,定位处理否定概念的特定部分,并分析注意力头在其中的作用。主要贡献包括:将语言模型可解释性方法应用于多模态模型和任务;深入了解CLIP在VALSE存在性任务中处理否定概念的方式;以及强调VALSE数据集作为语言理解基准测试的局限性。
🔬 方法详解
问题定义:论文旨在研究CLIP模型如何理解和处理否定概念。现有视觉-语言模型基准测试主要关注性能评估,缺乏对模型内部处理机制的深入理解,难以解释模型做出特定决策的原因。VALSE数据集虽然可以测试模型对否定的理解,但其作为基准测试存在局限性。
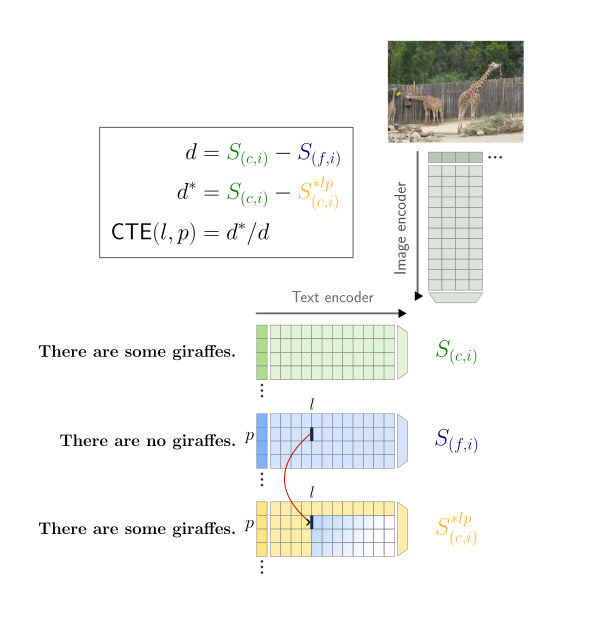
核心思路:论文的核心思路是借鉴语言模型可解释性领域的方法,例如因果追踪,将其应用于多模态模型,以解释CLIP模型在处理否定概念时的行为。通过分析CLIP文本编码器的内部结构,定位负责处理否定概念的特定模块,并分析注意力头在其中的作用。
技术框架:论文主要关注CLIP模型的文本编码器部分。研究流程包括:首先,使用VALSE数据集构建测试用例,评估CLIP模型对否定概念的理解能力。然后,利用因果追踪等可解释性方法,分析文本编码器中不同层和注意力头对模型输出的影响。最后,通过可视化和定量分析,揭示模型处理否定概念的内部机制。
关键创新:论文的关键创新在于将语言模型可解释性方法成功应用于多模态模型,并深入分析了CLIP模型处理否定概念的内部机制。这为理解多模态模型的行为提供了新的视角,并为改进模型的设计提供了指导。
关键设计:论文使用了因果追踪方法来分析CLIP模型文本编码器中不同层和注意力头对模型输出的影响。具体来说,通过干预(例如,替换或删除)特定层或注意力头的输出,观察模型性能的变化,从而确定其在处理否定概念中的作用。论文还对VALSE数据集进行了分析,指出了其作为语言理解基准测试的局限性。
🖼️ 关键图片


📊 实验亮点
论文通过实验,定位了CLIP模型文本编码器中负责处理否定概念的特定部分,并分析了注意力头在其中的作用。研究表明,某些特定的注意力头在处理否定概念中起着关键作用。此外,论文还指出了VALSE数据集作为语言理解基准测试的局限性,为未来基准测试的设计提供了参考。
🎯 应用场景
该研究成果可应用于提升视觉-语言模型的鲁棒性和可解释性,例如在图像检索、视觉问答等任务中,提高模型对复杂语言指令的理解能力。此外,该研究方法可以推广到其他多模态模型,帮助研究人员更好地理解和改进这些模型。
📄 摘要(原文)
Various benchmarks have been proposed to test linguistic understanding in pre-trained vision \& language (VL) models. Here we build on the existence task from the VALSE benchmark (Parcalabescu et al, 2022) which we use to test models' understanding of negation, a particularly interesting issue for multimodal models. However, while such VL benchmarks are useful for measuring model performance, they do not reveal anything about the internal processes through which these models arrive at their outputs in such visio-linguistic tasks. We take inspiration from the growing literature on model interpretability to explain the behaviour of VL models on the understanding of negation. Specifically, we approach these questions through an in-depth analysis of the text encoder in CLIP (Radford et al, 2021), a highly influential VL model. We localise parts of the encoder that process negation and analyse the role of attention heads in this task. Our contributions are threefold. We demonstrate how methods from the language model interpretability literature (such as causal tracing) can be translated to multimodal models and tasks; we provide concrete insights into how CLIP processes negation on the VALSE existence task; and we highlight inherent limitations in the VALSE dataset as a benchmark for linguistic understanding.