Minimizing PLM-Based Few-Shot Intent Detectors
作者: Haode Zhang, Albert Y. S. Lam, Xiao-Ming Wu
分类: cs.CL
发布日期: 2024-07-13 (更新: 2024-09-15)
💡 一句话要点
提出V-Prune等方法,在保证性能下显著压缩PLM小样本意图检测器。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小样本学习 意图检测 模型压缩 知识蒸馏 数据增强 预训练语言模型 词汇表剪枝
📋 核心要点
- 基于PLM的意图检测器虽然有效,但模型体积大,难以在移动设备等资源受限环境部署。
- 论文核心在于结合数据增强、知识蒸馏和词汇表剪枝,在压缩模型的同时保持检测性能。
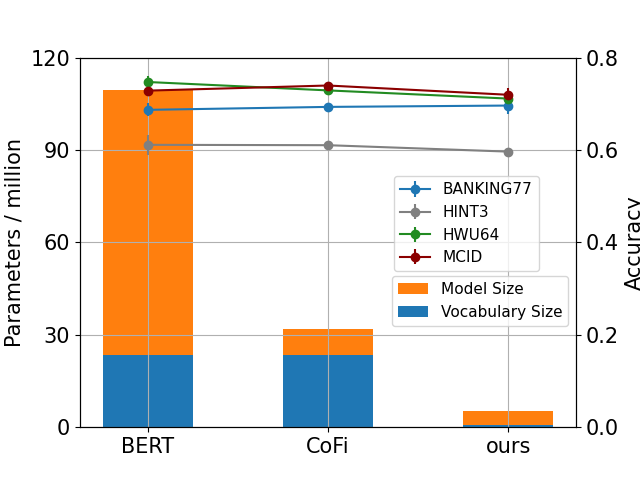
- 实验表明,该方法在四个数据集上实现了21倍的模型压缩,且性能几乎没有下降。
📝 摘要(中文)
本文旨在解决基于预训练语言模型(PLM)的小样本意图检测器在资源受限环境(如移动设备)部署时模型体积过大的问题。研究采用数据增强、知识蒸馏等技术来最小化模型尺寸。具体而言,利用大型语言模型(LLM)进行数据增强,采用先进的模型压缩方法进行知识蒸馏,并设计了一种名为V-Prune的词汇表剪枝机制。实验结果表明,这些方法能够在四个真实世界的基准数据集上,在几乎不损失性能的前提下,成功地将模型内存使用量(包括Transformer和词汇表)压缩21倍。
🔬 方法详解
问题定义:现有基于预训练语言模型(PLM)的小样本意图检测器,虽然在准确率上表现良好,但模型体积庞大,计算复杂度高,难以部署在资源受限的设备上,例如移动端。因此,如何在保证意图检测性能的前提下,减小模型体积,是本文要解决的核心问题。现有模型压缩方法在小样本意图检测任务上的效果还有待提升。
核心思路:本文的核心思路是结合多种模型压缩技术,包括数据增强、知识蒸馏和词汇表剪枝,协同作用以达到最佳的压缩效果。数据增强用于提升小样本场景下的模型泛化能力,知识蒸馏将大型模型的知识迁移到小型模型,词汇表剪枝进一步减少模型参数量。这种多管齐下的策略旨在在压缩模型的同时,尽可能地保留模型的性能。
技术框架:整体框架包含三个主要阶段:1) 数据增强阶段:利用大型语言模型(LLM)生成额外的训练数据,以缓解小样本学习带来的数据稀疏问题。2) 知识蒸馏阶段:使用压缩算法将大型预训练语言模型的知识迁移到小型模型中。3) 词汇表剪枝阶段:通过V-Prune算法,移除对意图检测任务不重要的词汇,进一步减小模型体积。
关键创新:论文的关键创新在于V-Prune词汇表剪枝机制。与传统的词汇表剪枝方法不同,V-Prune算法更加关注意图检测任务的特点,能够更有效地识别和移除冗余词汇,从而在保证性能的前提下,实现更高的压缩率。此外,将数据增强、知识蒸馏和词汇表剪枝三种技术有效结合,协同优化,也是一个创新点。
关键设计:在数据增强阶段,使用了Prompt工程来指导LLM生成高质量的增强数据。在知识蒸馏阶段,采用了先进的压缩算法,例如结构化剪枝或量化。V-Prune算法的具体实现细节包括:首先,计算每个词汇对意图检测任务的重要性得分;然后,根据得分对词汇进行排序;最后,移除得分较低的词汇。重要性得分的计算方式未知,论文中可能未详细说明。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在四个真实世界的基准数据集上,实现了高达21倍的模型压缩率,同时意图检测的准确率几乎没有下降。这表明该方法能够在保证性能的前提下,显著减小模型体积,使其更适合部署在资源受限的环境中。具体的性能数据和对比基线未知,需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于智能手机、智能家居设备、可穿戴设备等资源受限的场景中,提升这些设备上意图识别的效率和用户体验。例如,可以用于离线语音助手、智能客服等应用,在本地设备上快速准确地识别用户意图,保护用户隐私。
📄 摘要(原文)
Recent research has demonstrated the feasibility of training efficient intent detectors based on pre-trained language model~(PLM) with limited labeled data. However, deploying these detectors in resource-constrained environments such as mobile devices poses challenges due to their large sizes. In this work, we aim to address this issue by exploring techniques to minimize the size of PLM-based intent detectors trained with few-shot data. Specifically, we utilize large language models (LLMs) for data augmentation, employ a cutting-edge model compression method for knowledge distillation, and devise a vocabulary pruning mechanism called V-Prune. Through these approaches, we successfully achieve a compression ratio of 21 in model memory usage, including both Transformer and the vocabulary, while maintaining almost identical performance levels on four real-world benchmarks.