A Survey on Symbolic Knowledge Distillation of Large Language Models
作者: Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song
分类: cs.CL, cs.LG
发布日期: 2024-07-12
备注: 21 pages, 7 figures
💡 一句话要点
综述论文:探索大语言模型中符号知识蒸馏方法与应用
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识蒸馏 符号知识 可解释性 模型压缩 人工智能 知识表示
📋 核心要点
- 现有大语言模型知识蕴含复杂且隐式,难以直接应用和解释,限制了其在资源受限场景下的部署。
- 核心思想是将大语言模型中的知识提炼成更显式的符号形式,提升模型的可解释性、效率和适用性。
- 综述总结了现有符号知识蒸馏方法,分析了其在提高模型透明度和功能方面的作用,并指出了未来研究方向。
📝 摘要(中文)
本文深入研究了大语言模型(LLM)中新兴且关键的符号知识蒸馏领域。随着诸如GPT-3和BERT等LLM在规模和复杂性上不断扩展,如何有效利用它们所包含的广泛知识变得至关重要。本综述侧重于将这些模型中复杂的、通常是隐式的知识提炼成更具符号化、显式形式的过程。这种转换对于提高LLM的可解释性、效率和适用性至关重要。我们根据方法和应用对现有研究进行分类,重点关注如何使用符号知识蒸馏来提高更小、更高效的人工智能(AI)模型的透明度和功能。本综述讨论了核心挑战,包括以易于理解的格式保持知识的深度,并探讨了该领域中已开发的各种方法和技术。我们指出了当前研究中的差距以及未来发展的潜在机会。本综述旨在全面概述LLM中的符号知识蒸馏,突出其在迈向更易于访问和高效的AI系统中的重要性。
🔬 方法详解
问题定义:论文旨在解决如何将大型语言模型(LLM)中蕴含的复杂、隐式的知识有效地提取并转化为更易于理解和利用的符号化知识的问题。现有方法通常难以在知识蒸馏过程中保持知识的深度,并且缺乏对蒸馏后模型的透明度和可解释性的有效提升。
核心思路:论文的核心思路是通过符号知识蒸馏,将LLM中复杂的知识提炼成更显式的符号表示,例如规则、逻辑表达式或知识图谱等。这种转换旨在提高模型的可解释性、效率和适用性,使得小型模型能够更好地理解和利用LLM的知识。
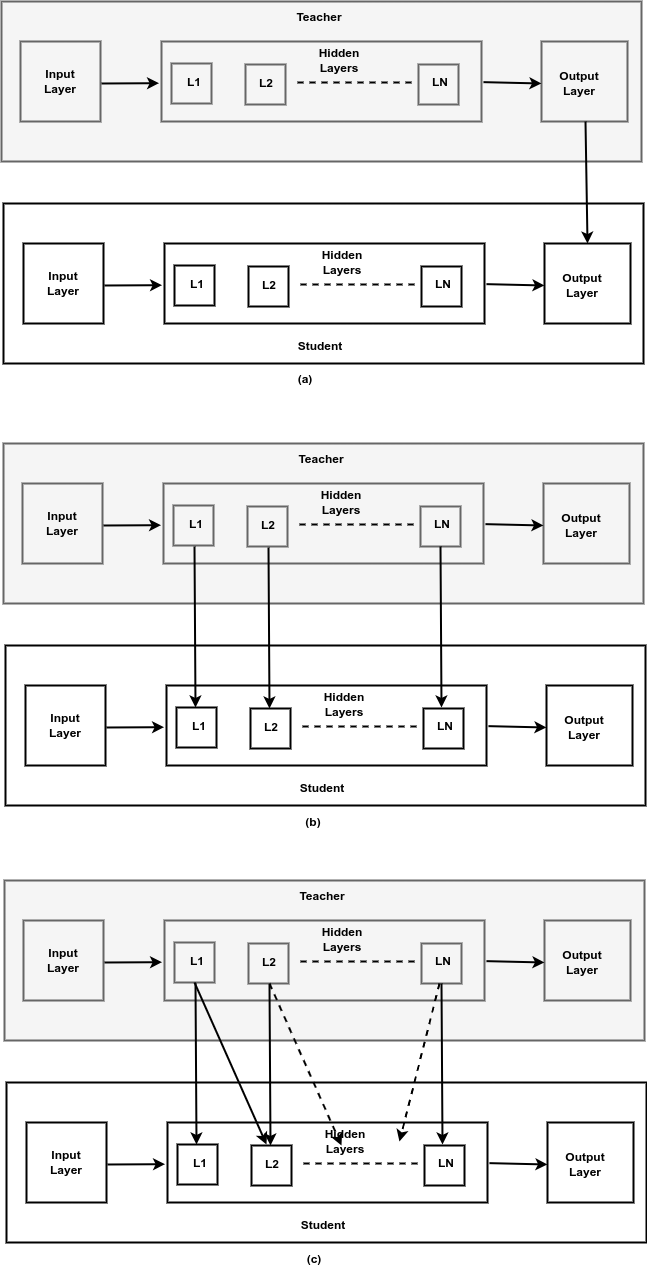
技术框架:该综述论文对现有研究进行了分类,主要围绕方法论和应用两个方面展开。方法论方面,关注不同的符号知识表示方法和蒸馏技术;应用方面,则考察符号知识蒸馏在不同任务中的应用效果。整体流程包括:1) 知识抽取:从LLM中提取知识;2) 符号化表示:将提取的知识转化为符号形式;3) 知识蒸馏:将符号化知识迁移到小型模型。
关键创新:该综述的关键创新在于系统性地梳理和总结了LLM中符号知识蒸馏的研究进展,并指出了当前研究的差距和未来发展的潜在方向。它强调了符号知识蒸馏在提高模型可解释性和效率方面的重要性,并为未来的研究提供了指导。
关键设计:由于是综述论文,没有具体的参数设置、损失函数或网络结构。但综述中讨论了各种符号知识表示方法(例如,规则、逻辑表达式、知识图谱)和蒸馏技术(例如,基于逻辑的蒸馏、基于规则的蒸馏),这些都是符号知识蒸馏中的关键设计选择。
🖼️ 关键图片


📊 实验亮点
作为一篇综述,其亮点在于对现有符号知识蒸馏方法进行了系统性的总结和分类,并指出了当前研究的不足和未来研究方向。它强调了符号知识蒸馏在提高模型可解释性和效率方面的重要性,并为未来的研究提供了指导。虽然没有具体的实验数据,但它为研究人员提供了一个全面的视角来了解该领域的研究进展。
🎯 应用场景
该研究具有广泛的应用前景,包括但不限于:开发更易于理解和信任的AI系统,提升AI在医疗、金融等高风险领域的应用,以及构建更高效、更轻量级的AI模型,使其能够在资源受限的环境中部署。此外,符号知识蒸馏还有助于提高AI系统的可解释性和可追溯性,从而增强用户对AI的信任。
📄 摘要(原文)
This survey paper delves into the emerging and critical area of symbolic knowledge distillation in Large Language Models (LLMs). As LLMs like Generative Pre-trained Transformer-3 (GPT-3) and Bidirectional Encoder Representations from Transformers (BERT) continue to expand in scale and complexity, the challenge of effectively harnessing their extensive knowledge becomes paramount. This survey concentrates on the process of distilling the intricate, often implicit knowledge contained within these models into a more symbolic, explicit form. This transformation is crucial for enhancing the interpretability, efficiency, and applicability of LLMs. We categorize the existing research based on methodologies and applications, focusing on how symbolic knowledge distillation can be used to improve the transparency and functionality of smaller, more efficient Artificial Intelligence (AI) models. The survey discusses the core challenges, including maintaining the depth of knowledge in a comprehensible format, and explores the various approaches and techniques that have been developed in this field. We identify gaps in current research and potential opportunities for future advancements. This survey aims to provide a comprehensive overview of symbolic knowledge distillation in LLMs, spotlighting its significance in the progression towards more accessible and efficient AI systems.