Pronunciation Assessment with Multi-modal Large Language Models
作者: Kaiqi Fu, Linkai Peng, Nan Yang, Shuran Zhou
分类: cs.CL, eess.AS
发布日期: 2024-07-12 (更新: 2024-07-18)
💡 一句话要点
提出基于多模态大语言模型的发音评估系统,提升语音学习的智能化水平。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 发音评估 多模态学习 大语言模型 语音编码 适配器层
📋 核心要点
- 现有发音评估系统在捕捉语音的细微差别和上下文信息方面存在不足,难以提供个性化和有效的反馈。
- 该论文提出利用多模态大语言模型,通过语音编码器和适配器层,将语音特征与文本嵌入对齐,实现更准确的发音评估。
- 实验结果表明,该方法在Speechocean762数据集上取得了有竞争力的结果,证明了其在发音评估任务中的有效性。
📝 摘要(中文)
本文提出了一种基于大语言模型(LLM)的发音评估系统。大语言模型以其强大的对话能力而闻名,被广泛认为是教育领域,特别是语言学习自动化智能教学系统中的优秀工具。受LLM在文本相关评分任务中积极影响的启发,我们提出了一种基于LLM的评分系统。具体来说,语音编码器首先将学习者的语音映射到上下文特征。然后,适配器层转换这些特征,使其与潜在空间中的文本嵌入对齐。评估任务特定的前缀和提示文本被嵌入并与模态适配器层生成的特征连接,使LLM能够预测准确性和流畅性得分。实验表明,所提出的评分系统在Speechocean762数据集上取得了与基线相比具有竞争力的结果。此外,我们还进行了消融研究,以更好地理解提示文本和训练策略在所提出的评分系统中的贡献。
🔬 方法详解
问题定义:论文旨在解决自动发音评估问题,现有方法通常依赖于传统的声学模型或浅层机器学习方法,难以充分利用语音中的上下文信息,并且泛化能力有限。此外,如何有效地融合语音和文本信息,并利用大语言模型的强大能力进行评估也是一个挑战。
核心思路:论文的核心思路是将语音特征映射到与文本嵌入相同的潜在空间,从而利用大语言模型强大的文本理解和生成能力进行发音评估。通过适配器层,将语音编码器的输出与文本嵌入对齐,使得大语言模型能够更好地理解语音内容,并给出准确的评估结果。
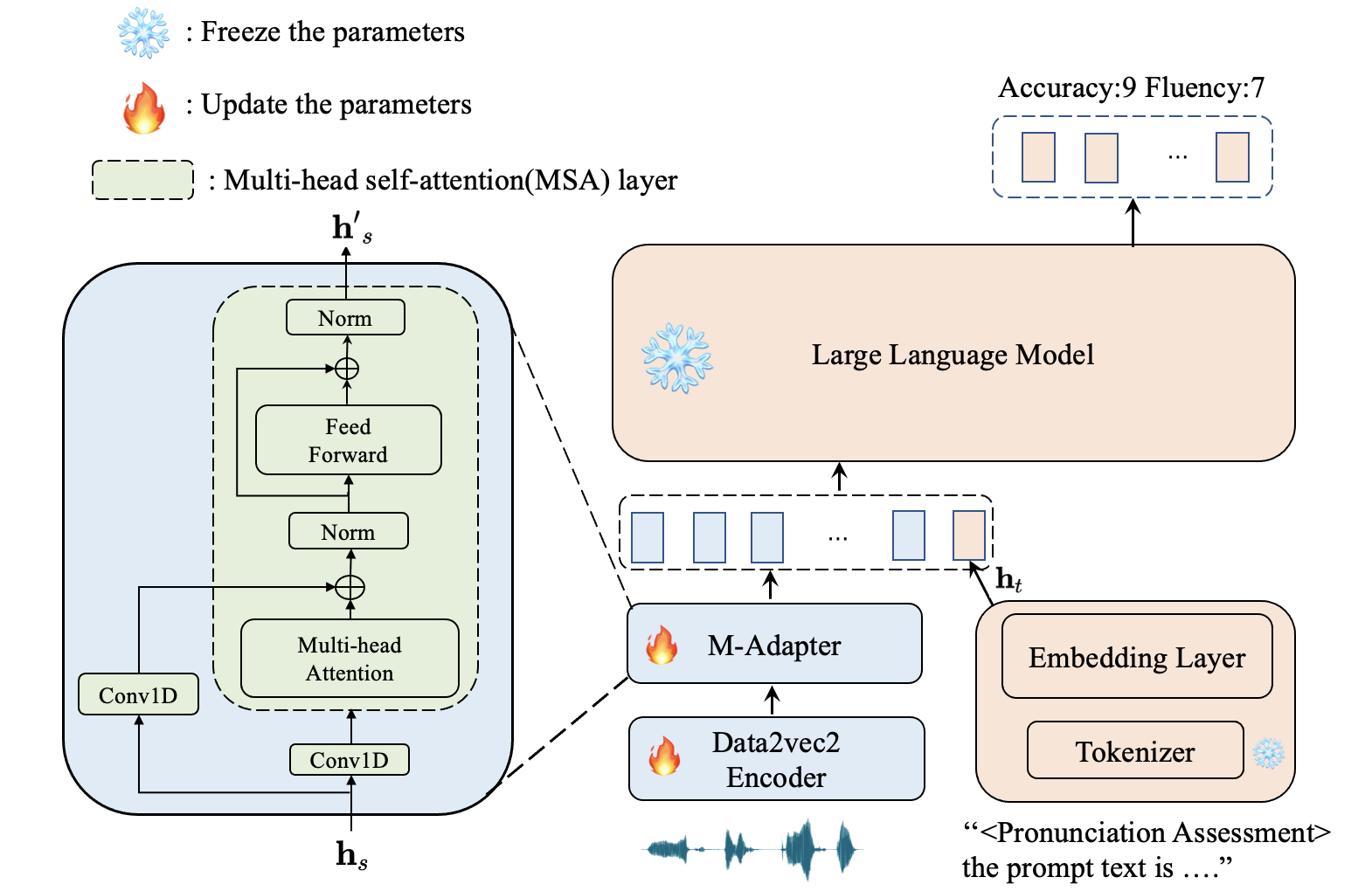
技术框架:该系统主要包含以下几个模块:1) 语音编码器:将学习者的语音转换为上下文特征。2) 适配器层:将语音特征转换为与文本嵌入对齐的表示。3) 提示和前缀嵌入:将评估任务相关的提示文本和前缀信息嵌入到特征中。4) 大语言模型:根据融合后的特征,预测准确性和流畅性得分。整体流程是:语音输入 -> 语音编码器 -> 适配器层 -> 提示/前缀嵌入 -> 大语言模型 -> 发音评估得分。
关键创新:该论文的关键创新在于利用适配器层将语音特征与文本嵌入对齐,从而能够有效地利用大语言模型进行发音评估。这种方法避免了直接训练端到端的语音评估模型,而是利用了预训练大语言模型的知识,提高了模型的泛化能力和鲁棒性。
关键设计:适配器层的具体结构未知,但其目标是将语音特征映射到与文本嵌入相同的潜在空间。提示文本的设计对于引导大语言模型进行发音评估至关重要,需要仔细设计以确保模型能够理解评估任务的要求。损失函数的设计也需要考虑准确性和流畅性得分的平衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的评分系统在Speechocean762数据集上取得了与基线相比具有竞争力的结果。具体的性能数据和提升幅度未知,但论文强调了该方法在发音评估任务中的有效性。消融研究表明,提示文本和训练策略对评分系统的性能有重要影响。
🎯 应用场景
该研究成果可应用于在线语言学习平台、智能语音助手等领域,为用户提供个性化的发音评估和反馈,辅助语言学习者提高口语水平。此外,该技术还可用于语音识别系统的错误诊断和语音合成系统的质量评估,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs), renowned for their powerful conversational abilities, are widely recognized as exceptional tools in the field of education, particularly in the context of automated intelligent instruction systems for language learning. In this paper, we propose a scoring system based on LLMs, motivated by their positive impact on text-related scoring tasks. Specifically, the speech encoder first maps the learner's speech into contextual features. The adapter layer then transforms these features to align with the text embedding in latent space. The assessment task-specific prefix and prompt text are embedded and concatenated with the features generated by the modality adapter layer, enabling the LLMs to predict accuracy and fluency scores. Our experiments demonstrate that the proposed scoring systems achieve competitive results compared to the baselines on the Speechocean762 datasets. Moreover, we also conducted an ablation study to better understand the contributions of the prompt text and training strategy in the proposed scoring system.