Stepwise Verification and Remediation of Student Reasoning Errors with Large Language Model Tutors
作者: Nico Daheim, Jakub Macina, Manu Kapur, Iryna Gurevych, Mrinmaya Sachan
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-07-12
备注: Preprint. Nico Daheim and Jakub Macina contributed equally. Code and dataset can be found under: https://github.com/eth-lre/verify-then-generate
💡 一句话要点
提出基于LLM导师的逐步验证与纠正框架,提升学生推理错误识别与反馈质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 智能辅导系统 错误识别 个性化教育 数学推理 逐步验证 反馈生成
📋 核心要点
- 现有大型语言模型在推理问题上表现出色,但在精准识别学生错误并提供针对性反馈方面存在不足。
- 该论文提出一种基于验证学生解题步骤的框架,通过错误定位来指导LLM生成更有效的反馈。
- 实验结果表明,该方法能显著提升LLM导师生成回复的准确性,并减少幻觉现象。
📝 摘要(中文)
大型语言模型(LLMs)为大规模提供高质量的个性化教育带来了机遇。一种有前景的方法是构建对话式辅导模型,为学生的问题解决提供支架。然而,即使现有的LLMs在解决推理问题方面表现良好,它们也很难精确地检测学生的错误并根据这些错误定制反馈。受到现实教学实践的启发,教师会识别学生的错误并根据错误定制反馈,我们专注于验证学生的解决方案,并展示了基于这种验证如何提高导师回复生成的整体质量。我们收集了一个包含1K个逐步数学推理链的数据集,其中教师标注了第一个错误步骤。实证表明,发现学生解决方案中的错误对当前模型来说具有挑战性。我们提出并评估了几种用于检测这些错误的验证器。通过自动和人工评估,我们表明学生解决方案验证器引导生成模型生成更有针对性的学生错误回复,与现有基线相比,这些回复更准确,幻觉更少。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在作为智能辅导系统时,难以准确识别学生在解题过程中的错误,并提供个性化、有针对性的反馈的问题。现有方法通常直接让LLM生成回复,缺乏对学生解题步骤的细致分析,导致反馈不够精准,甚至出现幻觉。
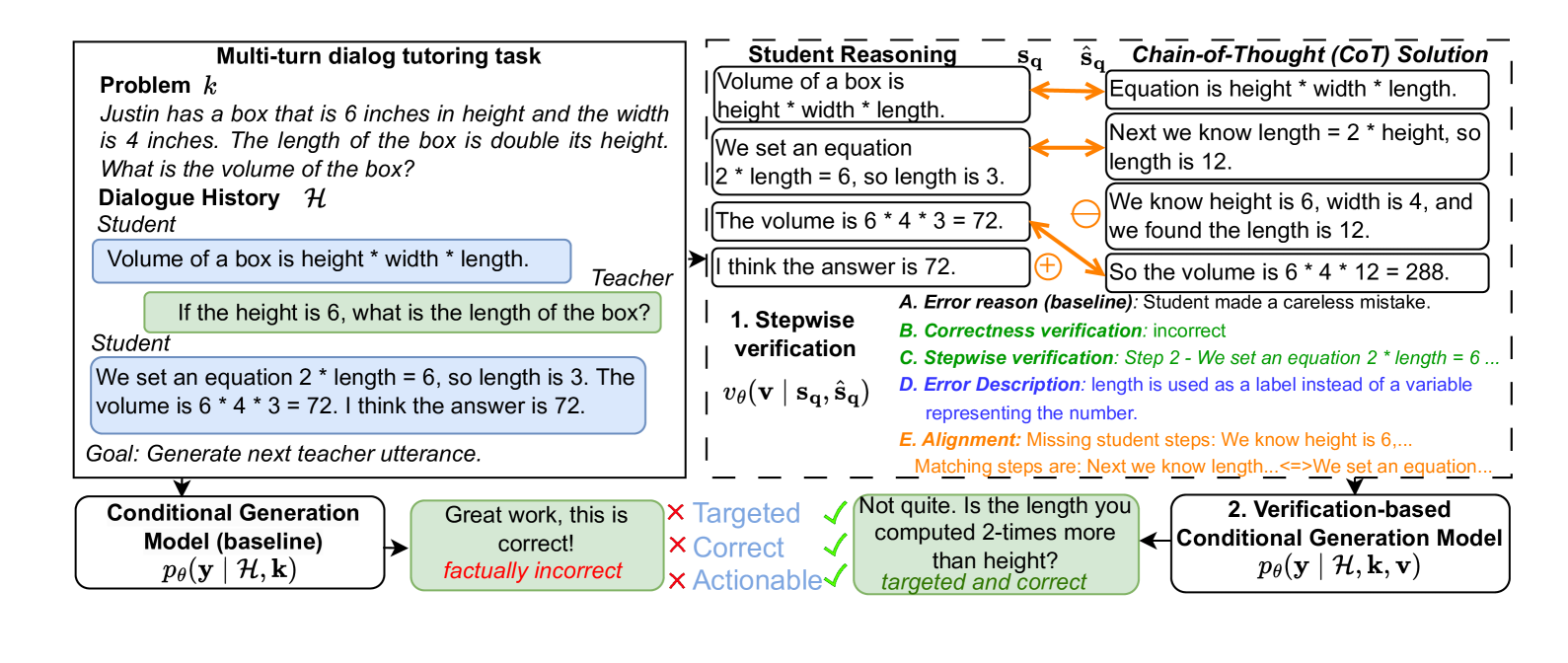
核心思路:论文的核心思路是借鉴真实教师的教学方式,首先对学生的解题步骤进行验证,找出错误发生的具体位置,然后基于错误信息生成针对性的反馈。通过将错误验证作为中间步骤,可以有效引导LLM关注学生解题过程中的薄弱环节,从而提供更有效的辅导。
技术框架:整体框架包含以下几个主要模块:1) 学生解题步骤输入;2) 错误验证器:用于逐步骤验证学生解题过程,判断每一步是否正确,并标记第一个错误步骤;3) 反馈生成器:基于错误验证器的输出,生成针对性的反馈;4) 评估模块:对生成的反馈进行自动和人工评估。
关键创新:该论文的关键创新在于引入了学生解题步骤的验证环节,并将验证结果作为生成反馈的依据。这种方法将复杂的反馈生成任务分解为错误定位和反馈生成两个子任务,降低了LLM的生成难度,提高了反馈的准确性和针对性。此外,论文还构建了一个包含错误标注的数学推理数据集,为相关研究提供了数据支持。
关键设计:论文设计了多种错误验证器,包括基于规则的验证器和基于LLM的验证器。反馈生成器采用prompt engineering的方式,将错误信息融入prompt中,引导LLM生成针对性的反馈。实验中,论文对比了不同验证器和反馈生成策略的效果,并进行了详细的消融实验。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该论文提出的方法在错误识别和反馈生成方面均优于现有基线方法。具体而言,基于验证器的反馈生成模型能够更准确地识别学生的错误,并生成更具针对性和实用性的反馈。人工评估结果显示,该方法生成的反馈更受学生欢迎,且幻觉现象明显减少。
🎯 应用场景
该研究成果可应用于智能教育平台、在线辅导系统等领域,为学生提供个性化的学习支持。通过精准识别学生的错误并提供针对性反馈,可以有效提升学生的学习效率和问题解决能力。未来,该技术有望扩展到其他学科和领域,实现更广泛的个性化教育。
📄 摘要(原文)
Large language models (LLMs) present an opportunity to scale high-quality personalized education to all. A promising approach towards this means is to build dialog tutoring models that scaffold students' problem-solving. However, even though existing LLMs perform well in solving reasoning questions, they struggle to precisely detect student's errors and tailor their feedback to these errors. Inspired by real-world teaching practice where teachers identify student errors and customize their response based on them, we focus on verifying student solutions and show how grounding to such verification improves the overall quality of tutor response generation. We collect a dataset of 1K stepwise math reasoning chains with the first error step annotated by teachers. We show empirically that finding the mistake in a student solution is challenging for current models. We propose and evaluate several verifiers for detecting these errors. Using both automatic and human evaluation we show that the student solution verifiers steer the generation model towards highly targeted responses to student errors which are more often correct with less hallucinations compared to existing baselines.