3M-Health: Multimodal Multi-Teacher Knowledge Distillation for Mental Health Detection
作者: Rina Carines Cabral, Siwen Luo, Josiah Poon, Soyeon Caren Han
分类: cs.CL
发布日期: 2024-07-12 (更新: 2024-08-08)
备注: Accepted at CIKM 2024; Code will be made available at https://github.com/adlnlp/3mhealth
期刊: CIKM '24 (2024) 152-162
💡 一句话要点
提出3M-Health模型,利用多模态多教师知识蒸馏进行心理健康检测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理健康检测 多模态学习 知识蒸馏 多教师模型 社交媒体分析
📋 核心要点
- 现有心理健康数据集主要为文本数据,忽略了人类理解复杂情况时使用的跨模态信息。
- 提出多模态多教师知识蒸馏模型(3M-Health),利用多个教师分别提取不同模态的特征。
- 实验验证表明,该模型能够有效提升心理健康分类的性能,优于传统方法。
📝 摘要(中文)
心理健康分类在当今社会至关重要,数字平台是监测个人福祉的关键来源。然而,现有的社交媒体心理健康数据集主要由纯文本样本组成,这可能限制了模型的有效性。考虑到人类利用跨模态信息来理解复杂情况,我们提出了一种新方法来解决当前方法的局限性。本文介绍了一种用于心理健康分类的多模态多教师知识蒸馏模型(3M-Health),该模型利用了跨模态人类理解的洞察力。与通常依赖简单连接来整合不同特征的传统方法不同,我们的模型解决了适当表示不同性质输入(例如,文本和声音)的挑战。为了减轻将所有特征集成到单个模型中相关的计算复杂性,我们采用了一种多模态多教师架构。通过将学习过程分配给多个教师,每个教师专门研究特定的特征提取方面,我们提高了整体心理健康分类性能。通过实验验证,我们证明了我们的模型在实现改进的性能方面的有效性。
🔬 方法详解
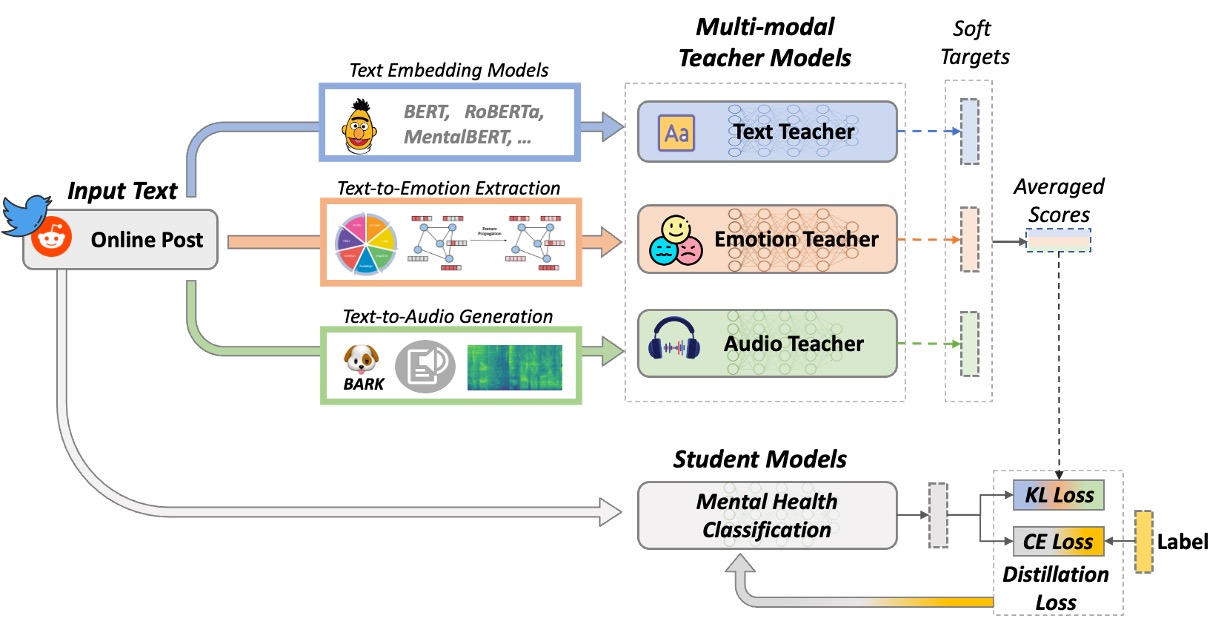
问题定义:现有心理健康检测模型主要依赖于文本数据,忽略了语音、图像等其他模态的信息,导致模型对用户心理状态的理解不够全面。此外,直接将多模态特征融合到一个模型中会带来巨大的计算复杂度,限制了模型的应用。
核心思路:论文的核心思路是利用多模态信息,并采用知识蒸馏的方法来解决计算复杂度问题。通过训练多个“教师”模型,每个模型专注于提取特定模态的特征,然后将这些教师模型的知识“蒸馏”到一个更小的“学生”模型中,从而在保证性能的同时降低计算成本。
技术框架:3M-Health模型包含多个教师模型和一个学生模型。每个教师模型负责处理一种模态的数据(例如,文本、音频)。教师模型可以是预训练的模型,也可以是专门为该任务训练的模型。学生模型接收来自所有教师模型的知识,并学习如何将这些知识融合起来进行心理健康分类。整个训练过程采用知识蒸馏的方法,即学生模型的目标是模仿教师模型的输出。
关键创新:该模型的主要创新在于采用了多模态多教师知识蒸馏的框架。与传统的单模态模型相比,该模型能够利用更多的信息来提高分类性能。与传统的单教师知识蒸馏相比,该模型能够更好地处理多模态数据,并降低计算复杂度。
关键设计:教师模型的选择和训练是关键。论文中可能使用了预训练的BERT模型作为文本教师模型,并使用其他预训练模型或专门训练的模型作为音频教师模型。学生模型的结构也需要仔细设计,以便能够有效地融合来自不同教师模型的知识。损失函数通常包括分类损失和知识蒸馏损失,知识蒸馏损失用于衡量学生模型与教师模型输出之间的差异。具体的参数设置(如学习率、batch size等)未知,需要在实验中进行调整。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了3M-Health模型的有效性,结果表明该模型在心理健康分类任务上取得了比传统方法更好的性能。具体的性能提升幅度未知,但摘要中明确指出模型实现了“improved performance”。具体的对比基线模型和数据集信息未知。
🎯 应用场景
该研究成果可应用于在线心理健康咨询、社交媒体平台的情绪监测、智能客服等领域。通过更准确地识别用户的心理状态,可以提供个性化的心理健康支持和服务,及早发现潜在的心理健康问题,并进行干预,具有重要的社会价值和应用前景。
📄 摘要(原文)
The significance of mental health classification is paramount in contemporary society, where digital platforms serve as crucial sources for monitoring individuals' well-being. However, existing social media mental health datasets primarily consist of text-only samples, potentially limiting the efficacy of models trained on such data. Recognising that humans utilise cross-modal information to comprehend complex situations or issues, we present a novel approach to address the limitations of current methodologies. In this work, we introduce a Multimodal and Multi-Teacher Knowledge Distillation model for Mental Health Classification, leveraging insights from cross-modal human understanding. Unlike conventional approaches that often rely on simple concatenation to integrate diverse features, our model addresses the challenge of appropriately representing inputs of varying natures (e.g., texts and sounds). To mitigate the computational complexity associated with integrating all features into a single model, we employ a multimodal and multi-teacher architecture. By distributing the learning process across multiple teachers, each specialising in a particular feature extraction aspect, we enhance the overall mental health classification performance. Through experimental validation, we demonstrate the efficacy of our model in achieving improved performance.