One Stone, Four Birds: A Comprehensive Solution for QA System Using Supervised Contrastive Learning
作者: Bo Wang, Tsunenori Mine
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-07-12 (更新: 2024-10-25)
备注: 16 pages, updated to the accepted version
DOI: 10.1109/ACCESS.2024.3469163
💡 一句话要点
提出基于监督对比学习的QA系统方案,提升鲁棒性和效率,实现多任务统一。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 问答系统 监督对比学习 意图分类 域外检测 持续学习 表征学习 预训练语言模型
📋 核心要点
- 现有QA系统在功能和训练效率上存在不足,难以同时处理意图分类、域外检测等多种任务。
- 论文提出基于监督对比学习的统一表征学习方法,构建类内紧凑、类间分散的特征空间。
- 该方法在多个QA任务上取得了新的state-of-the-art性能,并显著提升了模型效率。
📝 摘要(中文)
本文提出了一种新颖而全面的解决方案,旨在通过监督对比学习(SCL)来增强问答(QA)系统的鲁棒性和效率。借助预训练语言模型,训练高性能的QA系统已变得简单,仅需少量数据和简单的微调即可。然而,尽管最近取得了进展,现有的QA系统在功能和训练效率方面仍然存在显著缺陷。我们通过定义四个关键任务来解决功能问题:用户输入意图分类、域外输入检测、新意图发现和持续学习。然后,我们利用统一的基于SCL的表征学习方法来有效地构建类内紧凑和类间分散的特征空间,从而促进已知意图分类和未知意图检测与发现。因此,通过对下游任务进行最少的额外调整,我们的方法显著提高了模型效率,并在所有任务中实现了新的最先进性能。
🔬 方法详解
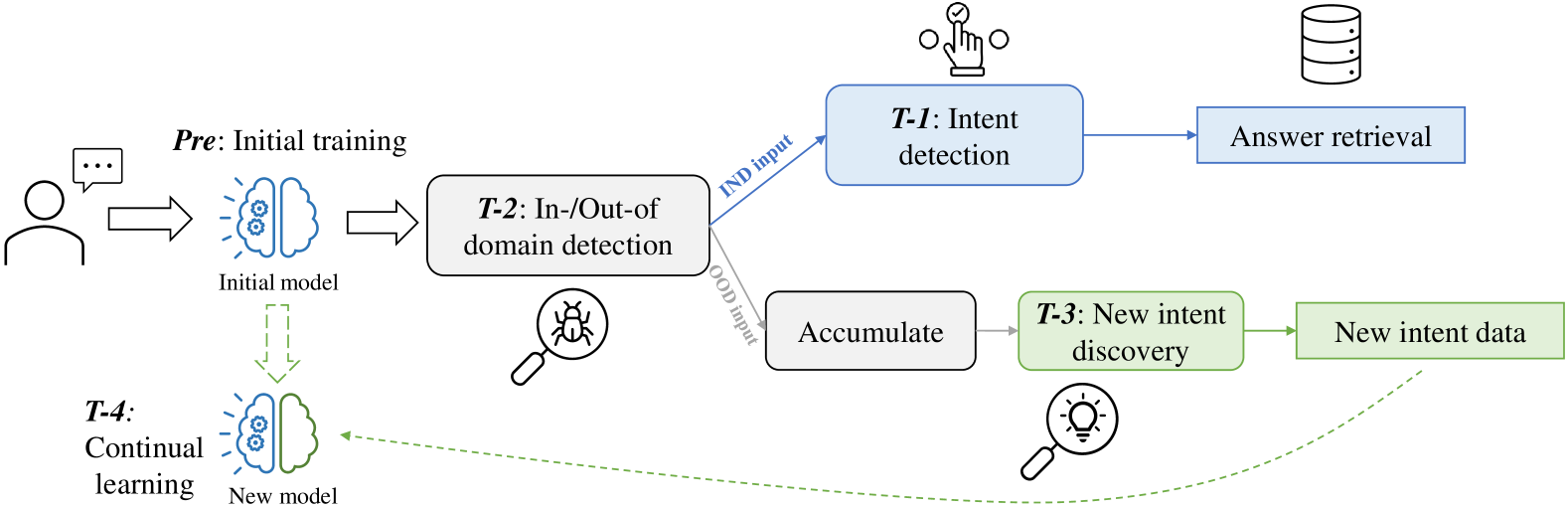
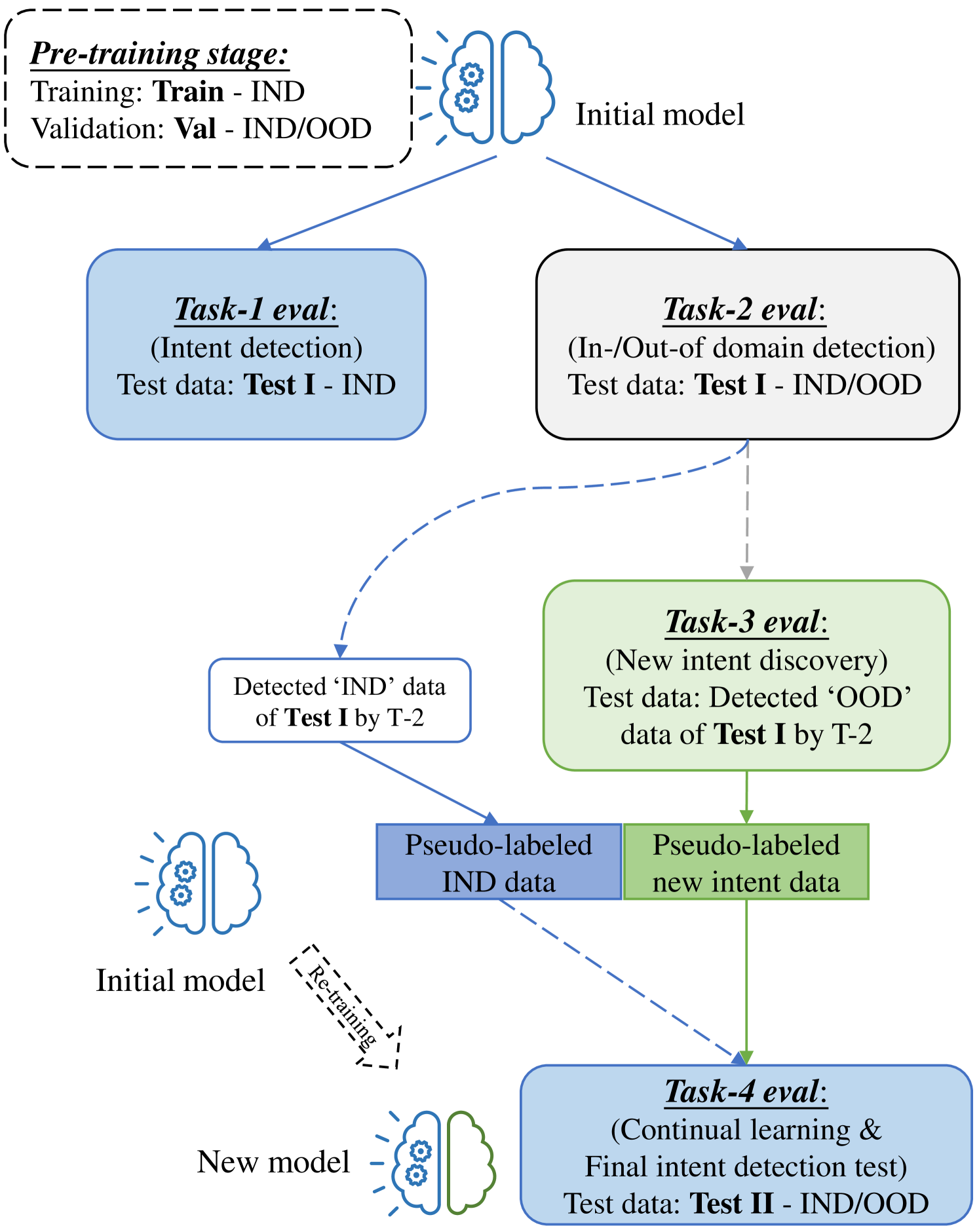
问题定义:现有的问答系统虽然可以通过预训练语言模型进行微调,但仍然存在功能缺陷和训练效率问题。具体来说,系统难以同时处理用户输入意图分类、域外输入检测、新意图发现和持续学习等多个任务。这些任务通常需要不同的模型或训练策略,导致系统复杂且效率低下。
核心思路:论文的核心思路是利用监督对比学习(SCL)来学习一个统一的特征表示空间,使得相同意图的样本在特征空间中彼此靠近(类内紧凑),而不同意图的样本彼此远离(类间分散)。通过这种方式,可以更容易地区分不同的意图,并检测出域外输入和新意图。
技术框架:整体框架包含一个预训练语言模型(例如BERT)作为编码器,以及一个基于监督对比学习的训练目标。首先,使用预训练语言模型将输入问题编码为特征向量。然后,使用监督对比学习损失函数来训练模型,使得相同意图的问题的特征向量尽可能接近,而不同意图的问题的特征向量尽可能远离。在推理阶段,可以使用学习到的特征向量进行意图分类、域外检测和新意图发现。
关键创新:最重要的创新点在于将监督对比学习应用于QA系统的多任务学习。与传统的交叉熵损失函数相比,监督对比学习能够更好地学习到具有区分性的特征表示,从而提高模型在各种QA任务上的性能。此外,该方法使用统一的框架来处理多个任务,简化了系统的设计和训练过程。
关键设计:关键的设计包括选择合适的预训练语言模型作为编码器,以及设计有效的监督对比学习损失函数。损失函数通常包含一个温度参数,用于控制特征向量之间的距离。此外,还可以使用不同的采样策略来选择用于对比学习的样本,例如hard negative mining。
🖼️ 关键图片

📊 实验亮点
该方法在四个关键任务(用户输入意图分类、域外输入检测、新意图发现和持续学习)上均取得了state-of-the-art的性能。通过监督对比学习,模型能够更有效地学习到具有区分性的特征表示,从而显著提升了模型在各种QA任务上的性能和效率。
🎯 应用场景
该研究成果可广泛应用于智能客服、聊天机器人、搜索引擎等领域。通过提升QA系统的鲁棒性和效率,可以更好地理解用户意图,提供更准确的答案,并及时发现和处理新的用户需求。该方法还有助于构建更加智能和自适应的对话系统。
📄 摘要(原文)
This paper presents a novel and comprehensive solution to enhance both the robustness and efficiency of question answering (QA) systems through supervised contrastive learning (SCL). Training a high-performance QA system has become straightforward with pre-trained language models, requiring only a small amount of data and simple fine-tuning. However, despite recent advances, existing QA systems still exhibit significant deficiencies in functionality and training efficiency. We address the functionality issue by defining four key tasks: user input intent classification, out-of-domain input detection, new intent discovery, and continual learning. We then leverage a unified SCL-based representation learning method to efficiently build an intra-class compact and inter-class scattered feature space, facilitating both known intent classification and unknown intent detection and discovery. Consequently, with minimal additional tuning on downstream tasks, our approach significantly improves model efficiency and achieves new state-of-the-art performance across all tasks.