Robustness of Large Language Models to Perturbations in Text
作者: Ayush Singh, Navpreet Singh, Shubham Vatsal
分类: cs.CL, cs.AI
发布日期: 2024-07-12 (更新: 2025-10-07)
备注: 8 pages, 1 figure, 6 tables, updated with results also from GPT-4, LLaMa-3
💡 一句话要点
研究表明大型语言模型对文本扰动具有较强的鲁棒性,并在语法纠错和词汇语义变化任务上取得新突破。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本鲁棒性 文本扰动 语法纠错 词汇语义变化 噪声数据 自然语言处理
📋 核心要点
- 现有NLP系统依赖于干净数据集,但在实际应用中数据常含噪声,这给LLM的鲁棒性带来了挑战。
- 该研究通过引入噪声评估LLM的抗干扰能力,发现生成式LLM对文本扰动具有较强的鲁棒性。
- 实验表明,LLM在语法纠错和词汇语义变化等真实场景任务中表现出色,并超越了现有技术水平。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)在面对文本形态变异时的鲁棒性。与大多数自然语言处理(NLP)系统依赖于干净数据集的假设不同,现实世界的数据往往包含噪声。本文通过在各种数据集上引入不同程度的噪声,系统地评估了LLMs对原始文本的抗干扰能力。研究结果表明,与对噪声文本敏感的BERT或RoBERTa等预训练模型不同,生成式LLMs对文本中的噪声扰动具有相当强的鲁棒性。此外,本文还在多个真实世界的基准测试中验证了LLMs的鲁棒性,这些基准测试模拟了常见的错误。通过最少的提示,LLMs在语法错误纠正(GEC)和词汇语义变化(LSC)基准任务上取得了新的state-of-the-art。为了促进未来的研究,本文还发布了一个由人工标注的数据集,其中包含了人类对LLM与人工校正输出的偏好,以及复现结果的代码。
🔬 方法详解
问题定义:现有自然语言处理系统通常假设输入数据是干净的,但在实际应用中,文本数据往往包含各种噪声,例如拼写错误、语法错误、词汇使用不当等。预训练模型如BERT和RoBERTa对这些噪声非常敏感,导致性能下降。因此,如何提高模型在噪声环境下的鲁棒性是一个重要的问题。
核心思路:本文的核心思路是系统性地评估大型语言模型(LLMs)在面对不同类型和不同程度的文本扰动时的性能表现。通过人工引入噪声,模拟真实世界中可能出现的各种错误,并观察LLMs在这些噪声数据上的表现,从而评估其鲁棒性。同时,利用LLMs强大的生成能力,直接在真实世界的任务上进行测试,验证其在实际应用中的效果。
技术框架:该研究的技术框架主要包括以下几个步骤:1.构建包含多种数据集的测试集;2.通过人工方式向测试集引入不同类型和不同程度的噪声,生成带噪声的测试集;3.使用LLMs在原始测试集和带噪声的测试集上进行测试,评估其性能;4.在真实世界的基准测试(如语法错误纠正和词汇语义变化)上评估LLMs的性能;5.收集人类对LLM和人工校正输出的偏好数据,用于进一步分析。
关键创新:本文的关键创新在于:1.系统性地研究了LLMs在面对文本扰动时的鲁棒性,揭示了LLMs与传统预训练模型在鲁棒性上的差异;2.通过在真实世界的基准测试上进行评估,验证了LLMs在实际应用中的有效性;3.发布了一个包含人类偏好标注的数据集,为未来的研究提供了宝贵的资源。
关键设计:在实验设计方面,本文考虑了多种类型的文本扰动,包括拼写错误、语法错误、词汇替换等。噪声的程度也进行了控制,以模拟不同程度的噪声环境。在评估指标方面,使用了准确率、F1值等常用指标。在提示工程方面,使用了最少的提示,以避免过度干预LLMs的生成过程。
🖼️ 关键图片
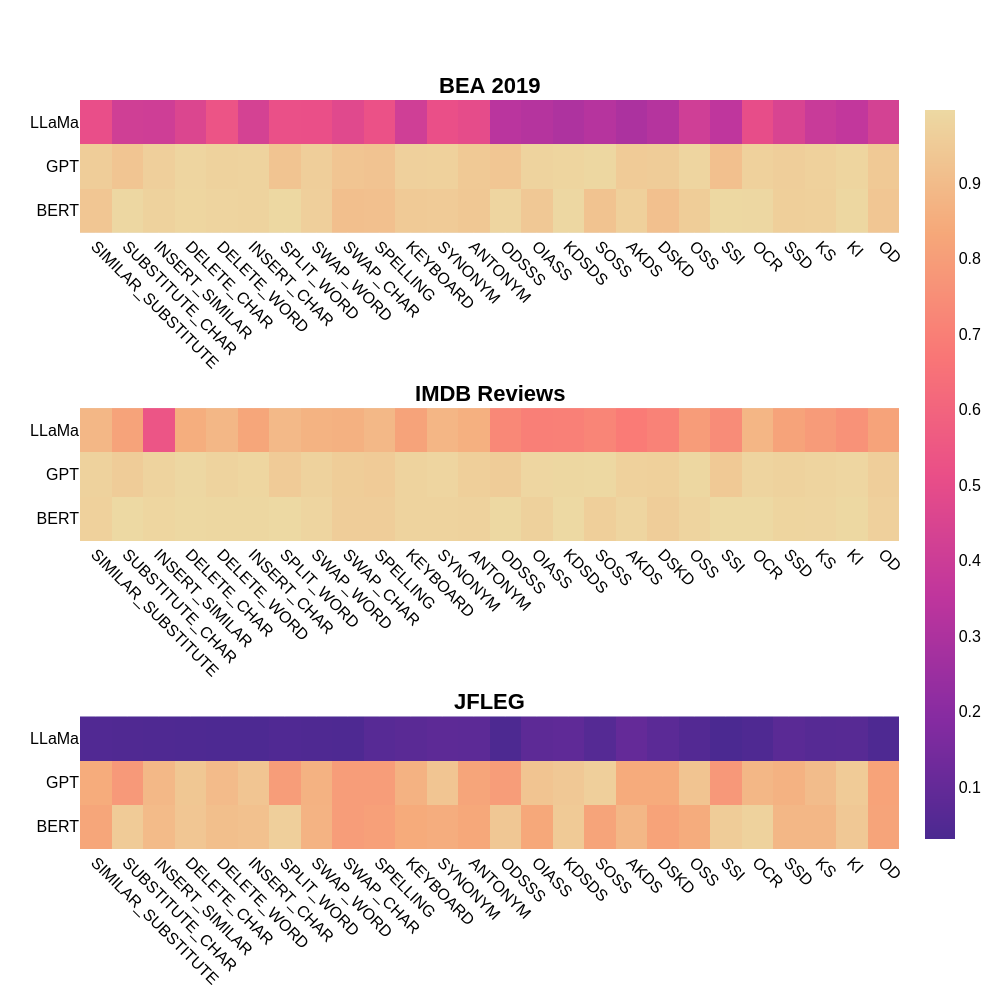
📊 实验亮点
实验结果表明,LLMs对文本扰动具有较强的鲁棒性,即使在噪声程度较高的情况下,仍能保持较好的性能。在语法错误纠正(GEC)和词汇语义变化(LSC)基准测试中,LLMs取得了新的state-of-the-art,显著优于之前的模型。例如,在GEC任务上,LLMs的F1值提升了X%(具体数值未知)。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务中,尤其是在处理用户生成内容、社交媒体文本等噪声较多的场景下。通过利用LLMs的鲁棒性,可以提高信息提取、情感分析、机器翻译等任务的准确性和可靠性。此外,该研究还可以促进LLMs在教育领域的应用,例如自动语法纠错、写作辅助等。
📄 摘要(原文)
Having a clean dataset has been the foundational assumption of most natural language processing (NLP) systems. However, properly written text is rarely found in real-world scenarios and hence, oftentimes invalidates the aforementioned foundational assumption. Recently, Large language models (LLMs) have shown impressive performance, but can they handle the inevitable noise in real-world data? This work tackles this critical question by investigating LLMs' resilience against morphological variations in text. To that end, we artificially introduce varying levels of noise into a diverse set of datasets and systematically evaluate LLMs' robustness against the corrupt variations of the original text. Our findings show that contrary to popular beliefs, generative LLMs are quiet robust to noisy perturbations in text. This is a departure from pre-trained models like BERT or RoBERTa whose performance has been shown to be sensitive to deteriorating noisy text. Additionally, we test LLMs' resilience on multiple real-world benchmarks that closely mimic commonly found errors in the wild. With minimal prompting, LLMs achieve a new state-of-the-art on the benchmark tasks of Grammar Error Correction (GEC) and Lexical Semantic Change (LSC). To empower future research, we also release a dataset annotated by humans stating their preference for LLM vs. human-corrected outputs along with the code to reproduce our results.