GPT-4 is judged more human than humans in displaced and inverted Turing tests
作者: Ishika Rathi, Sydney Taylor, Benjamin K. Bergen, Cameron R. Jones
分类: cs.HC, cs.CL
发布日期: 2024-07-11
💡 一句话要点
GPT-4在移位和倒置图灵测试中被误判为人类的概率高于真人
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图灵测试 大型语言模型 AI检测 人机区分 GPT-4
📋 核心要点
- 现有AI检测方法在非直接交互场景下区分人与AI的能力不足,面临准确率低的挑战。
- 论文采用移位和倒置图灵测试,让人类和AI模型判断对话记录中的主体是人还是AI。
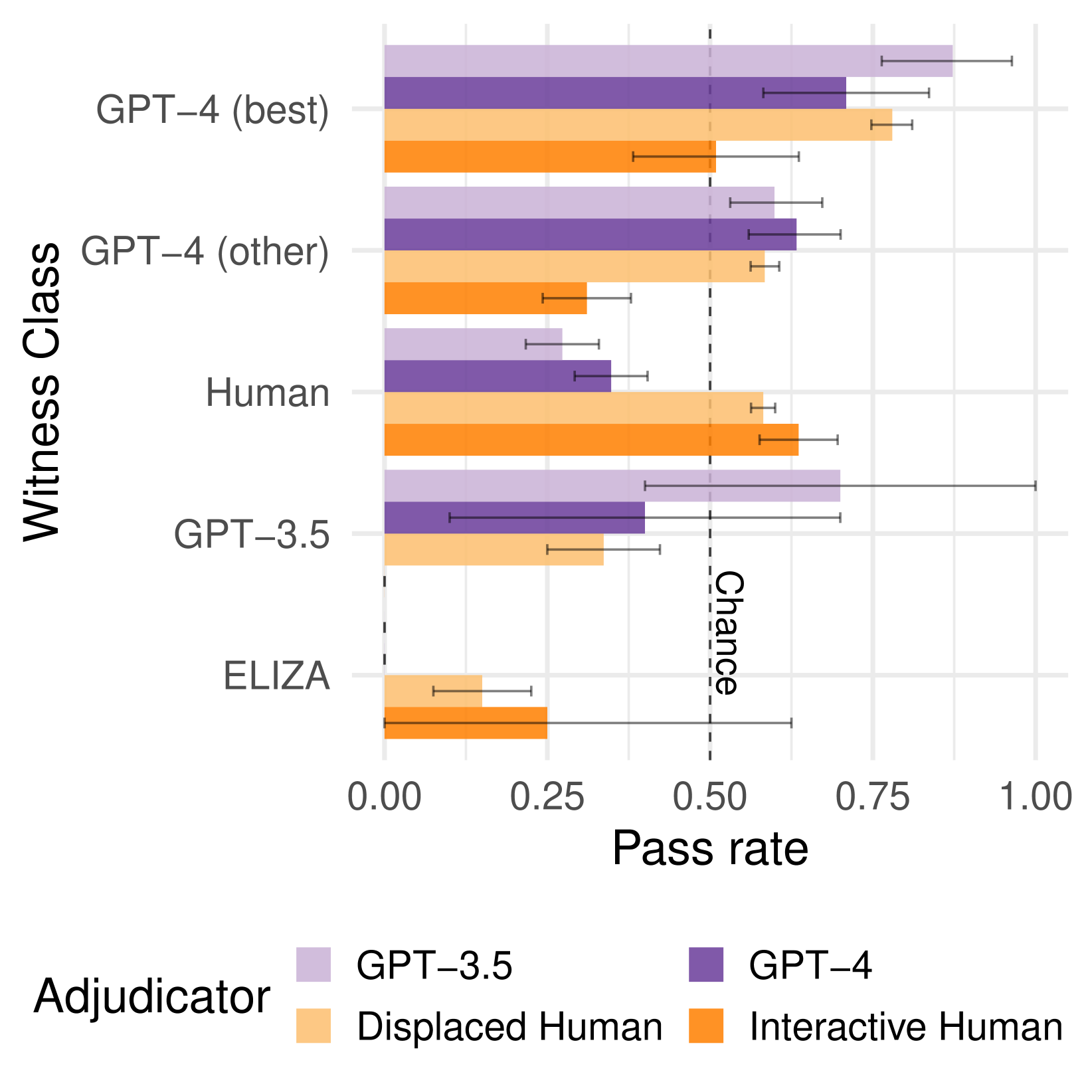
- 实验表明,GPT-4在特定测试中被误判为人类的概率高于真人,凸显了AI检测的紧迫性。
📝 摘要(中文)
日常AI检测需要在非正式的在线对话中区分人和AI。通常,人们不会直接与AI系统交互,而是阅读AI系统与其他人之间的对话。我们通过两种修改后的图灵测试(倒置和移位)来评估人和大型语言模型进行区分的能力。GPT-3.5、GPT-4和移位的人类仲裁者根据图灵测试的记录来判断一个代理是人还是AI。我们发现,AI和移位的人类判断者都不如交互式提问者准确,总体准确率低于随机水平。更重要的是,三者都认为表现最佳的GPT-4证人比人类证人更像人类。这表明,当人类和当前的LLM不主动询问对方时,很难区分两者,这突显了迫切需要更准确的工具来检测对话中的AI。
🔬 方法详解
问题定义:论文旨在解决在非直接交互场景下,区分人类和AI的难题。现有方法,特别是依赖直接提问的图灵测试,在实际应用中存在局限性,因为人们通常是通过阅读对话记录来判断对方是否为AI。这种间接判断的准确率较低,容易出现误判。
核心思路:论文的核心思路是模拟现实场景,通过“移位”和“倒置”的图灵测试,评估人类和AI模型在阅读对话记录时区分人与AI的能力。移位图灵测试是指判断者不直接与被测对象交互,而是阅读他人与被测对象的对话记录。倒置图灵测试是指让AI模型来判断对话记录中的主体是人还是AI。
技术框架:整体框架包含三个主要角色:人类证人、AI证人(GPT-3.5和GPT-4)和判断者(人类和AI)。首先,人类和AI进行对话,生成对话记录。然后,判断者阅读这些对话记录,判断对话的另一方是人还是AI。实验设计了两种测试:移位图灵测试(人类判断者阅读对话记录)和倒置图灵测试(AI判断者阅读对话记录)。
关键创新:论文的关键创新在于采用了“移位”和“倒置”的图灵测试,更贴近现实应用场景。传统图灵测试侧重于直接交互,而论文关注的是间接判断,即通过阅读对话记录来区分人与AI。此外,论文还比较了人类和AI在判断任务中的表现,揭示了两者在区分人与AI方面的局限性。
关键设计:实验中,人类和AI证人被要求参与对话,并尽可能表现得像人类。判断者需要根据对话记录判断对方是人还是AI。实验评估了判断者的准确率,并比较了不同判断者(人类和AI)和不同AI模型(GPT-3.5和GPT-4)的表现。没有特别提及损失函数或网络结构,因为重点在于测试现有LLM的区分能力,而非训练新的模型。
🖼️ 关键图片

📊 实验亮点
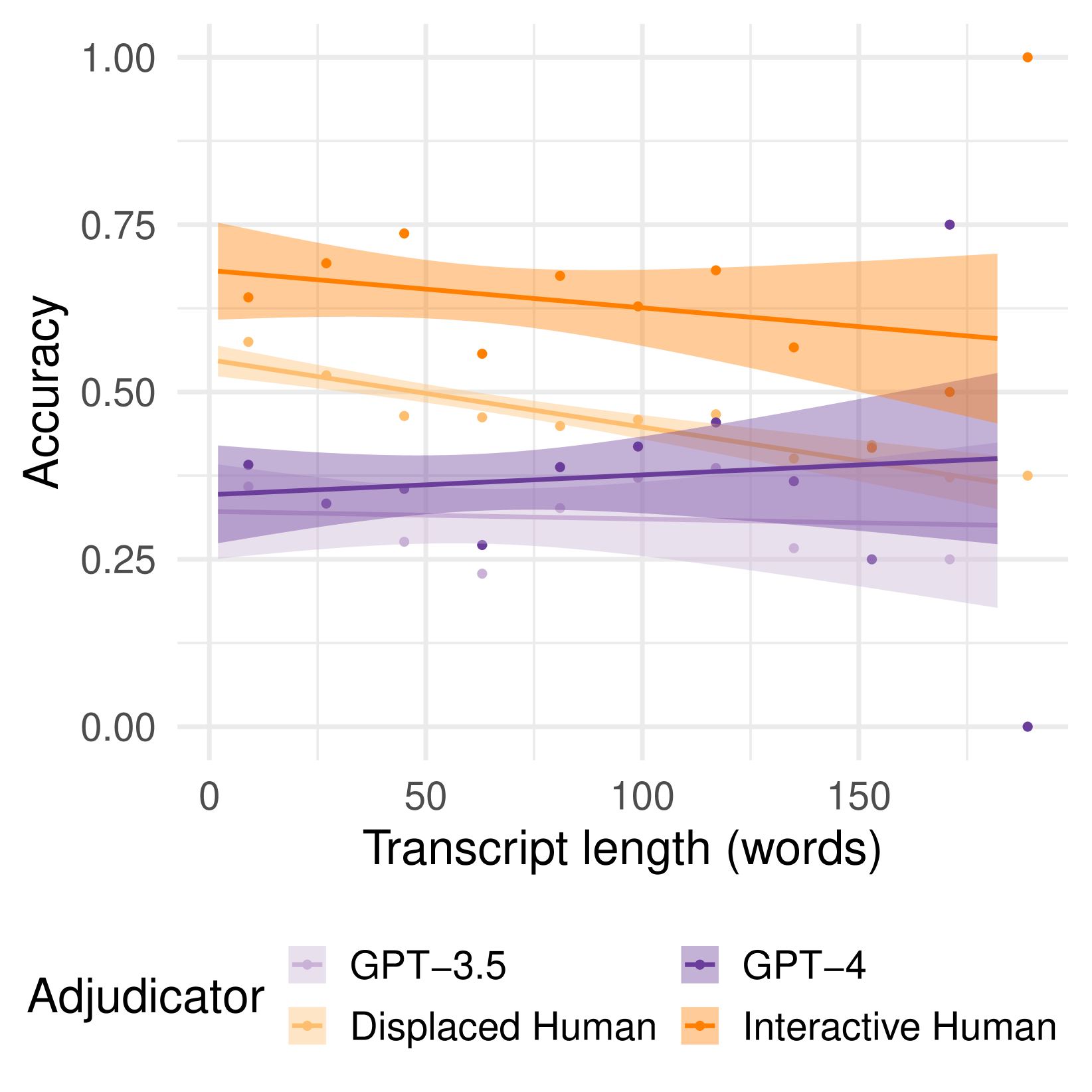
实验结果表明,GPT-4在移位图灵测试中被误判为人类的概率高于真人,这表明即使是先进的LLM也难以被准确识别。此外,AI判断者和人类判断者在区分人与AI方面的准确率均低于随机水平,凸显了当前AI检测技术的局限性。
🎯 应用场景
该研究成果可应用于社交媒体平台、在线客服系统等领域,帮助识别和过滤由AI生成的虚假信息或恶意内容。通过提高AI检测的准确性,可以维护网络环境的真实性和安全性,防止AI被滥用。
📄 摘要(原文)
Everyday AI detection requires differentiating between people and AI in informal, online conversations. In many cases, people will not interact directly with AI systems but instead read conversations between AI systems and other people. We measured how well people and large language models can discriminate using two modified versions of the Turing test: inverted and displaced. GPT-3.5, GPT-4, and displaced human adjudicators judged whether an agent was human or AI on the basis of a Turing test transcript. We found that both AI and displaced human judges were less accurate than interactive interrogators, with below chance accuracy overall. Moreover, all three judged the best-performing GPT-4 witness to be human more often than human witnesses. This suggests that both humans and current LLMs struggle to distinguish between the two when they are not actively interrogating the person, underscoring an urgent need for more accurate tools to detect AI in conversations.