Knowledge Overshadowing Causes Amalgamated Hallucination in Large Language Models
作者: Yuji Zhang, Sha Li, Jiateng Liu, Pengfei Yu, Yi R. Fung, Jing Li, Manling Li, Heng Ji
分类: cs.CL
发布日期: 2024-07-10
💡 一句话要点
揭示大语言模型中的“知识遮蔽”现象,并提出缓解幻觉的方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉 知识遮蔽 数据不平衡 自对比解码
📋 核心要点
- 现有大语言模型在知识密集型任务中易出现幻觉,尤其是在多条件查询时,表现为事实混合。
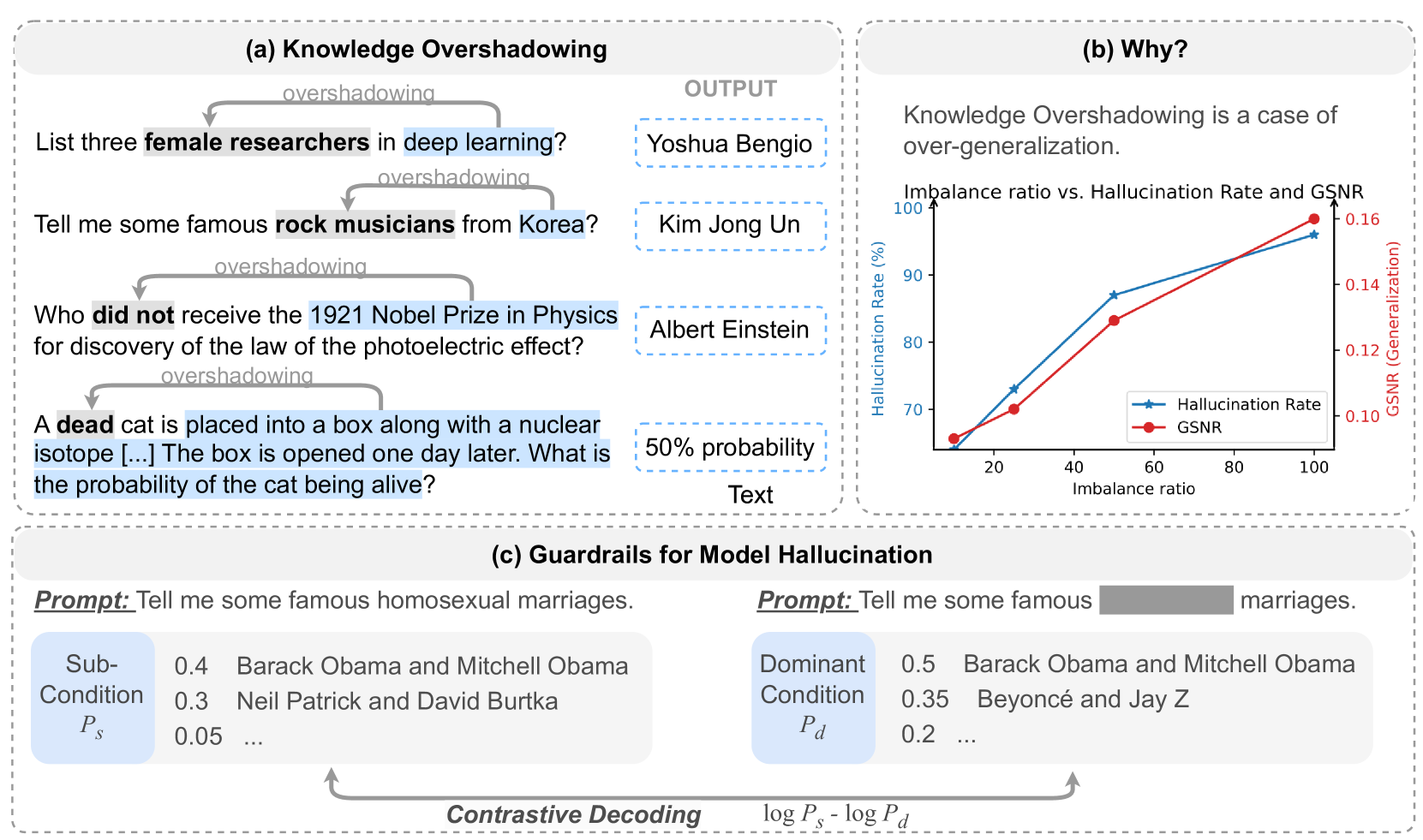
- 论文提出“知识遮蔽”概念,即部分条件掩盖其他条件导致幻觉,源于训练数据不平衡和过度泛化。
- 通过实验验证了知识遮蔽现象,并提出利用遮蔽条件预测幻觉和自对比解码方法缓解幻觉,F1值最高提升82%。
📝 摘要(中文)
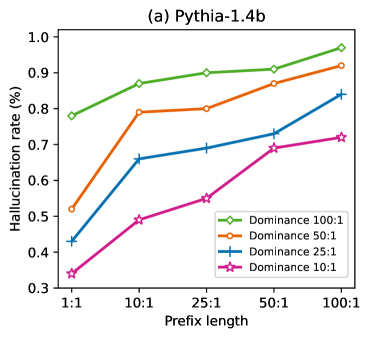
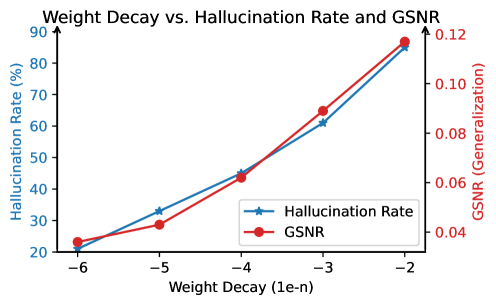
幻觉是大语言模型(LLMs)应用的主要障碍,尤其是在知识密集型任务中。即使训练语料库仅包含真实陈述,语言模型仍然会产生幻觉,表现为多个事实的混合。我们将这种现象称为“知识遮蔽”:当我们使用多个条件查询语言模型中的知识时,某些条件会遮蔽其他条件,从而导致幻觉输出。这种现象部分源于训练数据的不平衡,我们在预训练模型和微调模型上,以及各种LM模型系列和大小上验证了这一点。从理论角度来看,知识遮蔽可以解释为主要条件(模式)的过度泛化。我们表明,幻觉率随着不平衡比率(流行条件和非流行条件之间)和主要条件描述的长度而增长,这与我们推导的泛化界限一致。最后,我们提出利用遮蔽条件作为信号,在产生幻觉之前捕获它,并提出一种无需训练的自对比解码方法,以减轻推理过程中的幻觉。我们提出的方法在幻觉预测方面展示了高达82%的F1分数,并在不同的模型和数据集上实现了11.2%到39.4%的幻觉控制。
🔬 方法详解
问题定义:论文旨在解决大语言模型在知识密集型任务中出现的幻觉问题,特别是当模型被问及需要结合多个条件才能回答的问题时,容易出现“知识遮蔽”现象,导致模型将多个事实混合,产生错误的答案。现有方法难以有效识别和缓解这种由知识遮蔽引起的幻觉。
核心思路:论文的核心思路是识别并利用“知识遮蔽”现象本身作为一种信号来预测和缓解幻觉。作者认为,当某些条件在训练数据中占据主导地位时,模型会过度泛化这些条件,从而忽略其他条件,导致幻觉。因此,通过检测哪些条件可能导致遮蔽,可以提前预测幻觉的发生。
技术框架:论文主要包含两个阶段:幻觉预测和幻觉缓解。在幻觉预测阶段,论文利用遮蔽条件作为信号,训练一个分类器来预测是否会发生幻觉。在幻觉缓解阶段,论文提出了一种无需训练的自对比解码方法。该方法通过对比不同解码策略生成的文本,选择与原始输入更一致的文本,从而减少幻觉。
关键创新:论文的关键创新在于:1)首次提出了“知识遮蔽”这一概念,并从理论上解释了其产生的原因;2)提出了一种利用遮蔽条件作为信号来预测幻觉的方法,无需额外的训练数据;3)提出了一种无需训练的自对比解码方法,可以在推理过程中有效缓解幻觉。
关键设计:在幻觉预测阶段,论文使用一个二元分类器,输入是查询语句和遮蔽条件的表示,输出是是否会发生幻觉的概率。遮蔽条件的表示可以通过计算查询语句中每个条件的重要性得分来获得。在自对比解码阶段,论文使用不同的解码策略(例如,不同的温度系数)生成多个候选文本,然后使用一个预训练的语言模型来评估每个候选文本与原始输入的一致性,选择一致性最高的文本作为最终输出。具体的一致性评估方法未知。
🖼️ 关键图片
📊 实验亮点
论文提出的方法在幻觉预测方面取得了显著成果,F1分数最高达到82%。在幻觉控制方面,该方法在不同的模型和数据集上实现了11.2%到39.4%的幻觉缓解。这些结果表明,利用知识遮蔽作为信号可以有效预测和缓解大语言模型中的幻觉。
🎯 应用场景
该研究成果可应用于提升大语言模型在知识问答、信息检索、智能客服等领域的可靠性和准确性。通过提前预测和缓解幻觉,可以减少错误信息的传播,提高用户对AI系统的信任度,并促进大语言模型在更广泛场景中的应用。
📄 摘要(原文)
Hallucination is often regarded as a major impediment for using large language models (LLMs), especially for knowledge-intensive tasks. Even when the training corpus consists solely of true statements, language models still generate hallucinations in the form of amalgamations of multiple facts. We coin this phenomenon as ``knowledge overshadowing'': when we query knowledge from a language model with multiple conditions, some conditions overshadow others, leading to hallucinated outputs. This phenomenon partially stems from training data imbalance, which we verify on both pretrained models and fine-tuned models, over a wide range of LM model families and sizes.From a theoretical point of view, knowledge overshadowing can be interpreted as over-generalization of the dominant conditions (patterns). We show that the hallucination rate grows with both the imbalance ratio (between the popular and unpopular condition) and the length of dominant condition description, consistent with our derived generalization bound. Finally, we propose to utilize overshadowing conditions as a signal to catch hallucination before it is produced, along with a training-free self-contrastive decoding method to alleviate hallucination during inference. Our proposed approach showcases up to 82% F1 for hallucination anticipation and 11.2% to 39.4% hallucination control, with different models and datasets.