ETM: Modern Insights into Perspective on Text-to-SQL Evaluation in the Age of Large Language Models
作者: Benjamin G. Ascoli, Yasoda Sai Ram Kandikonda, Jinho D. Choi
分类: cs.CL
发布日期: 2024-07-10 (更新: 2025-06-16)
💡 一句话要点
提出ETM指标,提升大语言模型Text-to-SQL任务的评测可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 评估指标 大型语言模型 抽象语法树 语义分析
📋 核心要点
- 现有Text-to-SQL评估指标(EXE和ESM)在评估LLM生成SQL查询时,存在高估或低估性能的问题。
- 论文提出增强树匹配(ETM)指标,通过综合考虑句法和语义信息,更准确地评估SQL查询的正确性。
- 实验表明,ETM能显著降低传统指标的假阳性和假阴性率,提供更可靠的评估结果。
📝 摘要(中文)
Text-to-SQL任务旨在通过自然语言从SQL数据库中检索信息。尽管该任务取得了显著进展,但两种主要的评估指标——执行准确率(EXE)和精确集合匹配准确率(ESM)——存在固有的局限性,可能无法准确反映性能。具体而言,ESM的严格匹配忽略了语义正确但风格不同的查询,而EXE可能通过忽略产生正确输出的结构性错误来高估正确性。当评估未经微调的基于大型语言模型(LLM)的方法的输出时,这些缺点尤其突出,因为它们的风格和结构比微调后的方法变化更大。因此,我们引入了一种新的指标,增强树匹配(ETM),通过比较查询的句法和语义元素来缓解这些问题。通过评估九个基于LLM的模型,我们表明EXE和ESM可能产生高达23.0%和28.9%的假阳性和假阴性率,而ETM将这些比率分别降低到0.3%和2.7%。我们将ETM脚本开源,为社区提供了一种更强大、更可靠的Text-to-SQL评估方法。
🔬 方法详解
问题定义:Text-to-SQL任务旨在将自然语言转换为可执行的SQL查询。现有的评估指标,如EXE和ESM,在评估由大型语言模型生成的SQL查询时存在缺陷。ESM对SQL查询的语法结构要求严格,忽略了语义等价但表达方式不同的查询;EXE虽然关注执行结果,但可能忽略查询结构上的错误,导致评估结果不准确。这些问题在大模型时代尤为突出,因为大模型生成的SQL查询风格多样,结构复杂。
核心思路:论文的核心思路是提出一种新的评估指标ETM,该指标不仅考虑SQL查询的执行结果,还关注其句法和语义结构。ETM通过比较查询的抽象语法树,并结合语义信息,来判断查询的正确性。这种方法能够更准确地反映SQL查询的质量,避免了传统指标的局限性。
技术框架:ETM的评估流程主要包括以下几个步骤:1) 将生成的SQL查询和参考SQL查询解析为抽象语法树(AST);2) 对AST进行规范化处理,例如去除不必要的空格和注释;3) 比较两个AST的结构和节点信息,计算相似度得分;4) 结合语义信息,例如表名、列名等,对相似度得分进行调整;5) 根据最终得分判断查询的正确性。
关键创新:ETM的关键创新在于其综合考虑了SQL查询的句法和语义信息。与传统的基于字符串匹配或执行结果比较的方法不同,ETM能够更全面地评估SQL查询的质量。此外,ETM还引入了抽象语法树的概念,使得查询的结构比较更加高效和准确。
关键设计:ETM在AST比较过程中,采用了多种策略来提高评估的准确性。例如,对于不同的SQL语句类型,采用了不同的比较算法;对于AST中的关键节点,例如SELECT、FROM、WHERE等,赋予更高的权重。此外,ETM还支持自定义的语义规则,可以根据具体的数据库 schema 进行调整。
🖼️ 关键图片
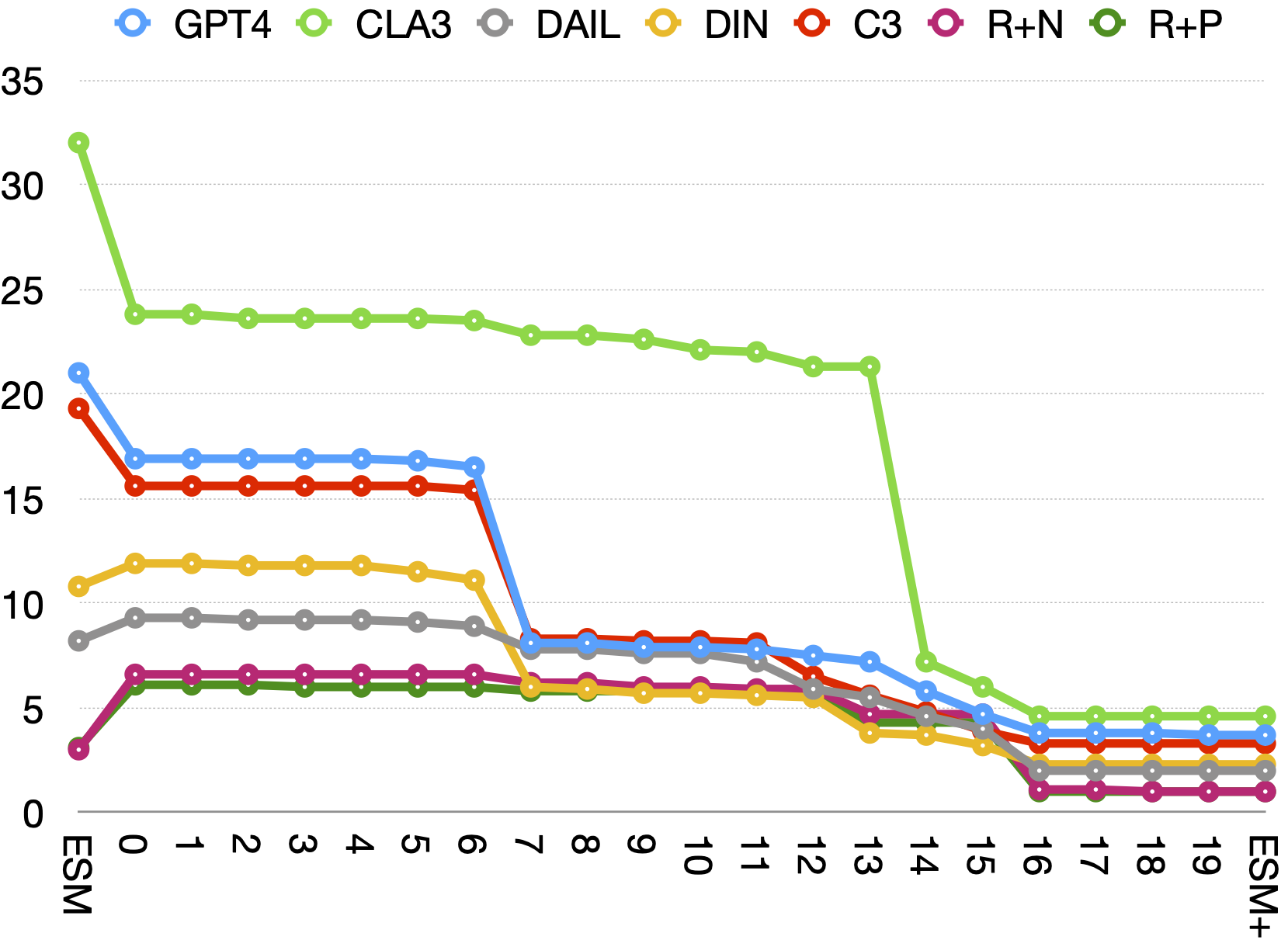

📊 实验亮点
实验结果表明,在评估九个基于LLM的Text-to-SQL模型时,传统指标EXE和ESM的假阳性和假阴性率分别高达23.0%和28.9%,而ETM将这些比率显著降低至0.3%和2.7%。这表明ETM能够更准确地评估Text-to-SQL模型的性能,避免了传统指标的误导。
🎯 应用场景
ETM指标可广泛应用于Text-to-SQL模型的评估和优化,帮助研究人员更准确地衡量模型性能,并指导模型改进方向。此外,该指标还可用于评估不同Text-to-SQL系统的优劣,为用户选择合适的系统提供参考。随着Text-to-SQL技术的不断发展,ETM有望成为该领域的重要评估标准。
📄 摘要(原文)
The task of Text-to-SQL enables anyone to retrieve information from SQL databases using natural language. While this task has made substantial progress, the two primary evaluation metrics - Execution Accuracy (EXE) and Exact Set Matching Accuracy (ESM) - suffer from inherent limitations that can misrepresent performance. Specifically, ESM's rigid matching overlooks semantically correct but stylistically different queries, whereas EXE can overestimate correctness by ignoring structural errors that yield correct outputs. These shortcomings become especially problematic when assessing outputs from large language model (LLM)-based approaches without fine-tuning, which vary more in style and structure compared to their fine-tuned counterparts. Thus, we introduce a new metric, Enhanced Tree Matching (ETM), which mitigates these issues by comparing queries using both syntactic and semantic elements. Through evaluating nine LLM-based models, we show that EXE and ESM can produce false positive and negative rates as high as 23.0% and 28.9%, while ETM reduces these rates to 0.3% and 2.7%, respectively. We release our ETM script as open source, offering the community a more robust and reliable approach to evaluating Text-to-SQL.