Limits to Predicting Online Speech Using Large Language Models
作者: Mina Remeli, Moritz Hardt, Robert C. Williamson
分类: cs.CL, cs.CY, cs.LG
发布日期: 2024-07-08 (更新: 2026-01-06)
备注: Updated Figure 1, added demographic analysis
💡 一句话要点
研究表明大型语言模型预测在线用户发言仍面临挑战,个性化建模至关重要
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 在线语音预测 用户建模 上下文学习 个性化推荐
📋 核心要点
- 现有语言模型在预测在线用户发言方面存在局限性,难以准确捕捉个体用户的语言习惯。
- 论文提出通过分析用户自身历史和社交圈内容,研究不同上下文对预测性能的影响。
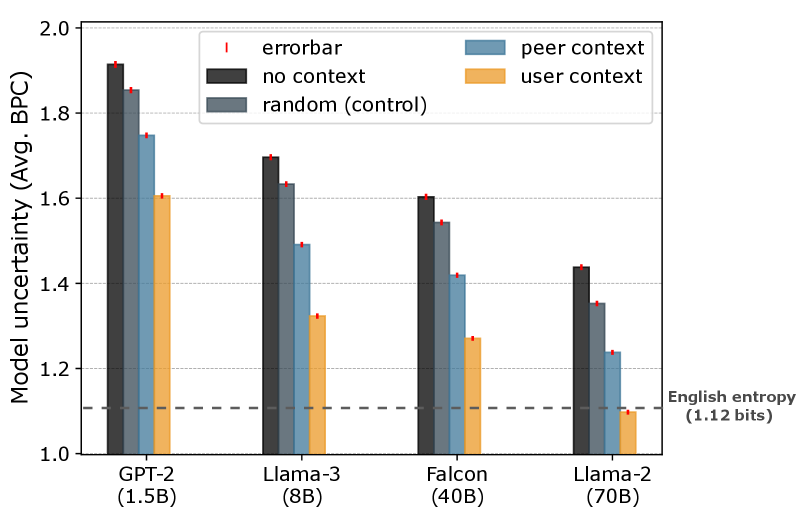
- 实验结果表明,利用用户自身历史记录能显著提升预测准确率,个性化建模至关重要。
📝 摘要(中文)
本文研究了在线语音的可预测性,即语言模型学习对X(前身为Twitter)上用户生成内容进行建模的能力。我们将可预测性定义为模型的不确定性度量,即其负对数似然。作为研究的基础,我们收集了1000万条推文用于“推文调优”基础模型,以及来自5000多名X(前身为Twitter)用户及其同行的625万条帖子。在涉及5000多名受试者的研究中,我们发现预测单个用户的帖子仍然非常困难。此外,使用的上下文非常重要:使用用户自身历史记录的模型明显优于使用其社交圈帖子的模型。我们在四种大型语言模型(参数规模从15亿到700亿)上验证了这些结果。此外,如果不是使用额外的上下文提示模型,而是对其进行微调,我们的结果仍然成立。我们进一步详细调查了上下文学习的内容以及人口统计分析。高达20%的上下文学习内容是@提及和主题标签的使用。我们的主要结果在我们研究的人口统计群体中都成立。
🔬 方法详解
问题定义:论文旨在研究大型语言模型在预测在线社交平台(如X/Twitter)上用户发言内容的能力。现有方法难以准确捕捉个体用户的语言风格和习惯,导致预测效果不佳。痛点在于如何有效利用上下文信息,提升模型对用户生成内容的理解和预测能力。
核心思路:论文的核心思路是深入分析不同类型的上下文信息(用户自身历史发言 vs. 用户社交圈发言)对预测性能的影响。通过对比不同上下文下的模型表现,揭示个性化建模的重要性,并探究模型学习到的具体内容。
技术框架:研究框架主要包括数据收集、模型训练与评估、以及结果分析三个阶段。首先,收集大量用户在X平台上的发言数据,包括用户自身历史推文和其社交圈的推文。然后,使用这些数据对大型语言模型进行微调或上下文学习。最后,通过计算负对数似然等指标,评估模型在不同上下文下的预测性能,并进行详细的分析。
关键创新:论文的关键创新在于对上下文信息进行了细致的区分和分析,揭示了用户自身历史发言在预测中的重要性。与以往研究侧重于通用语言模型不同,本文强调了个性化建模的必要性,并验证了其有效性。
关键设计:论文使用了多种大型语言模型(参数规模从1.5B到70B),并采用了两种主要的训练策略:上下文学习和微调。通过对比这两种策略在不同上下文下的表现,评估了模型的学习能力。此外,论文还对模型学习到的内容进行了分析,发现模型能够学习到@提及和主题标签等信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用用户自身历史记录进行建模,显著优于使用用户社交圈的帖子。在四种不同规模的语言模型上验证了这一结论,并且通过微调和上下文学习两种方式都得到了验证。分析表明,模型学习到的内容包括@提及和主题标签等信息,占比高达20%。
🎯 应用场景
该研究成果可应用于个性化推荐系统、社交媒体内容审核、以及用户画像构建等领域。通过更准确地预测用户发言内容,可以提升推荐系统的精准度,更有效地识别不良信息,并深入了解用户兴趣和行为模式。未来,该研究可推动更智能、更个性化的在线服务发展。
📄 摘要(原文)
Our paper studies the predictability of online speech -- that is, how well language models learn to model the distribution of user generated content on X (previously Twitter). We define predictability as a measure of the model's uncertainty, i.e. its negative log-likelihood. As the basis of our study, we collect 10M tweets for ``tweet-tuning'' base models and a further 6.25M posts from more than five thousand X (previously Twitter) users and their peers. In our study involving more than 5000 subjects, we find that predicting posts of individual users remains surprisingly hard. Moreover, it matters greatly what context is used: models using the users' own history significantly outperform models using posts from their social circle. We validate these results across four large language models ranging in size from 1.5 billion to 70 billion parameters. Moreover, our results replicate if instead of prompting the model with additional context, we finetune on it. We follow up with a detailed investigation on what is learned in-context and a demographic analysis. Up to 20\% of what is learned in-context is the use of @-mentions and hashtags. Our main results hold across the demographic groups we studied.