What's Wrong with Your Code Generated by Large Language Models? An Extensive Study
作者: Shihan Dou, Haoxiang Jia, Shenxi Wu, Huiyuan Zheng, Muling Wu, Yunbo Tao, Ming Zhang, Mingxu Chai, Jessica Fan, Zhiheng Xi, Rui Zheng, Yueming Wu, Ming Wen, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang
分类: cs.SE, cs.CL
发布日期: 2024-07-08 (更新: 2025-10-17)
备注: Accepted by SCIENCE CHINA Information Sciences (SCIS)
💡 一句话要点
深入分析大型语言模型代码生成缺陷,并提出自纠错迭代方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码生成 大型语言模型 错误分析 自我批判 迭代优化 真实世界基准测试 软件开发 自动化编程
📋 核心要点
- 现有工作主要集中于收集高质量数据集和利用各种训练技术来增强LLM的代码生成能力,但缺乏对现有方法局限性的全面研究。
- 论文提出了一种无训练的迭代方法,通过引入自我批判机制,使LLM能够根据错误类型和编译器反馈来评估和修正其生成的代码。
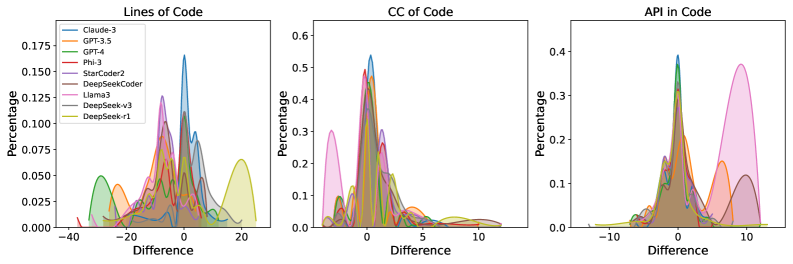
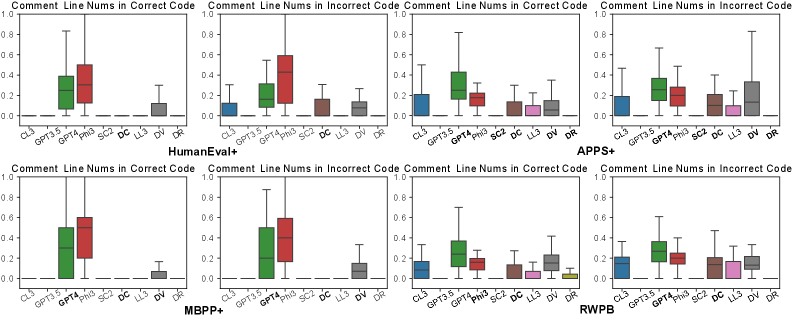
- 实验结果表明,LLM在生成复杂问题代码时面临挑战,且生成代码往往更短但更复杂。真实世界基准测试RWPB揭示了实际场景与现有基准测试之间的错误分布差异。
📝 摘要(中文)
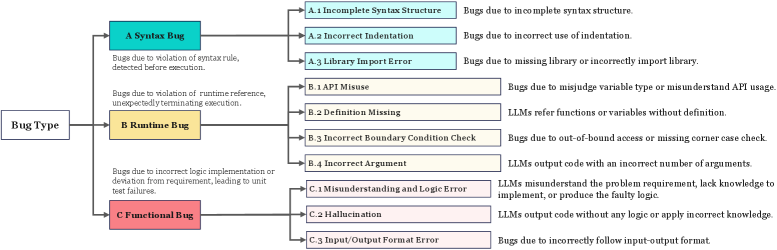
本文深入研究了大型语言模型(LLMs)在代码生成方面的局限性。通过对三个闭源LLMs和六个开源LLMs在常用基准测试上的评估,揭示了它们在处理复杂问题时生成成功代码的挑战,以及生成代码长度较短但复杂度较高的倾向。论文构建了一个包含三个类别和十个子类别的错误分类体系,并分析了常见错误类型的根本原因。为了更好地理解LLMs在实际项目中的表现,作者手动创建了一个真实世界的基准测试RWPB,并分析了其上的错误分布,突出了实际场景与现有基准测试之间的差异。最后,论文提出了一种新颖的无训练迭代方法,引入自我批判机制,使LLMs能够根据错误类型和编译器反馈来批判和纠正其生成的代码。这项研究为提升LLM代码生成的准确性和质量提供了有价值的见解。
🔬 方法详解
问题定义:现有的大型语言模型在代码生成方面取得了显著进展,但其生成的代码仍然存在诸多问题,尤其是在处理复杂问题时,代码的成功率较低,并且生成的代码往往比标准答案更短但复杂度更高。此外,现有的研究缺乏对LLM代码生成错误的系统性分析,以及在真实世界场景下的性能评估。
核心思路:本文的核心思路是首先通过大规模的实验评估,深入了解现有LLM在代码生成方面的缺陷和不足。然后,通过构建错误分类体系和真实世界基准测试,对LLM生成的代码进行细致的错误分析。最后,提出一种基于自我批判的迭代方法,使LLM能够自我纠正代码中的错误,从而提高代码生成的质量。
技术框架:本文的研究框架主要包括以下几个阶段:1) 选择多个具有代表性的闭源和开源LLM,以及常用的代码生成基准测试。2) 对LLM生成的代码进行长度、循环复杂度和API数量等指标的评估。3) 构建一个包含三个类别和十个子类别的错误分类体系,对LLM生成的错误代码进行分类和分析。4) 手动创建一个真实世界的基准测试RWPB,用于评估LLM在实际项目中的表现。5) 提出一种基于自我批判的迭代方法,使LLM能够自我纠正代码中的错误。
关键创新:本文最重要的技术创新点在于提出了一种无训练的迭代方法,该方法引入了自我批判机制,使LLM能够根据错误类型和编译器反馈来批判和纠正其生成的代码。这种方法不需要额外的训练数据,可以直接应用于现有的LLM,具有较强的实用性。
关键设计:在自我批判迭代方法中,关键的设计包括:1) 如何有效地识别和分类LLM生成的错误类型。2) 如何利用编译器反馈信息来指导LLM进行代码修正。3) 如何设计迭代的停止条件,以避免陷入无限循环。具体的技术细节在论文中没有详细描述,属于未知内容。
🖼️ 关键图片
📊 实验亮点
研究表明,LLM在生成复杂问题代码时面临挑战,且生成代码往往更短但更复杂。通过构建错误分类体系和真实世界基准测试RWPB,揭示了实际场景与现有基准测试之间的错误分布差异。提出的自我批判迭代方法能够有效提高LLM代码生成的质量,但具体提升幅度未知。
🎯 应用场景
该研究成果可应用于自动化软件开发、代码生成辅助工具、智能编程教育等领域。通过深入了解LLM代码生成的局限性,并利用自我纠错机制,可以显著提高代码生成的效率和质量,降低软件开发成本,并为程序员提供更智能化的编程辅助。
📄 摘要(原文)
The increasing development of LLMs in code generation has drawn significant attention among researchers. To enhance LLM-based code generation ability, current efforts are predominantly directed towards collecting high-quality datasets and leveraging diverse training technologies. However, there is a notable lack of comprehensive studies examining the limitations and boundaries of existing methods. To bridge this gap, we conducted an extensive empirical study evaluating the performance of three leading closed-source LLMs and six popular open-source LLMs on three commonly used benchmarks. Our investigation, which evaluated the length, cyclomatic complexity and API number of the generated code, revealed that these LLMs face challenges in generating successful code for more complex problems, and tend to produce code that is shorter yet more complicated as compared to canonical solutions. Additionally, we developed a taxonomy of bugs for incorrect codes that includes three categories and ten sub-categories, and analyzed the root cause for common bug types. To better understand the performance of LLMs in real-world projects, we also manually created a real-world benchmark RWPB. We analyzed bugs on RWPB to highlight distinct differences in bug distributions between actual scenarios and existing benchmarks. Finally, we propose a novel training-free iterative method that introduces self-critique, enabling LLMs to critique and correct their generated code based on bug types and compiler feedback. Our comprehensive and extensive study provides insights into the current limitations of LLM-based code generation and opportunities for enhancing the accuracy and quality of the generated code.