ANOLE: An Open, Autoregressive, Native Large Multimodal Models for Interleaved Image-Text Generation
作者: Ethan Chern, Jiadi Su, Yan Ma, Pengfei Liu
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-07-08
💡 一句话要点
Anole:开放、自回归、原生的大型多模态模型,用于交错的图像-文本生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态生成 大型语言模型 自回归模型 图像文本交错 原生集成
📋 核心要点
- 现有开源LMMs依赖适配器对齐视觉表征,且多局限于单模态生成,或依赖单独的扩散模型。
- Anole基于Chameleon构建,采用创新的数据高效和参数高效的微调策略,实现高质量多模态生成。
- Anole模型、训练框架和指令调优数据已开源,为多模态生成领域的研究提供了宝贵的资源。
📝 摘要(中文)
以往的开源大型多模态模型(LMMs)面临着一些局限性:(1)它们通常缺乏原生集成,需要适配器来将视觉表征与预训练的大型语言模型(LLMs)对齐;(2)许多模型仅限于单模态生成;(3)虽然有些模型支持多模态生成,但它们依赖于单独的扩散模型进行视觉建模和生成。为了缓解这些限制,我们提出了Anole,一个开放、自回归、原生的大型多模态模型,用于交错的图像-文本生成。我们基于Meta AI的Chameleon构建Anole,采用了一种数据高效和参数高效的创新微调策略。Anole展示了高质量、连贯的多模态生成能力。我们已经开源了我们的模型、训练框架和指令调优数据。
🔬 方法详解
问题定义:现有开源大型多模态模型主要存在三个痛点:一是缺乏原生集成,需要额外的适配器来对齐视觉表征和预训练的LLM;二是许多模型仅支持单模态生成,无法处理图像和文本交错生成的需求;三是部分支持多模态生成的模型依赖于独立的扩散模型进行视觉建模和生成,增加了复杂性。
核心思路:Anole的核心思路是构建一个原生支持多模态生成的大型模型,避免使用适配器或独立的视觉生成模型。通过在预训练的LLM基础上进行微调,使其能够直接处理和生成图像和文本交错的内容。这种原生集成的方式旨在提高效率和生成质量。
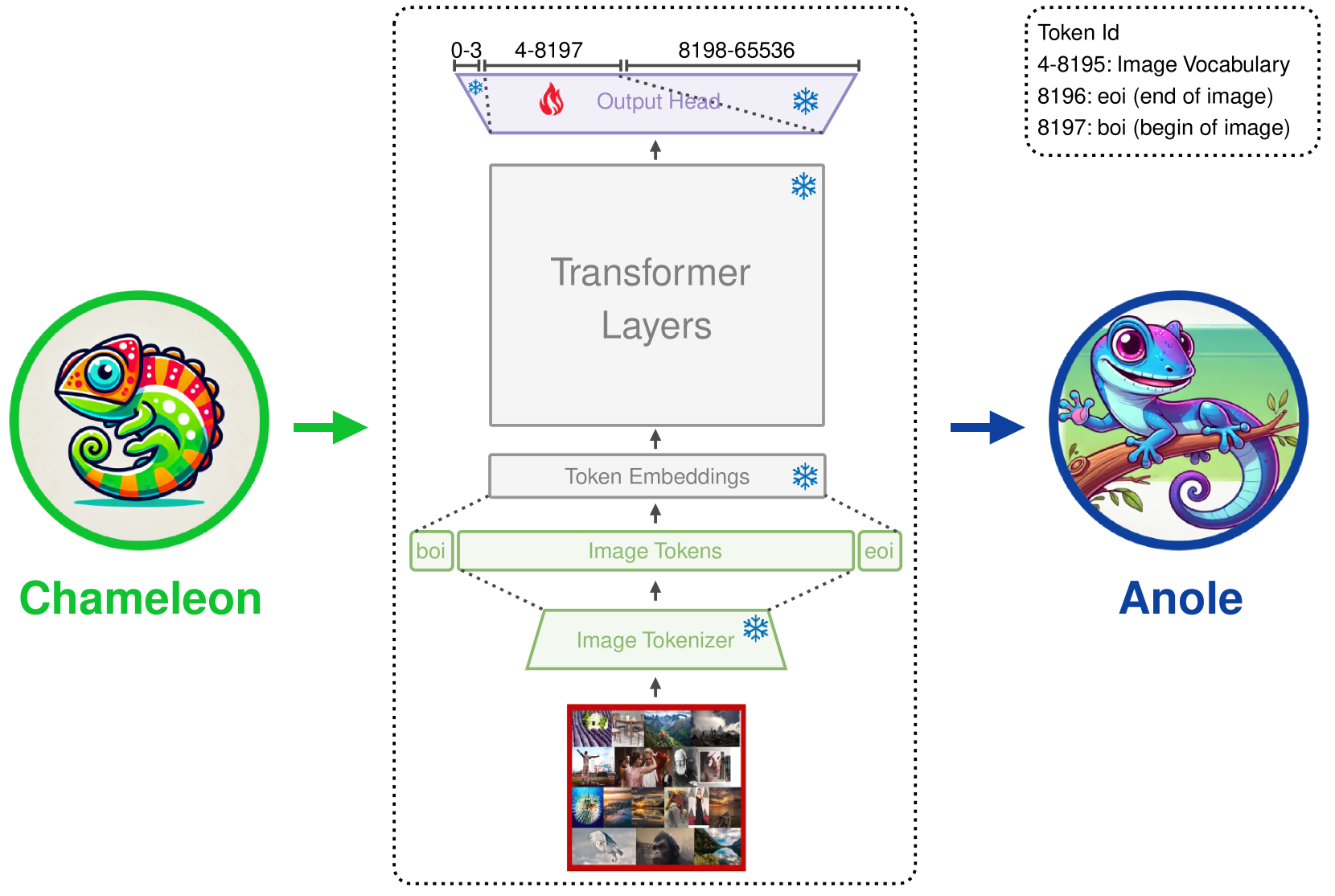
技术框架:Anole基于Meta AI的Chameleon模型构建。整体框架是一个自回归模型,能够根据上下文预测下一个token,无论是文本token还是图像token。训练流程主要包括预训练和微调两个阶段。预训练阶段使用大量的文本和图像数据,微调阶段则使用指令调优数据,以提高模型在特定任务上的性能。
关键创新:Anole的关键创新在于其原生多模态集成。与需要额外适配器的模型不同,Anole直接将视觉信息融入到LLM中,避免了信息损失和额外的计算开销。此外,Anole采用了一种数据高效和参数高效的微调策略,能够在有限的数据和计算资源下获得良好的性能。
关键设计:Anole的关键设计包括:(1) 使用Chameleon作为基础模型,Chameleon本身具有强大的语言建模能力;(2) 设计了一种特殊的tokenization方法,将图像表示为一系列离散的token,使其能够被LLM处理;(3) 采用了一种混合训练策略,结合了对比学习和生成学习,以提高模型的视觉理解和生成能力;(4) 使用了指令调优数据,以指导模型生成符合人类意图的多模态内容。
🖼️ 关键图片


📊 实验亮点
Anole通过数据高效和参数高效的微调策略,在多模态生成任务上表现出高质量和连贯性。虽然论文中没有给出具体的性能指标,但强调了其在原生集成和生成质量方面的优势。开源的模型、训练框架和指令调优数据为后续研究提供了便利。
🎯 应用场景
Anole具有广泛的应用前景,包括但不限于:智能文档生成、创意内容创作、教育辅助、人机交互等。例如,它可以根据用户提供的图像和文本提示,自动生成包含图像和文本的报告、故事或广告。其开源特性也促进了多模态生成技术在各个领域的应用和发展,并可能催生新的应用场景。
📄 摘要(原文)
Previous open-source large multimodal models (LMMs) have faced several limitations: (1) they often lack native integration, requiring adapters to align visual representations with pre-trained large language models (LLMs); (2) many are restricted to single-modal generation; (3) while some support multimodal generation, they rely on separate diffusion models for visual modeling and generation. To mitigate these limitations, we present Anole, an open, autoregressive, native large multimodal model for interleaved image-text generation. We build Anole from Meta AI's Chameleon, adopting an innovative fine-tuning strategy that is both data-efficient and parameter-efficient. Anole demonstrates high-quality, coherent multimodal generation capabilities. We have open-sourced our model, training framework, and instruction tuning data.