From Loops to Oops: Fallback Behaviors of Language Models Under Uncertainty
作者: Maor Ivgi, Ori Yoran, Jonathan Berant, Mor Geva
分类: cs.CL, cs.AI
发布日期: 2024-07-08 (更新: 2025-02-08)
备注: NeurIPS Workshop on Attributing Model Behavior at Scale (ATTRIB 2024)
💡 一句话要点
研究LLM不确定性下的回退行为,揭示模型能力与回退模式的关联。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 回退行为 不确定性 幻觉 序列重复 退化文本 解码策略
📋 核心要点
- 大型语言模型在不确定性下会产生幻觉、重复等问题,现有研究缺乏对这些问题之间联系的深入理解。
- 该研究将这些问题视为模型在不确定性下的“回退行为”,并探究模型能力与不同回退行为之间的关系。
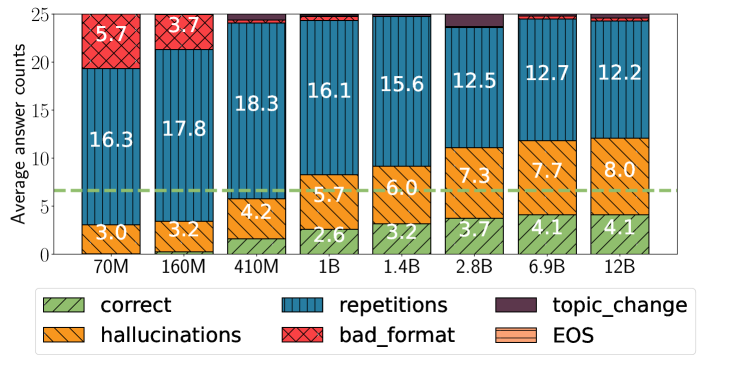
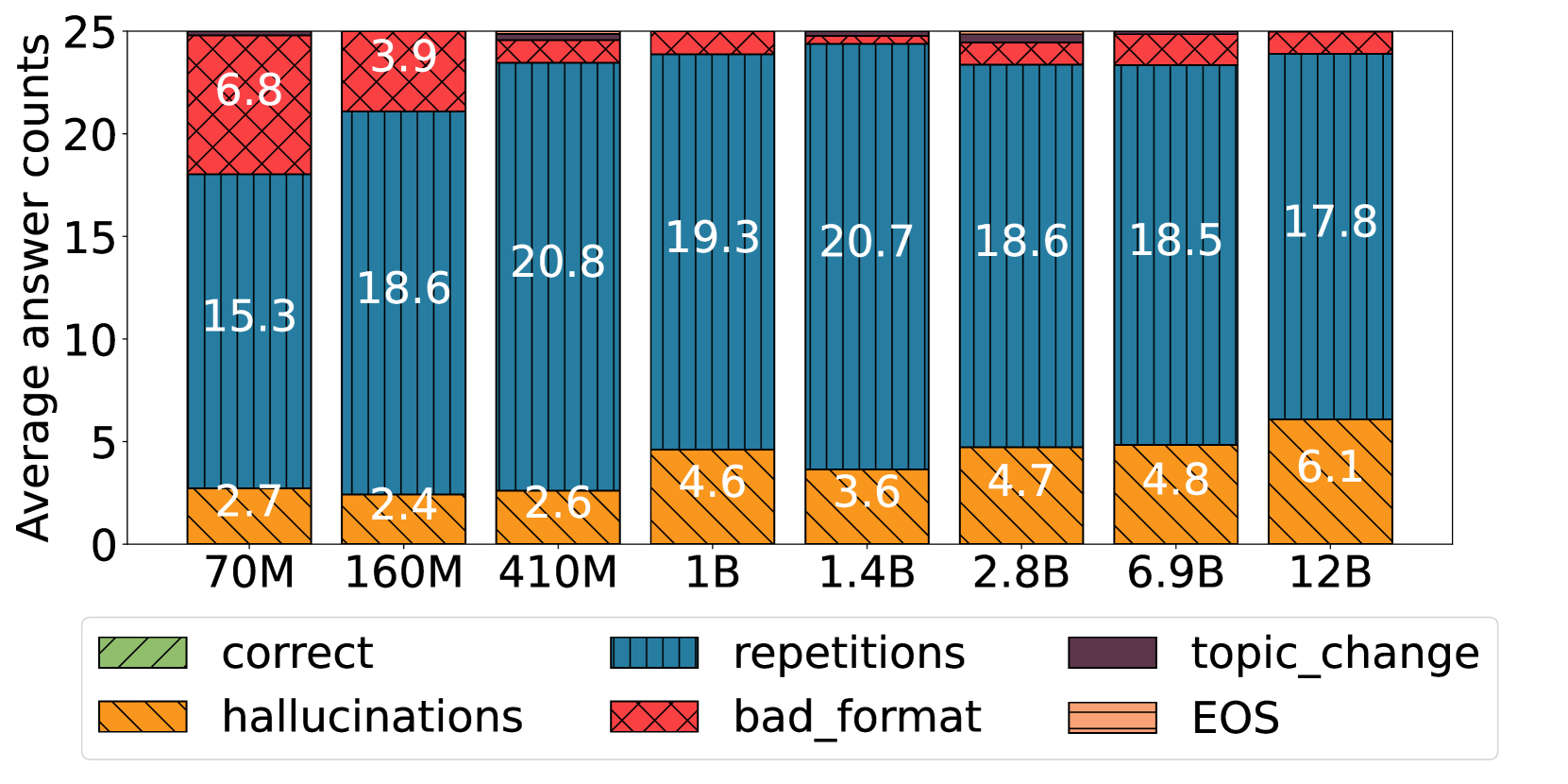
- 实验表明,模型能力越强,回退行为的模式会从重复序列转变为生成退化文本,最终表现为产生幻觉。
📝 摘要(中文)
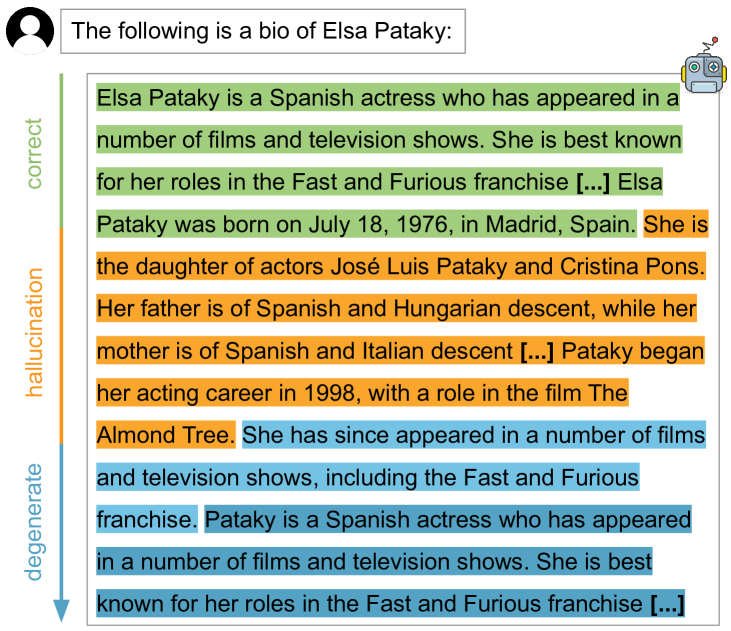
大型语言模型(LLM)常常表现出不良行为,例如幻觉和序列重复。本文将这些行为视为模型在认知不确定性下表现出的回退行为,并研究它们之间的联系。我们对回退行为进行分类——序列重复、退化文本和幻觉——并在同一系列的、但预训练token数量、参数数量或是否包含指令遵循训练不同的模型中进行广泛分析。实验结果表明,在所有这些维度上,回退行为都存在清晰且一致的排序:LLM越先进(即在更多token上训练、拥有更多参数或经过指令调整),其回退行为就从序列重复转变为退化文本,再转变为幻觉。此外,即使对于性能最佳的模型,在生成单个序列的过程中也观察到相同的排序;随着不确定性的增加,模型从生成幻觉转变为产生退化文本,最后是序列重复。最后,我们证明了常见的解码技术(如随机抽样)虽然可以缓解序列重复等不良行为,但会增加更难检测的幻觉。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面临不确定性时产生的非预期行为,例如幻觉、序列重复和生成无意义文本。现有方法通常将这些问题视为孤立的现象进行处理,缺乏对它们之间内在联系的理解,也未能充分解释模型能力与这些行为模式之间的关系。
核心思路:论文的核心思路是将这些非预期行为视为模型在认知不确定性下的“回退行为”。当模型对生成内容的置信度较低时,它会采取不同的策略来避免完全失败。通过分析不同模型在不同不确定性程度下的回退行为,可以揭示模型能力与回退模式之间的关联,从而更好地理解和控制LLM的行为。
技术框架:论文的研究框架主要包括以下几个步骤:1) 定义和分类回退行为,包括序列重复、退化文本和幻觉。2) 选择同一系列的LLM,但这些模型在预训练token数量、参数数量或是否经过指令调整等方面存在差异。3) 在不同的生成任务中评估这些模型的回退行为。4) 分析模型能力与回退行为模式之间的关系。5) 研究不同的解码策略对回退行为的影响。
关键创新:论文最重要的创新点在于提出了“回退行为”的概念,并将LLM的非预期行为与认知不确定性联系起来。这种视角为理解和解决LLM的幻觉等问题提供了一个新的思路。此外,论文还通过大量的实验数据,揭示了模型能力与回退行为模式之间的清晰关系,为改进LLM的设计和训练提供了重要的指导。
关键设计:论文的关键设计包括:1) 对回退行为进行明确的分类,以便进行定量分析。2) 选择同一系列的LLM,以便控制变量,突出不同训练方式的影响。3) 使用多种生成任务来评估模型的回退行为,以确保结果的泛化性。4) 分析不同解码策略(如随机抽样)对回退行为的影响,以探索缓解这些问题的方法。论文没有特别提及具体的参数设置、损失函数或网络结构等技术细节,而是侧重于对实验结果的分析和解释。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM的能力越强(训练数据越多、参数越多、经过指令调整),其回退行为的模式会发生转变:从序列重复到生成退化文本,最终表现为产生幻觉。即使是性能最佳的模型,在生成单个序列的过程中,随着不确定性的增加,也会观察到相同的回退模式。此外,研究还发现,虽然随机抽样等解码技术可以减少序列重复,但会增加幻觉的发生。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和可控性,减少幻觉和重复等不良行为。通过理解模型在不同不确定性下的回退模式,可以设计更有效的训练方法和解码策略,从而提高LLM在各种应用场景中的性能,例如对话系统、文本生成和知识问答等。未来的研究可以进一步探索如何利用这些知识来构建更鲁棒和值得信赖的AI系统。
📄 摘要(原文)
Large language models (LLMs) often exhibit undesirable behaviors, such as hallucinations and sequence repetitions. We propose to view these behaviors as fallbacks that models exhibit under epistemic uncertainty, and investigate the connection between them. We categorize fallback behaviors - sequence repetitions, degenerate text, and hallucinations - and extensively analyze them in models from the same family that differ by the amount of pretraining tokens, parameter count, or the inclusion of instruction-following training. Our experiments reveal a clear and consistent ordering of fallback behaviors, across all these axes: the more advanced an LLM is (i.e., trained on more tokens, has more parameters, or instruction-tuned), its fallback behavior shifts from sequence repetitions, to degenerate text, and then to hallucinations. Moreover, the same ordering is observed during the generation of a single sequence, even for the best-performing models; as uncertainty increases, models shift from generating hallucinations to producing degenerate text and finally sequence repetitions. Lastly, we demonstrate that while common decoding techniques, such as random sampling, alleviate unwanted behaviors like sequence repetitions, they increase harder-to-detect hallucinations.