InverseCoder: Self-improving Instruction-Tuned Code LLMs with Inverse-Instruct
作者: Yutong Wu, Di Huang, Wenxuan Shi, Wei Wang, Lingzhe Gao, Shihao Liu, Ziyuan Nan, Kaizhao Yuan, Rui Zhang, Xishan Zhang, Zidong Du, Qi Guo, Yewen Pu, Dawei Yin, Xing Hu, Yunji Chen
分类: cs.CL, cs.AI, cs.SE
发布日期: 2024-07-08 (更新: 2024-12-16)
备注: Accepted for publication at AAAI 2025. Extended version with full appendix, 18 pages
💡 一句话要点
InverseCoder:利用逆向指令自提升指令调优的代码大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大语言模型 指令调优 数据增强 逆向指令 自提升学习
📋 核心要点
- 现有开源代码大语言模型依赖于闭源模型生成的数据进行微调,成本高昂,探索利用开源模型自身生成数据进行增强成为关键。
- Inverse-Instruct利用代码LLM在代码转指令方面的优势,通过逆向生成指令来扩充训练数据,提升模型性能。
- 实验表明,该方法在多个开源代码模型和基准测试中均能有效提升模型性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Inverse-Instruct的数据增强技术,旨在提升开源代码大语言模型(LLMs)的性能。该方法利用已微调的LLM,从其自身的训练数据集中,为代码生成额外的指令。核心思想是:代码片段可以作为不同指令的响应,并且指令调优的代码LLM在将代码翻译成指令方面表现优于反向操作。通过将生成的指令-响应对添加到原始数据集,并在增强的数据集上进行微调,可以获得更强大的代码LLM。在CodeLlama-Python和DeepSeek-Coder等开源代码模型以及HumanEval(+), MBPP(+), DS-1000和MultiPL-E等基准测试上的实验结果表明,Inverse-Instruct能够持续改进基础模型。
🔬 方法详解
问题定义:现有开源代码大语言模型(Code LLMs)的训练依赖于从强大的闭源模型生成的数据集进行指令微调,这导致了高昂的训练成本和对闭源模型的依赖。如何利用已有的开源模型,以更经济有效的方式提升自身性能,是本文要解决的核心问题。现有方法的痛点在于数据获取成本高,且难以充分利用已训练模型的知识。
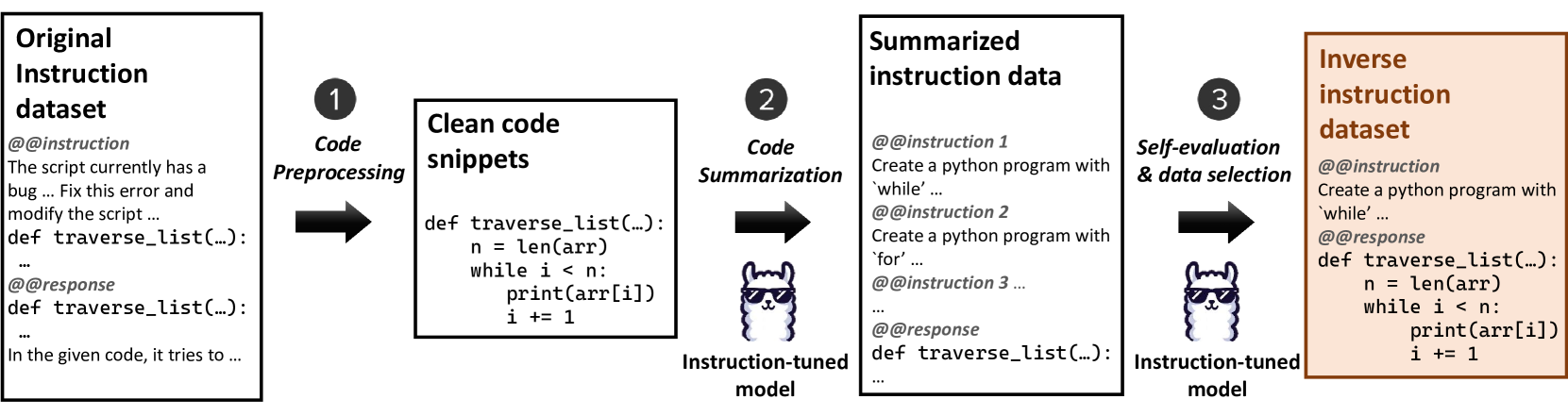
核心思路:本文的核心思路是利用指令调优的代码LLM在将代码翻译成指令方面的优势,通过“逆向指令”(Inverse-Instruct)的方式,从模型自身的训练数据集中生成额外的指令-代码对,从而扩充训练数据集。这样可以避免对昂贵的闭源模型的依赖,并充分利用已训练模型的知识。
技术框架:Inverse-Instruct方法的整体流程如下:1) 使用已微调的代码LLM。2) 从该LLM的原始训练数据集中提取代码片段。3) 使用该LLM将代码片段“翻译”成指令,生成新的指令-代码对。4) 将生成的指令-代码对添加到原始训练数据集中,形成增强后的数据集。5) 在增强后的数据集上对原始代码LLM进行微调,得到性能提升的模型。
关键创新:Inverse-Instruct的关键创新在于利用了代码LLM在代码到指令转换方面的优势,通过逆向生成指令的方式进行数据增强。与传统的正向数据增强方法相比,该方法能够更有效地利用已训练模型的知识,并避免了对昂贵闭源模型的依赖。此外,该方法是自提升的,即模型可以通过自身生成的数据来提升性能。
关键设计:在具体实现中,需要选择合适的代码LLM作为基础模型,并确定从原始数据集中提取哪些代码片段。在生成指令时,可以使用不同的prompt策略来控制生成指令的多样性和质量。此外,还需要确定添加到原始数据集中的新指令-代码对的数量,以避免过拟合。
🖼️ 关键图片

📊 实验亮点
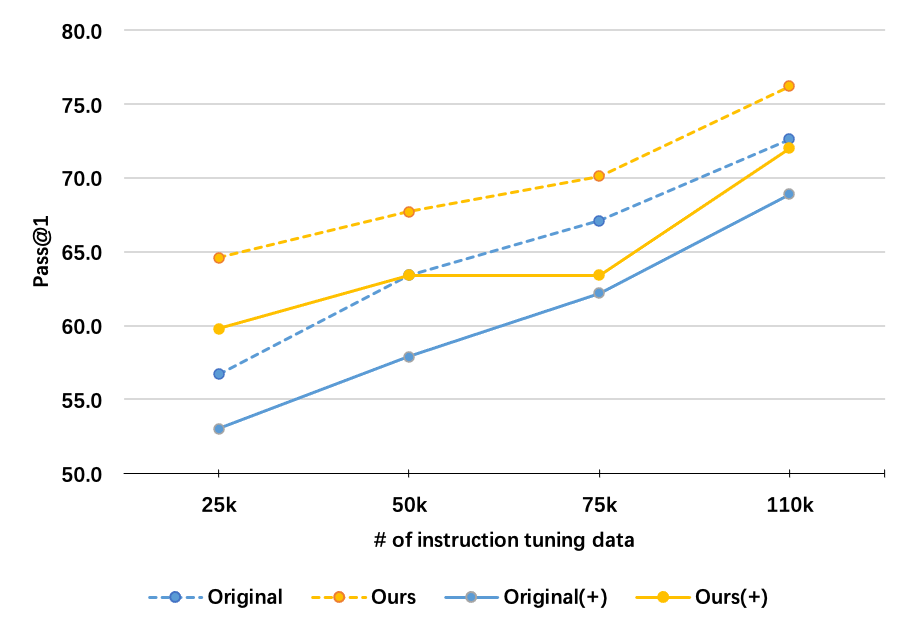
实验结果表明,Inverse-Instruct方法能够显著提升开源代码模型的性能。例如,在HumanEval(+)基准测试中,使用Inverse-Instruct方法对CodeLlama-Python进行微调后,pass@1指标提升了多个百分点。此外,该方法在MBPP(+), DS-1000和MultiPL-E等基准测试中也取得了显著的性能提升,证明了其有效性和泛化能力。
🎯 应用场景
该研究成果可广泛应用于代码生成、代码理解、代码修复等领域。通过Inverse-Instruct方法,可以更经济有效地提升开源代码大语言模型的性能,降低开发成本,促进开源社区的发展。未来,该方法有望应用于更广泛的自然语言处理任务中,例如文本摘要、机器翻译等。
📄 摘要(原文)
Recent advancements in open-source code large language models (LLMs) have been driven by fine-tuning on the data generated from powerful closed-source LLMs, which are expensive to obtain. This paper explores whether it is possible to use a fine-tuned open-source model to generate additional data to augment its instruction-tuning dataset. We make two observations: (1) A code snippet can serve as the response to different instructions. (2) Instruction-tuned code LLMs perform better at translating code into instructions than the reverse. Based on these observations, we propose Inverse-Instruct, a data augmentation technique that uses a fine-tuned LLM to generate additional instructions of code responses from its own training dataset. The additional instruction-response pairs are added to the original dataset, and a stronger code LLM can be obtained by fine-tuning on the augmented dataset. We empirically validate Inverse-Instruct on a range of open-source code models (e.g. CodeLlama-Python and DeepSeek-Coder) and benchmarks (e.g., HumanEval(+), MBPP(+), DS-1000 and MultiPL-E), showing it consistently improves the base models.