Large Language Model as an Assignment Evaluator: Insights, Feedback, and Challenges in a 1000+ Student Course
作者: Cheng-Han Chiang, Wei-Chih Chen, Chun-Yi Kuan, Chienchou Yang, Hung-yi Lee
分类: cs.CL
发布日期: 2024-07-07 (更新: 2024-09-21)
备注: EMNLP 2024 main conference paper. An empirical report of our course: Introduction to Generative AI 2024 Spring (https://speech.ee.ntu.edu.tw/~hylee/genai/2024-spring.php)
💡 一句话要点
利用大语言模型GPT-4评估学生作业:大规模课程的实践与挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动评估 教育应用 GPT-4 提示工程
📋 核心要点
- 现有自动评估方法难以有效评估学生作业,尤其是在大规模课程中,需要更高效、可扩展的评估方案。
- 本研究探索使用GPT-4作为自动评估器,旨在减轻教师负担,并为学生提供即时反馈,提升学习体验。
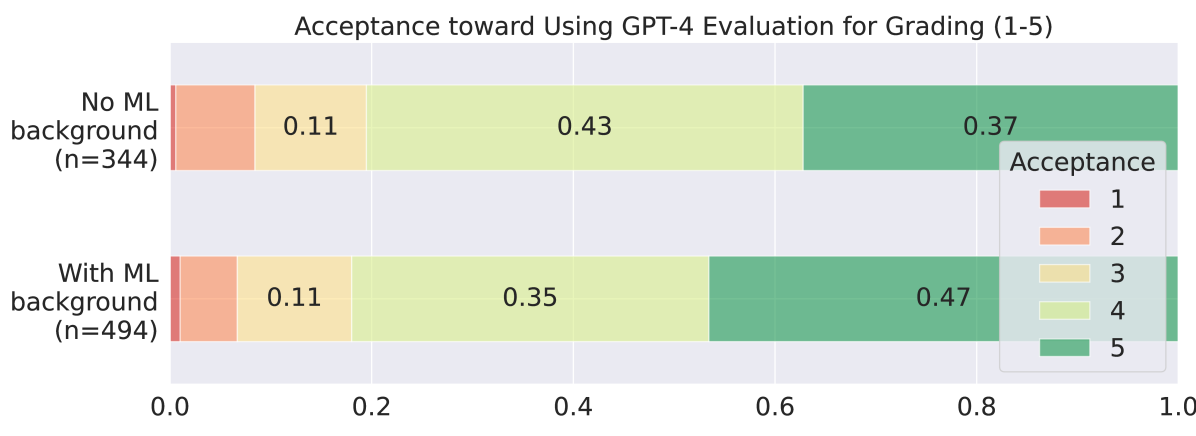
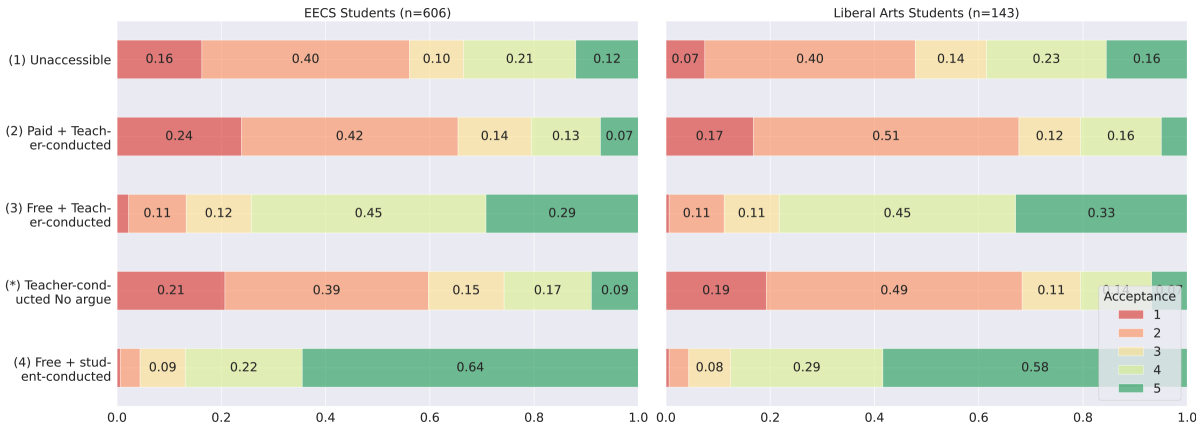
- 实验结果表明,学生普遍接受LLM评估器,但也发现了指令遵循和提示攻击等问题,为未来研究提供了方向。
📝 摘要(中文)
本文探讨了将大型语言模型(LLM)应用于自动评估学生作业的可行性。尽管基于LLM的自动评估在自然语言处理研究中日益重要,但其在真实课堂环境中的应用效果尚不明确。本研究分享了在一个拥有1028名学生的大学课程中,使用GPT-4作为自动作业评估器的经验。学生反馈表明,当他们可以自由使用LLM评估器时,普遍接受这种评估方式。然而,学生也指出LLM有时未能严格遵守评估指令。此外,研究发现学生可以轻易操纵LLM评估器输出特定字符串,从而在不符合评分标准的情况下获得高分。基于学生反馈和实践经验,本文为未来课堂中整合LLM评估器提供了若干建议,并强调了改进LLM评估器的潜在方向,包括提升其指令遵循能力和抵抗提示攻击的能力。
🔬 方法详解
问题定义:本研究旨在解决大规模课程中学生作业评估效率低下的问题。传统的人工评估耗时费力,难以满足学生对及时反馈的需求。现有的自动评估方法,如基于规则或传统机器学习的方法,难以处理自然语言的复杂性和多样性,评估质量不高。
核心思路:利用大型语言模型(LLM)强大的自然语言理解和生成能力,模拟人工评估过程,自动对学生作业进行评分和反馈。核心在于将LLM作为评估器,通过精心设计的提示词(prompt)引导LLM理解评估标准并进行客观评估。
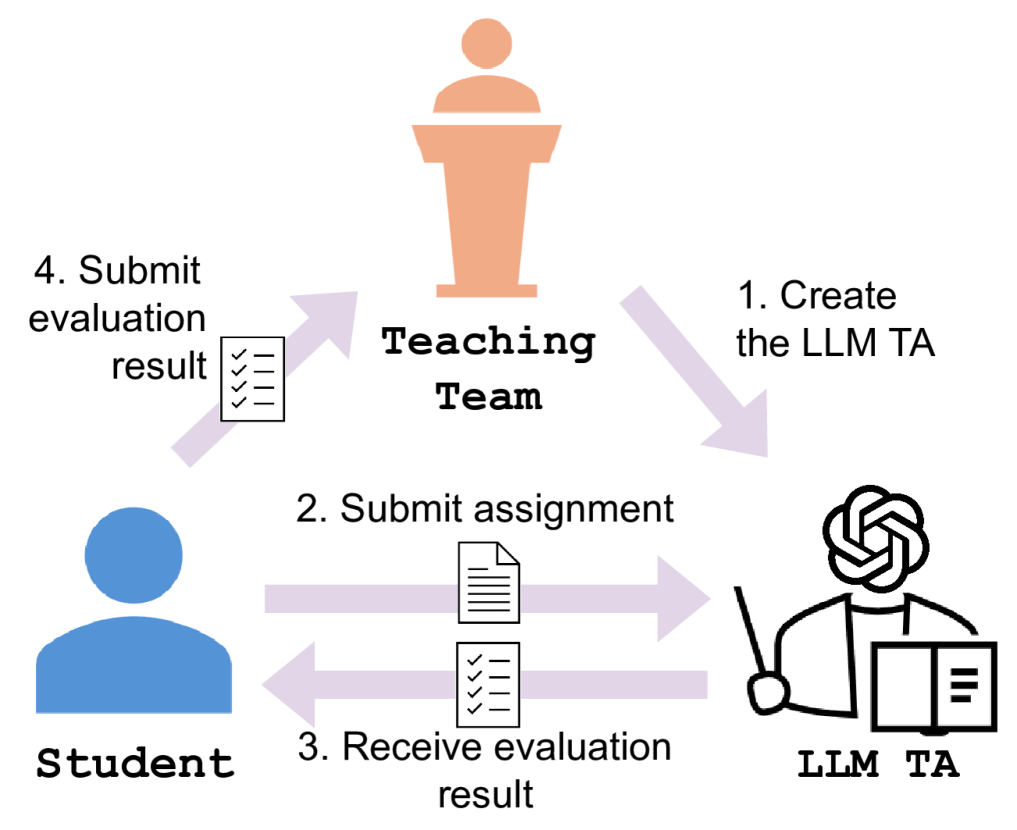
技术框架:整体流程包括:1) 设计作业评估标准和提示词;2) 将学生作业输入GPT-4;3) GPT-4根据提示词进行评估,输出评分和反馈;4) 收集学生对GPT-4评估结果的反馈;5) 分析反馈结果,改进提示词和评估流程。
关键创新:本研究的关键创新在于将预训练的大型语言模型GPT-4应用于学生作业的自动评估,并探索其在真实课堂环境中的可行性和挑战。与以往基于规则或传统机器学习的自动评估方法相比,GPT-4具有更强的泛化能力和自然语言处理能力。
关键设计:关键设计包括:1) 详细的作业评估标准,明确评分细则;2) 精心设计的提示词,引导GPT-4理解评估标准并进行客观评估;3) 学生反馈机制,收集学生对GPT-4评估结果的意见,用于改进评估流程;4) 针对提示攻击的防御策略,例如限制GPT-4的输出格式和内容。
🖼️ 关键图片
📊 实验亮点
研究表明,学生普遍接受GPT-4作为作业评估器,尤其是在可以自由使用的情况下。然而,学生也发现GPT-4有时未能严格遵守评估指令,并且容易受到提示攻击,导致不符合要求的作业获得高分。这些发现为改进LLM评估器提供了重要的方向,例如提升指令遵循能力和抵抗提示攻击的能力。
🎯 应用场景
该研究成果可应用于大规模在线教育、编程作业自动评测、论文自动评审等领域。通过降低人工评估成本,提高评估效率,可以为学生提供更及时、个性化的反馈,从而提升学习效果。未来,结合LLM的自动评估系统有望成为教育领域的重要工具,促进教育公平和个性化发展。
📄 摘要(原文)
Using large language models (LLMs) for automatic evaluation has become an important evaluation method in NLP research. However, it is unclear whether these LLM-based evaluators can be applied in real-world classrooms to assess student assignments. This empirical report shares how we use GPT-4 as an automatic assignment evaluator in a university course with 1,028 students. Based on student responses, we find that LLM-based assignment evaluators are generally acceptable to students when students have free access to these LLM-based evaluators. However, students also noted that the LLM sometimes fails to adhere to the evaluation instructions. Additionally, we observe that students can easily manipulate the LLM-based evaluator to output specific strings, allowing them to achieve high scores without meeting the assignment rubric. Based on student feedback and our experience, we provide several recommendations for integrating LLM-based evaluators into future classrooms. Our observation also highlights potential directions for improving LLM-based evaluators, including their instruction-following ability and vulnerability to prompt hacking.