Statistical investigations into the geometry and homology of random programs
作者: Jon Sporring, Ken Friis Larsen
分类: cs.CL
发布日期: 2024-07-05
备注: 16 pages, 11 figures
💡 一句话要点
利用几何与拓扑统计分析随机程序,无需高维嵌入近似
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 随机程序分析 几何拓扑分析 Tree-edit距离 大型语言模型 程序语法树
📋 核心要点
- 现有方法在高维空间中分析程序时依赖降维嵌入,这会引入近似误差,影响分析的准确性。
- 该论文提出使用几何汇总统计、空间点统计和拓扑数据分析,直接在程序语法树上进行分析,避免了降维带来的误差。
- 通过比较ChatGPT-4和TinyLlama在图像处理任务上的表现,验证了该方法在理解和比较不同大语言模型生成程序方面的有效性。
📝 摘要(中文)
随着Meta的Llama和openAI的chatGPT等工具的出现,AI辅助编程取得了巨大的进步。这些都是程序的随机来源的例子,并且已经极大地影响了我们生成代码和教授编程的方式。如果我们将此类模型的输入视为随机源,那么一个自然的问题是,输入和输出分布之间、chatGPT提示和生成的程序之间存在什么关系?在本文中,我们将展示如何使用程序语法树之间的Tree-edit距离,在不显式建模底层空间的情况下,从几何和拓扑上描述从chatGPT生成的随机Python程序之间的关系。一种研究度量空间中高维样本的常用方法是使用低维嵌入,例如多维尺度分析。这些方法会产生误差,具体取决于数据和嵌入空间的维度。在本文中,我们建议将此类投影方法限制为纯粹的可视化目的,而是使用几何汇总统计、空间点统计方法和拓扑数据分析来表征不依赖于嵌入近似的随机程序的配置。为了证明它们的有用性,我们比较了两个公开可用的模型:ChatGPT-4和TinyLlama,解决了一个与图像处理相关的简单问题。
🔬 方法详解
问题定义:论文旨在研究由大型语言模型(LLM)生成的随机程序之间的关系。现有方法通常采用降维嵌入技术(如多维尺度分析)来分析高维数据,但这些方法会引入与数据和嵌入维度相关的误差,影响分析结果的准确性。因此,如何避免降维带来的误差,更准确地分析随机程序的结构和特性,是本文要解决的核心问题。
核心思路:论文的核心思路是避开高维嵌入,直接在程序的语法树上进行几何和拓扑分析。具体来说,通过计算程序语法树之间的Tree-edit距离来衡量程序之间的相似性,并利用几何汇总统计、空间点统计和拓扑数据分析等方法来表征随机程序的配置。这种方法无需进行降维近似,能够更准确地反映程序之间的关系和结构。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 使用大型语言模型(如ChatGPT-4和TinyLlama)生成随机Python程序;2) 构建程序的语法树;3) 计算语法树之间的Tree-edit距离;4) 利用几何汇总统计、空间点统计和拓扑数据分析方法分析程序配置;5) 比较不同语言模型生成的程序在几何和拓扑特性上的差异。
关键创新:该论文的关键创新在于提出了一种无需高维嵌入的随机程序分析方法。与传统的降维方法相比,该方法能够更准确地反映程序之间的关系和结构,避免了降维带来的误差。此外,该研究还将几何汇总统计、空间点统计和拓扑数据分析等方法应用于程序分析领域,为理解和比较不同语言模型生成的程序提供了新的视角。
关键设计:论文的关键设计包括:1) 使用Tree-edit距离作为程序相似性的度量标准,Tree-edit距离能够有效地衡量语法树之间的差异;2) 选择合适的几何汇总统计、空间点统计和拓扑数据分析方法来表征程序配置,例如,可以使用Ripser.py进行持久同调计算;3) 设计实验来比较不同语言模型(如ChatGPT-4和TinyLlama)生成的程序在几何和拓扑特性上的差异,从而评估不同模型的性能。
🖼️ 关键图片

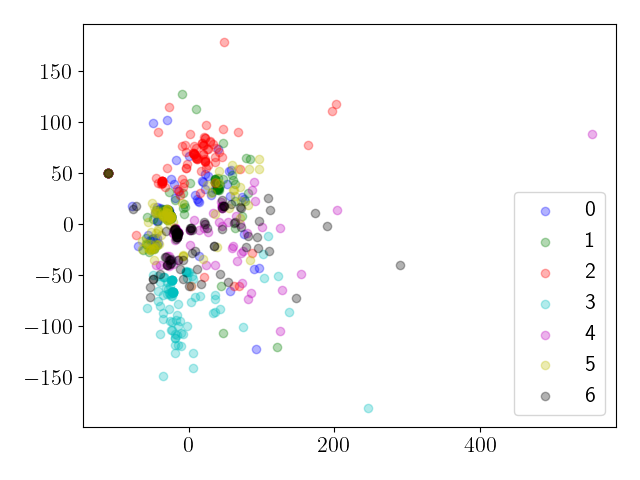
📊 实验亮点
该研究通过实验比较了ChatGPT-4和TinyLlama在图像处理任务上的表现。实验结果表明,该方法能够有效地识别不同模型生成的程序在几何和拓扑特性上的差异,从而为评估和比较不同语言模型的性能提供了有力的工具。具体的性能数据和提升幅度在摘要中未明确给出,属于未知信息。
🎯 应用场景
该研究的应用场景包括:理解如何提问才能获得有用的程序;衡量大型语言模型回答问题的一致性;比较不同的大型语言模型作为编程助手的优劣。此外,该方法还有助于深入理解编程语言的结构,为未来的编程语言设计提供新的见解。
📄 摘要(原文)
AI-supported programming has taken giant leaps with tools such as Meta's Llama and openAI's chatGPT. These are examples of stochastic sources of programs and have already greatly influenced how we produce code and teach programming. If we consider input to such models as a stochastic source, a natural question is, what is the relation between the input and the output distributions, between the chatGPT prompt and the resulting program? In this paper, we will show how the relation between random Python programs generated from chatGPT can be described geometrically and topologically using Tree-edit distances between the program's syntax trees and without explicit modeling of the underlying space. A popular approach to studying high-dimensional samples in a metric space is to use low-dimensional embedding using, e.g., multidimensional scaling. Such methods imply errors depending on the data and dimension of the embedding space. In this article, we propose to restrict such projection methods to purely visualization purposes and instead use geometric summary statistics, methods from spatial point statistics, and topological data analysis to characterize the configurations of random programs that do not rely on embedding approximations. To demonstrate their usefulness, we compare two publicly available models: ChatGPT-4 and TinyLlama, on a simple problem related to image processing. Application areas include understanding how questions should be asked to obtain useful programs; measuring how consistently a given large language model answers; and comparing the different large language models as a programming assistant. Finally, we speculate that our approach may in the future give new insights into the structure of programming languages.