Not (yet) the whole story: Evaluating Visual Storytelling Requires More than Measuring Coherence, Grounding, and Repetition
作者: Aditya K Surikuchi, Raquel Fernández, Sandro Pezzelle
分类: cs.CL, cs.AI, cs.CV, cs.LG
发布日期: 2024-07-05 (更新: 2024-10-25)
备注: In proceedings of EMNLP 2024 (Findings)
💡 一句话要点
提出一种基于人类相似性的视觉故事生成评估方法,揭示现有指标的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉故事生成 评估指标 人类相似性 视觉基础 连贯性 重复性 多模态学习
📋 核心要点
- 现有视觉故事生成评估指标缺乏对故事“好坏”的共识,难以准确衡量模型性能。
- 提出一种基于人类相似性的评估方法,从视觉基础、连贯性和重复性三个关键方面衡量故事质量。
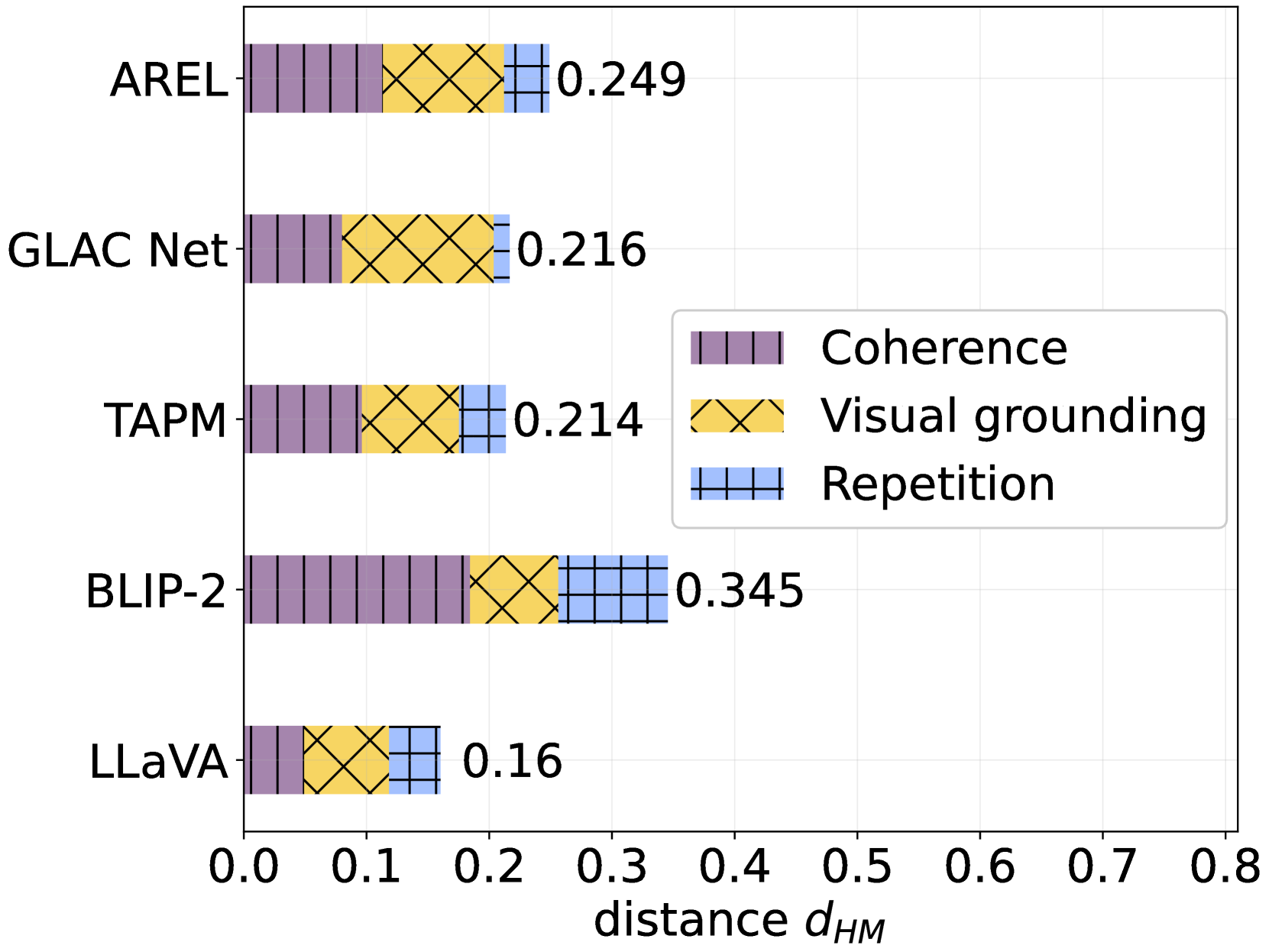
- 实验表明,大型模型LLaVA表现最佳,但优势不明显,小型模型TAPM通过组件升级可获得竞争性性能。
📝 摘要(中文)
视觉故事生成是指根据时间顺序排列的图像序列生成自然语言故事。这项任务不仅对模型具有挑战性,而且使用自动指标进行评估也非常困难,因为对于什么构成一个“好”故事没有共识。本文介绍了一种新颖的方法,该方法根据人类相似性来衡量故事质量,重点关注先前工作中强调的三个关键方面:视觉基础、连贯性和重复性。然后,我们使用此方法来评估多个模型生成的故事,结果表明,基础模型LLaVA获得了最佳结果,但与TAPM(一个体积小50倍的视觉故事生成模型)相比,优势并不明显。升级TAPM的视觉和语言组件可以得到一个性能具有竞争力的模型,且参数数量相对较少。最后,我们进行了一项人工评估研究,结果表明,一个“好”的故事可能需要的不仅仅是人类水平的视觉基础、连贯性和重复性。
🔬 方法详解
问题定义:视觉故事生成任务旨在根据一系列有序的图像生成连贯且自然的文本故事。现有的自动评估指标,如BLEU、ROUGE等,主要关注文本相似度,无法有效衡量故事的视觉基础、连贯性和人类相似性,导致评估结果与人类感知存在偏差。因此,如何设计更符合人类认知的评估指标是当前面临的挑战。
核心思路:本文的核心思路是借鉴人类的判断标准,通过衡量生成故事在视觉基础、连贯性和重复性三个方面与人类生成故事的相似程度来评估故事质量。这种方法试图弥合机器评估与人类感知的差距,从而更准确地反映模型生成故事的优劣。
技术框架:该方法主要包含以下几个步骤:1) 使用不同的视觉故事生成模型生成故事;2) 针对每个生成的故事,提取视觉基础、连贯性和重复性三个方面的特征;3) 将这些特征与人类生成故事的对应特征进行比较,计算相似度得分;4) 综合三个方面的相似度得分,得到最终的故事质量评估结果。具体来说,视觉基础可能通过图像描述符的相似度来衡量,连贯性可能通过语言模型的困惑度或相邻句子之间的语义相似度来衡量,重复性则可以通过统计n-gram的重复次数来衡量。
关键创新:该方法的关键创新在于将人类相似性引入视觉故事生成的评估过程。以往的自动评估指标主要关注文本层面的相似度,忽略了故事的视觉基础和连贯性等重要因素。通过衡量生成故事与人类生成故事在关键特征上的相似程度,该方法能够更准确地反映故事的质量,并为模型改进提供更有价值的反馈。
关键设计:论文的关键设计可能包括:1) 如何选择合适的特征来衡量视觉基础、连贯性和重复性;2) 如何设计相似度计算方法,以准确反映生成故事与人类生成故事之间的差异;3) 如何综合三个方面的相似度得分,得到最终的故事质量评估结果。具体的参数设置、损失函数和网络结构等细节未知,需要参考论文原文。
🖼️ 关键图片


📊 实验亮点
实验结果表明,大型预训练模型LLaVA在人类相似性评估指标上表现最佳,但与小型模型TAPM相比优势不明显。通过升级TAPM的视觉和语言组件,可以使其性能与LLaVA相媲美,表明小型模型在视觉故事生成方面仍有潜力。人工评估结果进一步表明,仅关注视觉基础、连贯性和重复性可能不足以全面评估故事质量。
🎯 应用场景
该研究成果可应用于视觉故事生成模型的评估与改进,推动视觉叙事技术的发展。更准确的评估指标有助于模型更好地理解图像内容,生成更具吸引力和连贯性的故事。此外,该方法也可推广到其他多模态生成任务的评估中,例如视频描述、图像字幕等。
📄 摘要(原文)
Visual storytelling consists in generating a natural language story given a temporally ordered sequence of images. This task is not only challenging for models, but also very difficult to evaluate with automatic metrics since there is no consensus about what makes a story 'good'. In this paper, we introduce a novel method that measures story quality in terms of human likeness regarding three key aspects highlighted in previous work: visual grounding, coherence, and repetitiveness. We then use this method to evaluate the stories generated by several models, showing that the foundation model LLaVA obtains the best result, but only slightly so compared to TAPM, a 50-times smaller visual storytelling model. Upgrading the visual and language components of TAPM results in a model that yields competitive performance with a relatively low number of parameters. Finally, we carry out a human evaluation study, whose results suggest that a 'good' story may require more than a human-like level of visual grounding, coherence, and repetition.