MS2SL: Multimodal Spoken Data-Driven Continuous Sign Language Production
作者: Jian Ma, Wenguan Wang, Yi Yang, Feng Zheng
分类: cs.CL, cs.AI
发布日期: 2024-07-04
备注: Accepted to ACL 2024 Findings; Project Page: https://hechang25.github.io/MS2SL
💡 一句话要点
提出MS2SL框架,利用多模态信息生成连续手语序列
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 连续手语生成 序列扩散模型 多模态融合 联合嵌入空间 一致性学习
📋 核心要点
- 现有方法难以直接从完整的口语内容(如文本或语音)生成手语序列,阻碍了手语交流。
- 提出MS2SL框架,利用序列扩散模型,通过文本或语音嵌入逐步生成手语,实现连续手语生成。
- 通过多模态联合嵌入和一致性学习,模型在How2Sign和PHOENIX14T数据集上取得了有竞争力的性能。
📝 摘要(中文)
本文提出了一种统一的连续手语生成框架,旨在促进手语使用者和非手语使用者之间的交流。该框架利用序列扩散模型,逐步生成手语预测,其输入为从文本或语音中提取的嵌入向量。此外,通过构建文本、音频和手语的联合嵌入空间,将这些模态联系起来,并利用它们之间的语义一致性,为模型训练提供信息丰富的反馈。这种嵌入一致性学习策略最大限度地减少了对手语三元组的依赖,并确保即使在缺少音频模态的情况下也能持续改进模型。在How2Sign和PHOENIX14T数据集上的实验表明,我们的模型在手语生成方面取得了具有竞争力的性能。
🔬 方法详解
问题定义:论文旨在解决从口语内容(文本或语音)直接生成连续手语序列的问题。现有的手语生成方法通常依赖于孤立的手语词汇或需要大量的手语-文本/语音对齐数据,难以处理自然流畅的连续手语生成任务。此外,如何有效地利用文本、语音和手语之间的语义关联也是一个挑战。
核心思路:论文的核心思路是利用序列扩散模型逐步生成手语序列,并结合多模态联合嵌入和一致性学习来提升生成质量。通过将文本、语音和手语映射到同一个嵌入空间,模型可以学习它们之间的语义关联,从而在生成手语时能够更好地利用这些信息。这种方法减少了对手语三元组的依赖,并且即使在缺少音频模态的情况下也能进行训练。
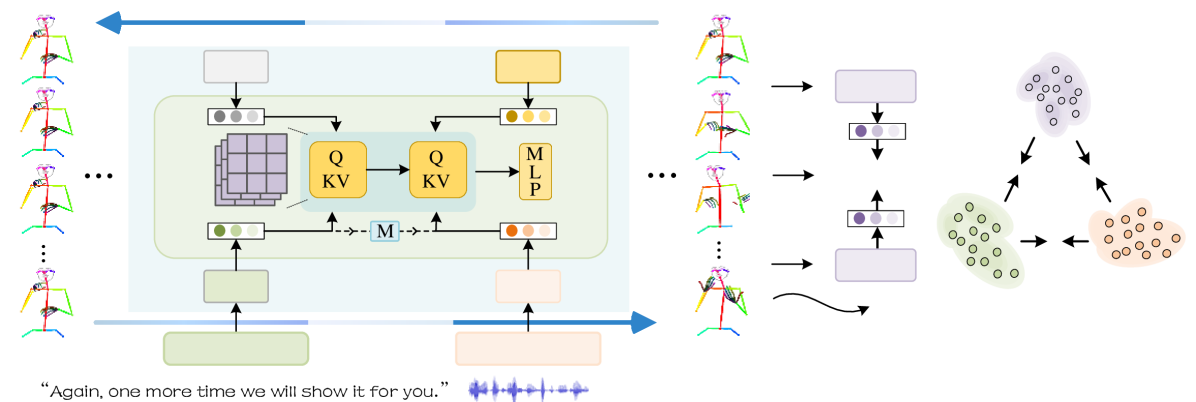
技术框架:MS2SL框架主要包含以下几个模块:1) 文本/语音编码器:用于提取文本或语音的嵌入向量。2) 序列扩散模型:以编码器的输出为条件,逐步生成手语序列。该模型通过迭代地添加噪声并进行去噪,最终生成高质量的手语序列。3) 多模态联合嵌入模块:将文本、语音和手语映射到同一个嵌入空间,学习它们之间的语义关联。4) 一致性学习模块:利用多模态嵌入空间中的语义一致性,为模型训练提供反馈,提升生成质量。
关键创新:论文的关键创新在于:1) 提出了一种基于序列扩散模型的连续手语生成框架,能够直接从文本或语音生成自然流畅的手语序列。2) 引入了多模态联合嵌入和一致性学习策略,有效地利用了文本、语音和手语之间的语义关联,提升了生成质量,并减少了对手语三元组的依赖。
关键设计:序列扩散模型采用U-Net结构,以文本/语音嵌入作为条件输入。损失函数包括扩散模型的标准损失和一致性学习损失。一致性学习损失旨在最小化文本、语音和手语在联合嵌入空间中的距离,鼓励模型学习它们之间的语义关联。具体的参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
MS2SL模型在How2Sign和PHOENIX14T数据集上取得了具有竞争力的性能。具体指标(如BLEU score、ROUGE score等)和与现有方法的对比数据在论文中有详细描述(未知)。实验结果表明,该模型能够生成自然流畅的手语序列,并且在缺少音频模态的情况下也能保持较好的性能。
🎯 应用场景
该研究成果可应用于开发手语翻译系统、手语教学工具和辅助沟通设备,从而促进听障人士与健听人士之间的交流。未来,该技术有望应用于智能客服、在线教育等领域,为听障人士提供更便捷、更高效的服务。
📄 摘要(原文)
Sign language understanding has made significant strides; however, there is still no viable solution for generating sign sequences directly from entire spoken content, e.g., text or speech. In this paper, we propose a unified framework for continuous sign language production, easing communication between sign and non-sign language users. In particular, a sequence diffusion model, utilizing embeddings extracted from text or speech, is crafted to generate sign predictions step by step. Moreover, by creating a joint embedding space for text, audio, and sign, we bind these modalities and leverage the semantic consistency among them to provide informative feedback for the model training. This embedding-consistency learning strategy minimizes the reliance on sign triplets and ensures continuous model refinement, even with a missing audio modality. Experiments on How2Sign and PHOENIX14T datasets demonstrate that our model achieves competitive performance in sign language production.