Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models
作者: Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, Yanghua Xiao
分类: cs.CL, cs.AI
发布日期: 2024-07-04
备注: Accepted to CIKM 2023 (Long Paper)
💡 一句话要点
提出RelD:一种鲁棒的LLM幻觉检测器,提升答案可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 问答系统 判别器 鲁棒性 RelQA数据集 自然语言处理
📋 核心要点
- 大型语言模型易产生幻觉,生成与输入不符的内容,降低了其在问答等任务中的可靠性。
- 论文提出RelD判别器,通过在RelQA数据集上训练,学习区分LLM生成答案中的幻觉。
- 实验表明RelD能有效检测多种LLM的幻觉,并在分布内和分布外数据集上均表现良好。
📝 摘要(中文)
大型语言模型(LLMs)在问答和对话系统等自然语言处理任务中得到广泛应用。然而,LLMs的一个主要缺点是幻觉问题,即生成不忠实或不一致的内容,偏离输入源,导致严重后果。本文提出了一种名为RelD的鲁棒判别器,以有效检测LLMs生成答案中的幻觉。RelD是在构建的RelQA(一个双语问答对话数据集)上,以及LLMs生成的答案和一套综合指标上进行训练的。实验结果表明,所提出的RelD成功地检测出各种LLMs生成答案中的幻觉。此外,它在区分LLMs生成答案中的幻觉方面表现良好,无论是在分布内还是分布外的数据集上。此外,我们还对发生的幻觉类型进行了彻底的分析,并提出了有价值的见解。这项研究显著促进了LLMs生成可靠答案的检测,并对未来工作中减轻幻觉具有重要意义。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成答案时出现的幻觉问题。现有方法在检测LLM幻觉方面存在不足,难以准确区分真实信息和模型虚构的内容,尤其是在面对分布外数据时,鲁棒性较差。这严重影响了LLM在实际应用中的可靠性。
核心思路:论文的核心思路是训练一个专门的判别器RelD,使其能够区分LLM生成的答案中哪些是可靠的,哪些是幻觉。RelD通过学习LLM生成答案的特征,并结合一系列指标,判断答案与输入源的一致性和真实性。这种方法旨在提高幻觉检测的准确性和鲁棒性。
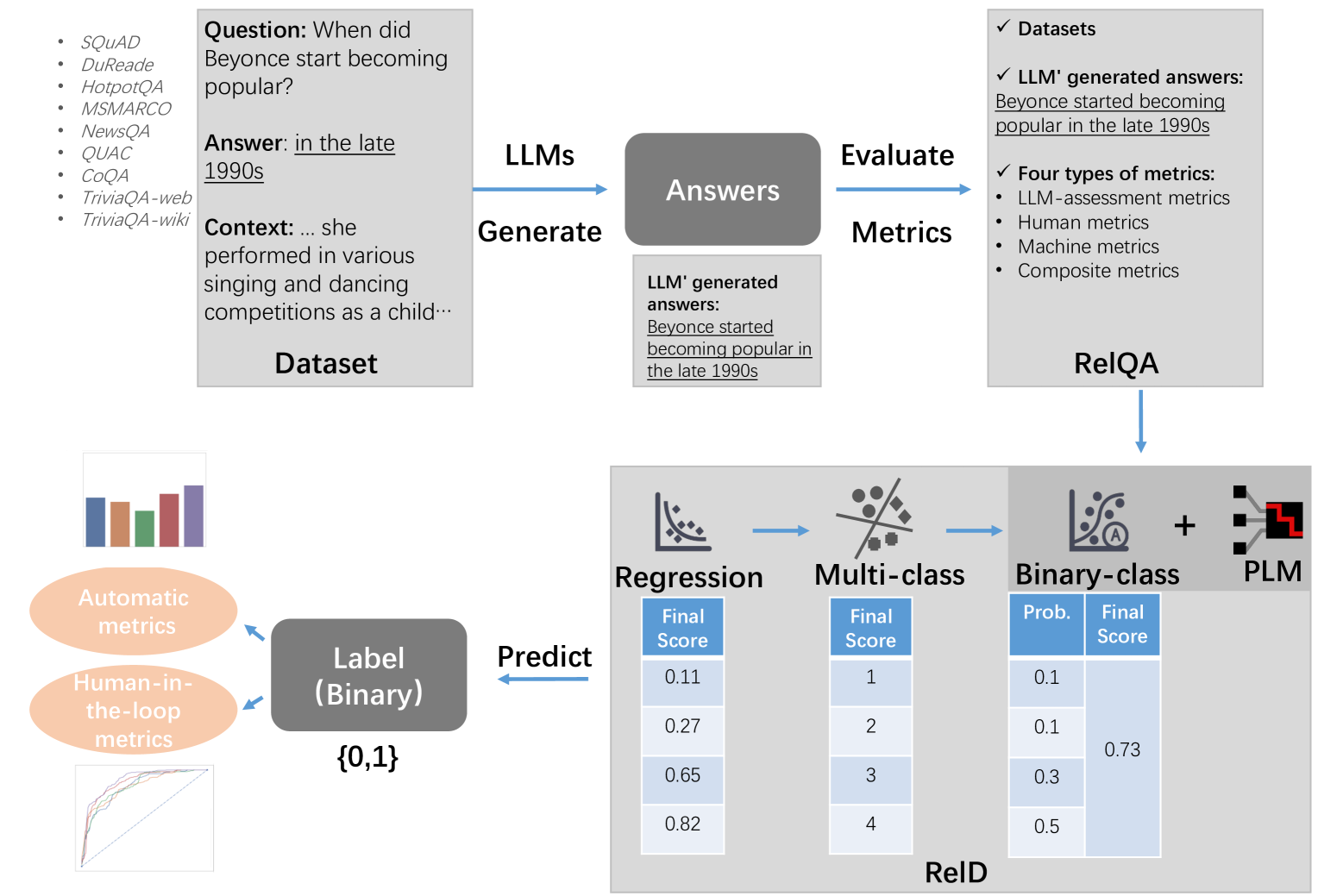
技术框架:RelD的训练过程主要依赖于构建的RelQA数据集,该数据集包含双语问答对话数据以及LLM生成的答案。训练过程中,RelD学习区分真实答案和包含幻觉的答案。整体流程包括:1) 构建RelQA数据集;2) 使用LLM生成答案;3) 提取答案特征并计算相关指标;4) 训练RelD判别器;5) 评估RelD在不同数据集上的性能。
关键创新:论文的关键创新在于提出了RelD判别器,并结合RelQA数据集进行训练。RelD不仅考虑了答案本身的内容,还结合了一系列指标来判断答案的可靠性。此外,RelQA数据集的构建也为幻觉检测研究提供了新的资源。与现有方法相比,RelD更注重答案与输入源的一致性,从而提高了幻觉检测的准确性和鲁棒性。
关键设计:RelD的具体实现细节未知,论文中可能没有详细描述网络结构、损失函数等。但可以推测,RelD可能采用了某种神经网络结构,例如Transformer或BERT等,并使用交叉熵损失函数进行训练。RelQA数据集的构建可能涉及多种数据增强技术,以提高RelD的泛化能力。具体指标的选择可能包括ROUGE、BLEU等,用于衡量答案与输入源的相似度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RelD能够有效检测多种LLM生成的答案中的幻觉,并在分布内和分布外数据集上均表现良好。具体的性能数据和提升幅度未知,但论文强调RelD在区分幻觉方面的鲁棒性,表明其优于现有方法。此外,论文还对发生的幻觉类型进行了分析,为未来的研究提供了有价值的见解。
🎯 应用场景
该研究成果可应用于各种基于大型语言模型的问答系统、对话系统和信息检索系统,提高生成内容的可靠性和准确性。通过有效检测和减轻幻觉,可以增强用户对LLM的信任,并促进LLM在医疗、金融等关键领域的应用。未来,该技术还可用于评估和改进LLM的训练过程,从而从根本上减少幻觉的产生。
📄 摘要(原文)
Large Language Models (LLMs) have gained widespread adoption in various natural language processing tasks, including question answering and dialogue systems. However, a major drawback of LLMs is the issue of hallucination, where they generate unfaithful or inconsistent content that deviates from the input source, leading to severe consequences. In this paper, we propose a robust discriminator named RelD to effectively detect hallucination in LLMs' generated answers. RelD is trained on the constructed RelQA, a bilingual question-answering dialogue dataset along with answers generated by LLMs and a comprehensive set of metrics. Our experimental results demonstrate that the proposed RelD successfully detects hallucination in the answers generated by diverse LLMs. Moreover, it performs well in distinguishing hallucination in LLMs' generated answers from both in-distribution and out-of-distribution datasets. Additionally, we also conduct a thorough analysis of the types of hallucinations that occur and present valuable insights. This research significantly contributes to the detection of reliable answers generated by LLMs and holds noteworthy implications for mitigating hallucination in the future work.