LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking
作者: Amy Xin, Yunjia Qi, Zijun Yao, Fangwei Zhu, Kaisheng Zeng, Xu Bin, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2024-07-04 (更新: 2025-09-26)
💡 一句话要点
LLMAEL:利用大语言模型增强实体链接的上下文信息,显著提升链接准确率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实体链接 大语言模型 上下文增强 长尾实体 知识库 信息抽取
📋 核心要点
- 现有实体链接模型在处理长尾实体时面临挑战,因为训练数据不足,导致消歧能力有限。
- LLMAEL框架利用大语言模型生成实体描述,作为上下文信息增强专业实体链接模型,无需对LLM进行微调。
- 实验表明,LLMAEL在多个基准数据集上显著提升了实体链接的准确率,超越了现有最佳方法。
📝 摘要(中文)
本文提出了一种名为LLM-Augmented Entity Linking (LLMAEL) 的框架,旨在利用大语言模型(LLMs)增强专业实体链接(EL)模型。现有的EL模型在将提及项映射到知识库(KB)实体时表现良好,但由于训练数据有限,难以消歧长尾实体。LLMs虽然拥有广泛的知识,但缺乏专门的EL训练,难以生成准确的KB实体名称。LLMAEL利用LLMs擅长生成上下文的优势,将其作为上下文增强器,生成实体描述作为专业EL模型的额外输入。实验结果表明,LLMAEL在6个广泛使用的EL基准测试中取得了新的state-of-the-art结果,相比于其他将无调优LLMs集成到EL中的方法,EL准确率绝对提升了8.9%。代码和数据集已开源。
🔬 方法详解
问题定义:论文旨在解决现有实体链接模型在处理长尾实体时,由于训练数据不足而导致的链接准确率低的问题。现有方法要么依赖于有限的训练数据,要么直接使用LLM进行实体链接,但LLM缺乏专门的训练,无法准确生成KB实体名称。
核心思路:论文的核心思路是利用LLM擅长生成上下文描述的优势,将LLM作为上下文增强器,为专业实体链接模型提供更丰富的上下文信息。通过增强上下文,提高模型对长尾实体的消歧能力。
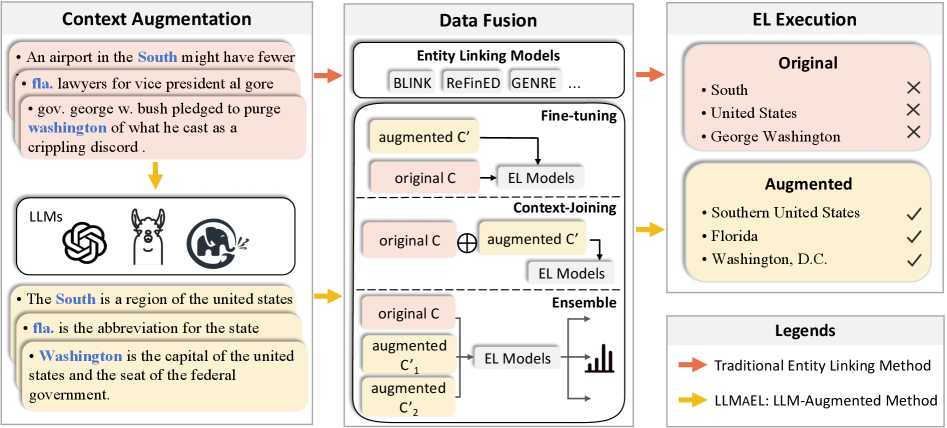
技术框架:LLMAEL框架包含两个主要阶段:1) 上下文增强阶段:利用预训练的LLM,根据给定的mention生成实体描述。这个阶段不需要对LLM进行任何微调。2) 实体链接阶段:将生成的实体描述作为额外输入,输入到专业的实体链接模型中,进行实体链接。整体流程是先用LLM生成上下文,再用专业模型进行链接。
关键创新:LLMAEL的关键创新在于将LLM的角色从直接执行实体链接任务转变为上下文增强器。这种方法充分利用了LLM的知识广度,同时避免了LLM在实体链接任务上的不足。与直接使用LLM进行实体链接相比,LLMAEL可以更好地利用专业实体链接模型的训练数据。
关键设计:LLMAEL的关键设计在于如何有效地利用LLM生成高质量的实体描述。论文中使用了prompt engineering来引导LLM生成更准确、更相关的实体描述。具体的prompt设计和LLM的选择(例如,使用哪个开源LLM)是影响最终性能的关键因素。此外,如何将生成的上下文信息有效地融入到专业实体链接模型中,也是一个重要的设计考虑。
🖼️ 关键图片

📊 实验亮点
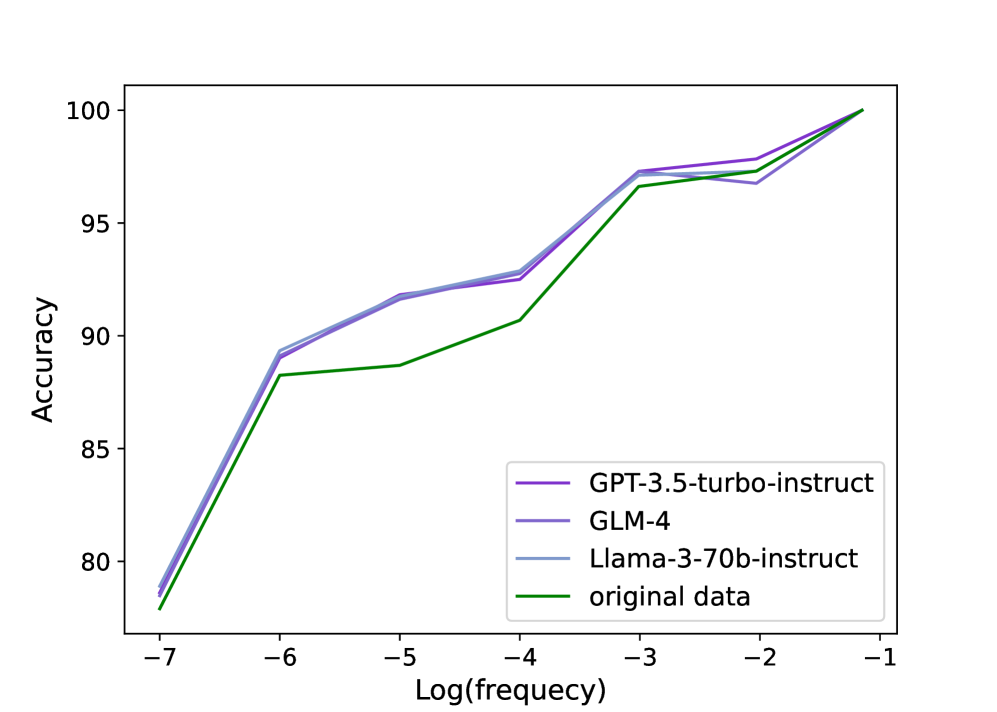
LLMAEL在6个广泛使用的实体链接基准数据集上取得了state-of-the-art的结果。与之前最好的无调优LLM集成方法相比,LLMAEL在实体链接准确率上实现了8.9%的绝对提升。这些结果表明,LLMAEL是一种有效的实体链接增强方法,尤其是在处理长尾实体时。
🎯 应用场景
LLMAEL框架可应用于各种需要实体链接的场景,例如信息抽取、知识图谱构建、问答系统等。通过提高长尾实体的链接准确率,可以提升这些应用在处理复杂和不常见实体时的性能。该方法具有广泛的应用前景,尤其是在需要处理大量非结构化文本数据的领域。
📄 摘要(原文)
Specialized entity linking (EL) models are well-trained at mapping mentions to unique knowledge base (KB) entities according to a given context. However, specialized EL models struggle to disambiguate long-tail entities due to their limited training data. Meanwhile, extensively pre-trained large language models (LLMs) possess broader knowledge of uncommon entities. Yet, with a lack of specialized EL training, LLMs frequently fail to generate accurate KB entity names, limiting their standalone effectiveness in EL. With the observation that LLMs are more adept at context generation instead of EL execution, we introduce LLM-Augmented Entity Linking (LLMAEL), the first framework to enhance specialized EL models with LLM data augmentation. LLMAEL leverages off-the-shelf, tuning-free LLMs as context augmenters, generating entity descriptions to serve as additional input for specialized EL models. Experiments show that LLMAEL sets new state-of-the-art results across 6 widely adopted EL benchmarks: compared to prior methods that integrate tuning-free LLMs into EL, LLMAEL achieves an absolute 8.9% gain in EL accuracy. We release our code and datasets.