Benchmarking Complex Instruction-Following with Multiple Constraints Composition
作者: Bosi Wen, Pei Ke, Xiaotao Gu, Lindong Wu, Hao Huang, Jinfeng Zhou, Wenchuang Li, Binxin Hu, Wendy Gao, Jiaxin Xu, Yiming Liu, Jie Tang, Hongning Wang, Minlie Huang
分类: cs.CL, cs.AI
发布日期: 2024-07-04 (更新: 2024-10-31)
备注: NeurIPS 2024 Datasets and Benchmarks Track
💡 一句话要点
提出ComplexBench,用于评估LLM在多约束组合下的复杂指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令遵循 大型语言模型 基准测试 约束组合 复杂指令
📋 核心要点
- 现有基准测试忽略了复杂指令中不同约束的组合,无法全面评估LLM的指令遵循能力。
- ComplexBench通过分层分类法对复杂指令进行建模,并手动构建高质量数据集。
- 该基准使用规则增强的LLM评估器,并根据约束依赖结构计算最终分数,从而实现可靠评估。
📝 摘要(中文)
指令遵循是大型语言模型(LLMs)的一项基本能力。随着LLMs能力的不断提高,它们越来越多地被应用于处理现实场景中复杂的人类指令。因此,如何评估LLMs的复杂指令遵循能力已成为一个关键的研究问题。现有的基准主要侧重于对人类指令中不同类型的约束进行建模,而忽略了不同约束的组合,这是复杂指令中不可或缺的组成部分。为此,我们提出了ComplexBench,这是一个用于全面评估LLMs遵循由多个约束组成的复杂指令能力的基准。我们为复杂指令提出了一个分层分类法,包括4种约束类型、19个约束维度和4种组合类型,并相应地手动收集了一个高质量的数据集。为了使评估可靠,我们使用规则增强了基于LLM的评估器,以有效地验证生成的文本是否可以满足每个约束和组合。此外,我们基于由不同组合类型确定的依赖结构获得最终评估分数。ComplexBench 揭示了现有LLMs在处理具有多个约束组合的复杂指令时存在的重大缺陷。
🔬 方法详解
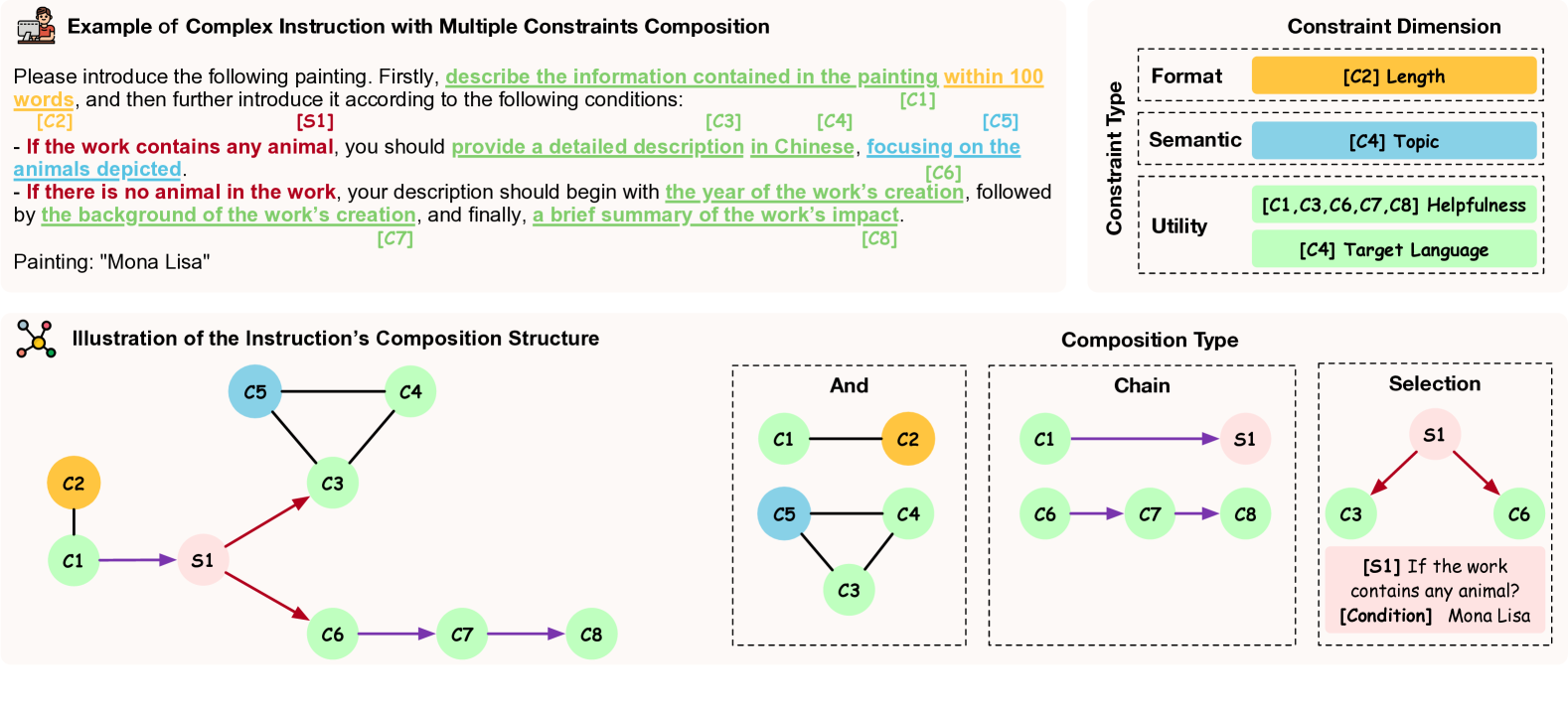
问题定义:现有的大语言模型指令遵循评测基准,主要关注指令中不同类型的约束,但是忽略了真实场景中,复杂指令往往是多个约束组合而成。因此,现有方法无法有效评估LLM在复杂约束组合下的指令遵循能力,存在评估不全面的问题。
核心思路:ComplexBench的核心思路是构建一个包含多种约束类型和组合方式的基准数据集,并设计相应的评估方法,从而全面评估LLM在复杂指令下的表现。通过分层分类法对约束进行建模,并利用规则增强的LLM评估器,提高评估的准确性和可靠性。
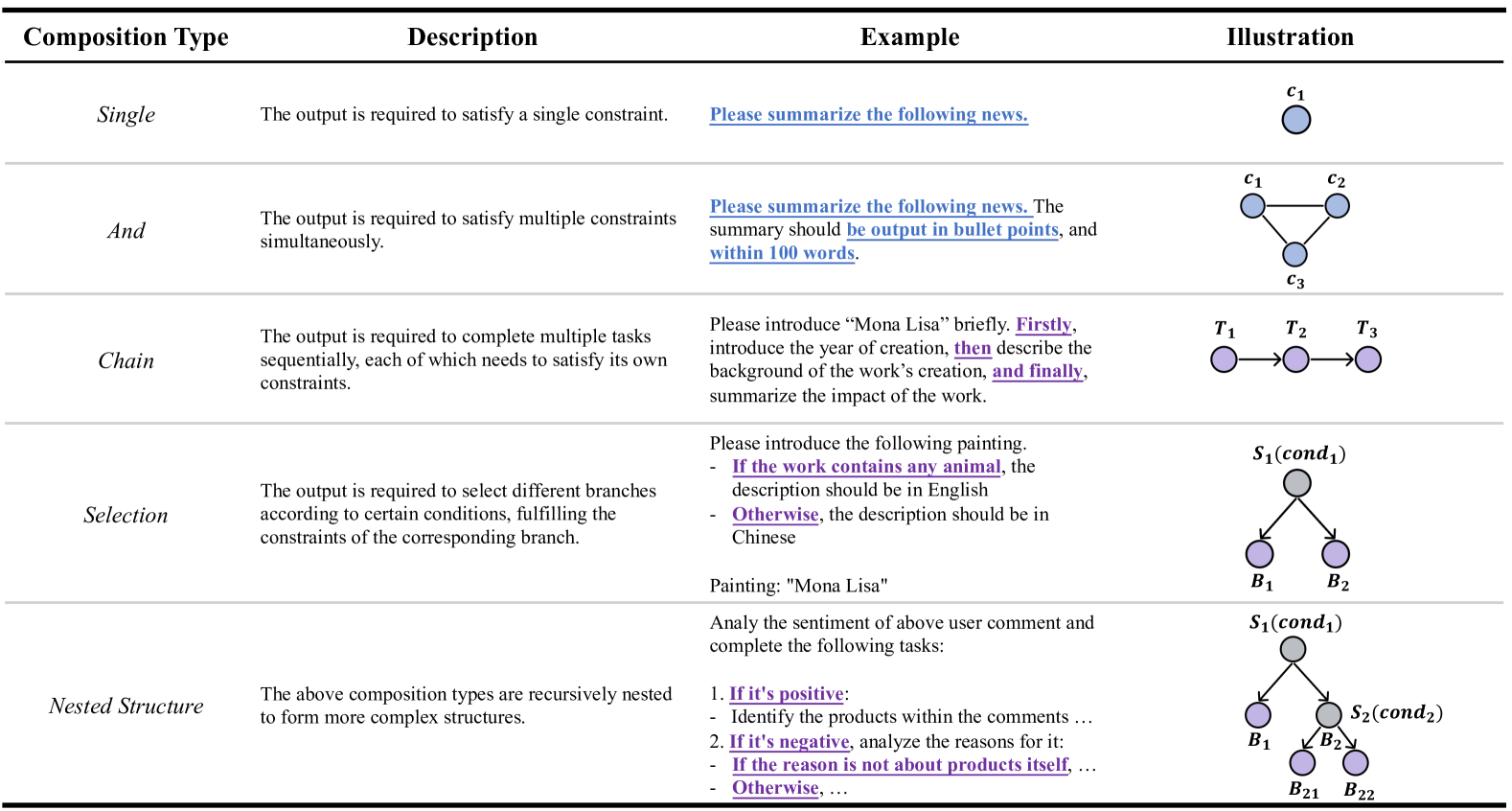
技术框架:ComplexBench的整体框架包括以下几个主要部分: 1. 分层分类法:定义了4种约束类型、19个约束维度和4种组合类型,用于对复杂指令进行建模。 2. 数据集构建:手动收集高质量的数据集,包含各种约束类型和组合方式的复杂指令。 3. 评估器设计:使用LLM作为评估器,并使用规则进行增强,以验证生成的文本是否满足每个约束和组合。 4. 评分机制:基于约束之间的依赖结构,计算最终的评估分数。
关键创新:ComplexBench的关键创新在于: 1. 关注约束组合:首次关注复杂指令中多个约束的组合,更贴近真实应用场景。 2. 分层分类法:提出了一个分层的约束分类体系,能够更细粒度地描述复杂指令。 3. 规则增强评估:通过规则增强LLM评估器,提高了评估的准确性和可靠性。
关键设计:ComplexBench的关键设计包括: 1. 约束类型:定义了时间约束、空间约束、数量约束和属性约束四种约束类型。 2. 组合类型:定义了顺序组合、条件组合、嵌套组合和并列组合四种组合类型。 3. 评估规则:针对每种约束类型和组合类型,设计了相应的评估规则,用于验证生成的文本是否满足约束。
🖼️ 关键图片
📊 实验亮点
ComplexBench的实验结果表明,现有LLM在处理具有多个约束组合的复杂指令时存在显著缺陷。例如,在某些约束组合类型上,LLM的性能远低于预期。该基准的发布有助于推动LLM在复杂指令遵循方面的研究进展,并促进更智能、更可靠的LLM的开发。
🎯 应用场景
ComplexBench可用于评估和提升LLM在各种实际应用场景中的指令遵循能力,例如智能助手、对话系统、机器人控制等。通过该基准,可以更好地了解LLM在处理复杂任务时的优势和不足,并指导LLM的训练和优化,使其更好地服务于人类。
📄 摘要(原文)
Instruction following is one of the fundamental capabilities of large language models (LLMs). As the ability of LLMs is constantly improving, they have been increasingly applied to deal with complex human instructions in real-world scenarios. Therefore, how to evaluate the ability of complex instruction-following of LLMs has become a critical research problem. Existing benchmarks mainly focus on modeling different types of constraints in human instructions while neglecting the composition of different constraints, which is an indispensable constituent in complex instructions. To this end, we propose ComplexBench, a benchmark for comprehensively evaluating the ability of LLMs to follow complex instructions composed of multiple constraints. We propose a hierarchical taxonomy for complex instructions, including 4 constraint types, 19 constraint dimensions, and 4 composition types, and manually collect a high-quality dataset accordingly. To make the evaluation reliable, we augment LLM-based evaluators with rules to effectively verify whether generated texts can satisfy each constraint and composition. Furthermore, we obtain the final evaluation score based on the dependency structure determined by different composition types. ComplexBench identifies significant deficiencies in existing LLMs when dealing with complex instructions with multiple constraints composition.