ChatSOP: An SOP-Guided MCTS Planning Framework for Controllable LLM Dialogue Agents
作者: Zhigen Li, Jianxiang Peng, Yanmeng Wang, Yong Cao, Tianhao Shen, Minghui Zhang, Linxi Su, Shang Wu, Yihang Wu, Yuqian Wang, Ye Wang, Wei Hu, Jianfeng Li, Shaojun Wang, Jing Xiao, Deyi Xiong
分类: cs.CL, cs.AI
发布日期: 2024-07-04 (更新: 2025-02-22)
💡 一句话要点
ChatSOP:一种SOP引导的MCTS规划框架,用于可控LLM对话Agent
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话Agent 大型语言模型 可控性 标准操作程序 蒙特卡洛树搜索
📋 核心要点
- 现有LLM对话Agent缺乏可控性,导致对话主题分散或任务失败。
- ChatSOP利用标准操作程序(SOP)引导对话流程,提升LLM对话Agent的可控性。
- 实验表明,ChatSOP在动作准确率上优于GPT-3.5基线模型27.95%,并在开源模型上也有提升。
📝 摘要(中文)
本文提出了一种名为ChatSOP的、基于标准操作程序(SOP)引导的蒙特卡洛树搜索(MCTS)规划框架,旨在增强大型语言模型(LLM)驱动的对话Agent的可控性。为了实现这一目标,作者构建了一个包含SOP标注的多场景对话数据集,该数据集通过GPT-4o的半自动角色扮演系统生成,并通过严格的人工质量控制进行验证。此外,论文提出了一种新方法,该方法将思维链推理与监督微调相结合,用于SOP预测,并利用SOP引导的蒙特卡洛树搜索进行对话期间的最佳动作规划。实验结果表明,该方法有效,例如,与基于GPT-3.5的基线模型相比,动作准确率提高了27.95%,并且开源模型也显示出显著的提升。数据集和代码已公开。
🔬 方法详解
问题定义:现有基于LLM的对话Agent虽然在用户理解和生成类人回复方面表现出色,但缺乏可控性,容易导致对话偏离主题或无法完成既定任务。现有的方法难以有效地引导对话流程,使其按照预定的目标进行。
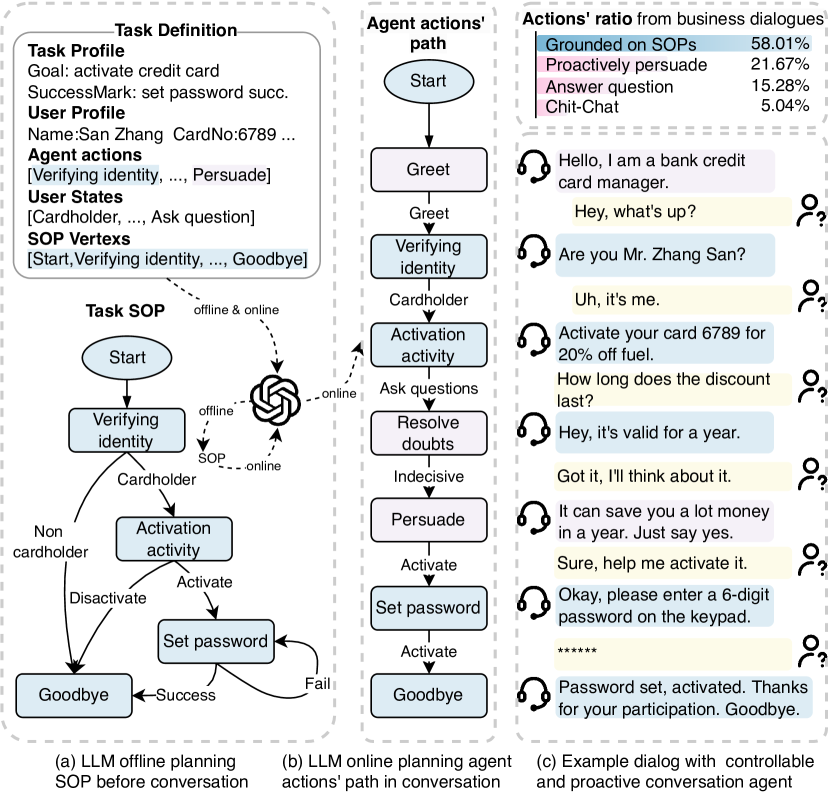
核心思路:ChatSOP的核心思路是引入标准操作程序(SOP)来规范对话流程。通过将对话过程分解为一系列明确的步骤,并利用SOP来指导Agent的决策,从而提高对话的可控性和目标导向性。这种方法借鉴了人类在执行复杂任务时遵循SOP的习惯。
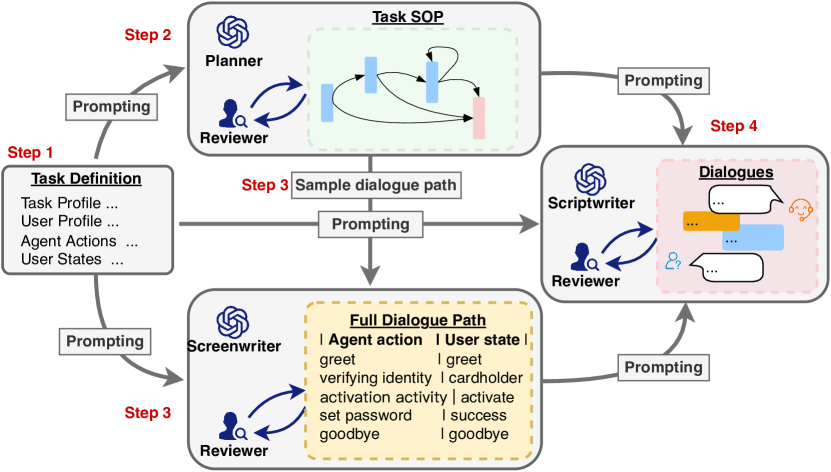
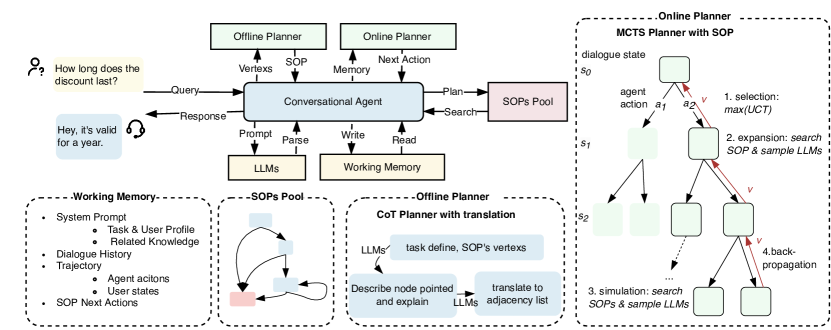
技术框架:ChatSOP框架主要包含以下几个模块:1) SOP预测模块:利用Chain of Thought推理和监督微调,预测当前对话状态下应该执行的SOP步骤。2) MCTS规划模块:基于预测的SOP步骤,使用蒙特卡洛树搜索(MCTS)来规划最佳的动作序列。MCTS利用LLM作为模拟器,评估不同动作序列的潜在结果,并选择最优的动作。3) 对话生成模块:根据MCTS选择的动作,生成相应的对话回复。
关键创新:ChatSOP的关键创新在于将SOP与MCTS相结合,用于控制LLM对话Agent的对话流程。传统的MCTS方法通常依赖于启发式规则或人工设计的奖励函数,而ChatSOP利用SOP作为先验知识,指导MCTS的搜索过程,从而提高了规划效率和对话质量。此外,论文还提出了一种新的SOP预测方法,该方法结合了Chain of Thought推理和监督微调,提高了SOP预测的准确性。
关键设计:SOP预测模块使用基于Transformer的序列到序列模型,并采用Chain of Thought推理来提高预测的准确性。MCTS模块使用LLM作为模拟器,评估不同动作序列的奖励。奖励函数的设计考虑了对话的流畅性、目标完成度和SOP的遵循程度。具体参数设置和损失函数细节在论文中有详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ChatSOP在动作准确率方面显著优于基线模型。与基于GPT-3.5的基线模型相比,ChatSOP的动作准确率提高了27.95%。此外,ChatSOP在开源模型上也取得了显著的性能提升,证明了该方法的通用性和有效性。这些结果表明,SOP引导的MCTS规划框架可以有效地提高LLM对话Agent的可控性。
🎯 应用场景
ChatSOP可应用于各种需要可控对话Agent的场景,例如客户服务、智能助手、教育辅导等。通过SOP的引导,Agent可以更有效地完成任务,提供更一致和可靠的服务。该研究有助于提升人机交互的效率和用户体验,并为开发更智能、更可控的对话系统奠定基础。
📄 摘要(原文)
Dialogue agents powered by Large Language Models (LLMs) show superior performance in various tasks. Despite the better user understanding and human-like responses, their lack of controllability remains a key challenge, often leading to unfocused conversations or task failure. To address this, we introduce Standard Operating Procedure (SOP) to regulate dialogue flow. Specifically, we propose ChatSOP, a novel SOP-guided Monte Carlo Tree Search (MCTS) planning framework designed to enhance the controllability of LLM-driven dialogue agents. To enable this, we curate a dataset comprising SOP-annotated multi-scenario dialogues, generated using a semi-automated role-playing system with GPT-4o and validated through strict manual quality control. Additionally, we propose a novel method that integrates Chain of Thought reasoning with supervised fine-tuning for SOP prediction and utilizes SOP-guided Monte Carlo Tree Search for optimal action planning during dialogues. Experimental results demonstrate the effectiveness of our method, such as achieving a 27.95% improvement in action accuracy compared to baseline models based on GPT-3.5 and also showing notable gains for open-source models. Dataset and codes are publicly available.