Convolutional vs Large Language Models for Software Log Classification in Edge-Deployable Cellular Network Testing
作者: Achintha Ihalage, Sayed M. Taheri, Faris Muhammad, Hamed Al-Raweshidy
分类: cs.CL, cs.AI, cs.LG, cs.NI
发布日期: 2024-07-04
💡 一句话要点
提出一种紧凑型CNN,用于边缘部署的蜂窝网络测试中软件日志分类,显著优于LLM。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 软件日志分类 卷积神经网络 边缘计算 电信网络测试 缺陷分流
📋 核心要点
- 电信软件日志复杂且规模庞大,传统专家人工分析效率低,现有LLM存在上下文窗口限制和成本高等问题。
- 提出一种紧凑型CNN架构,扩展上下文窗口至20万字符,专门用于电信协议栈软件日志分类和缺陷分流。
- 实验结果表明,该CNN模型在准确率和F1值上均超过96%,显著优于多种LLM,且易于边缘部署。
📝 摘要(中文)
本文提出了一种用于电信行业复杂软件日志分类的紧凑型卷积神经网络(CNN)架构。这些日志由VIAVI TM500等网络模拟器生成,包含数万行文本,与自然语言差异很大,需要专家工程师进行故障排除。尽管大型语言模型(LLM)为自动化缺陷分类提供了潜力,但它们存在上下文窗口受限、不适用于非自然语言文本以及推理成本高等缺点。本文提出的CNN模型具有高达20万字符的上下文窗口,并在将软件日志分类到电信协议栈的各个层中实现了超过96%的准确率(F1>0.9)。该模型能够识别测试运行中的缺陷,并将其分类到相关部门,从而取代了需要专家知识的手动工程流程。实验评估了LLaMA2-7B、Mixtral 8x7B、Flan-T5、BERT和BigBird等LLM,并证明了它们在该专业应用中的不足。该CNN在电信日志分类方面显著优于基于LLM的方法,同时最大限度地降低了生产成本,并且可以部署在没有专用硬件的边缘设备上,广泛适用于各个行业的软件日志。
🔬 方法详解
问题定义:论文旨在解决电信行业中复杂软件日志的自动分类问题。现有方法,特别是基于大型语言模型(LLM)的方法,存在上下文窗口限制、不适用于非自然语言文本以及推理成本高等痛点。专家工程师手动分析日志既耗时又昂贵。
核心思路:论文的核心思路是利用卷积神经网络(CNN)提取软件日志中的关键特征,并进行分类。CNN能够有效地处理长序列数据,并且具有较低的计算成本,使其适合在边缘设备上部署。通过专门设计的CNN架构,可以克服LLM在处理此类特定领域文本时的局限性。
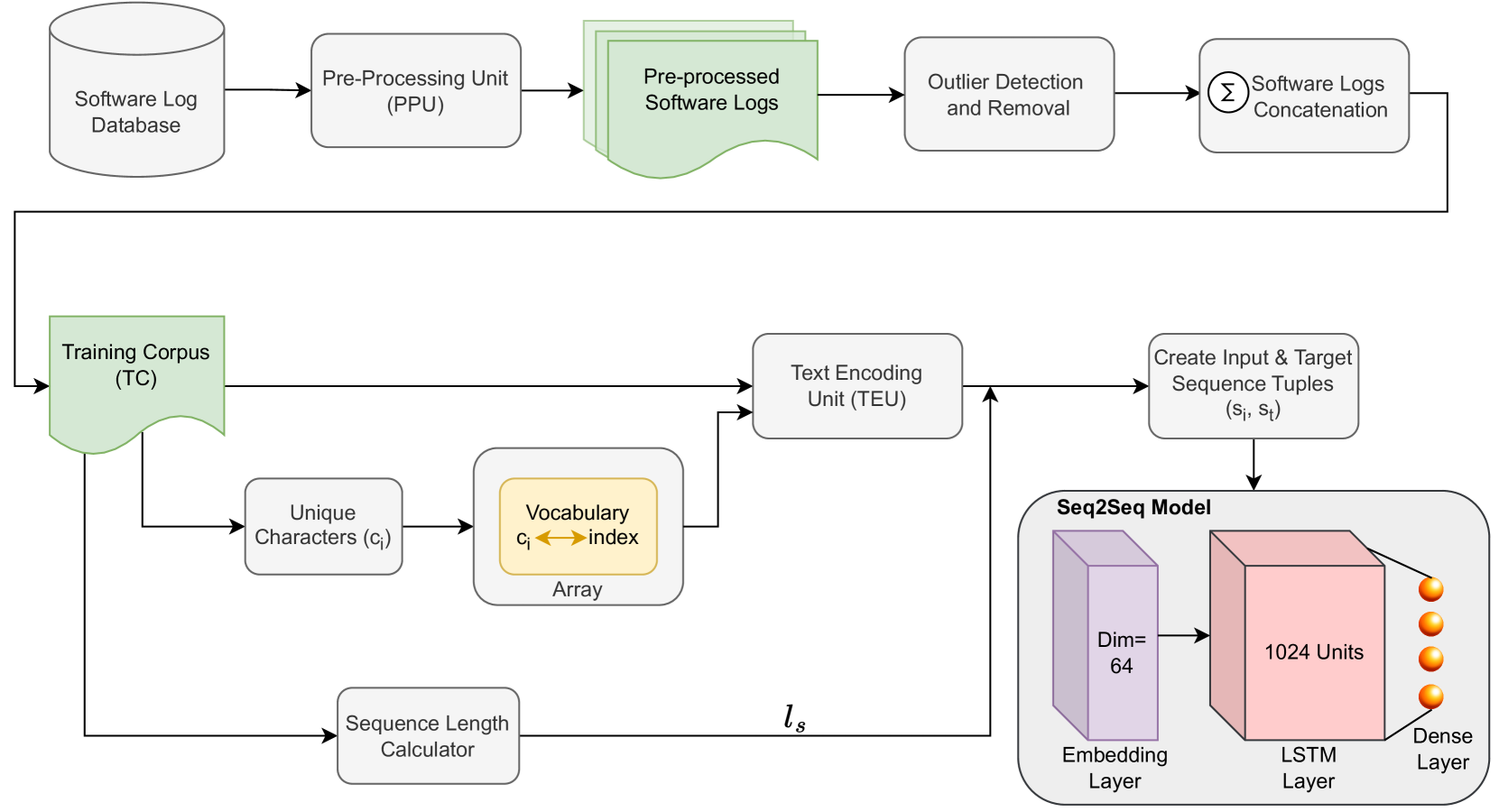
技术框架:整体框架包括数据预处理、CNN模型构建和训练、以及分类结果评估。数据预处理可能涉及文本清洗、分词等操作。CNN模型接收预处理后的日志文本作为输入,经过卷积层、池化层和全连接层等处理,最终输出分类结果。使用标注好的日志数据训练模型,并使用测试数据评估模型的性能。
关键创新:最重要的技术创新点在于提出了一种紧凑型CNN架构,该架构能够处理长达20万字符的上下文窗口,同时保持较低的计算复杂度。与现有方法(特别是LLM)相比,该CNN模型在准确率、推理成本和部署灵活性方面都具有优势。
关键设计:论文中可能涉及的关键设计包括:卷积核的大小和数量、池化层的方式、全连接层的结构、激活函数的选择、以及损失函数的定义。具体的参数设置和网络结构需要在论文中查找。损失函数可能采用交叉熵损失,用于衡量模型预测结果与真实标签之间的差异。此外,可能还使用了正则化技术来防止过拟合。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该CNN模型在电信软件日志分类任务中取得了超过96%的准确率(F1>0.9),显著优于LLaMA2-7B、Mixtral 8x7B、Flan-T5、BERT和BigBird等大型语言模型。该模型能够在边缘设备上部署,无需专用硬件,降低了部署成本。
🎯 应用场景
该研究成果可广泛应用于电信行业的网络测试和故障诊断,实现软件缺陷的自动分类和分流,降低人工成本,提高问题解决效率。此外,该方法还可扩展到其他行业的软件日志分析,例如云计算、物联网和嵌入式系统等,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
Software logs generated by sophisticated network emulators in the telecommunications industry, such as VIAVI TM500, are extremely complex, often comprising tens of thousands of text lines with minimal resemblance to natural language. Only specialised expert engineers can decipher such logs and troubleshoot defects in test runs. While AI offers a promising solution for automating defect triage, potentially leading to massive revenue savings for companies, state-of-the-art large language models (LLMs) suffer from significant drawbacks in this specialised domain. These include a constrained context window, limited applicability to text beyond natural language, and high inference costs. To address these limitations, we propose a compact convolutional neural network (CNN) architecture that offers a context window spanning up to 200,000 characters and achieves over 96% accuracy (F1>0.9) in classifying multifaceted software logs into various layers in the telecommunications protocol stack. Specifically, the proposed model is capable of identifying defects in test runs and triaging them to the relevant department, formerly a manual engineering process that required expert knowledge. We evaluate several LLMs; LLaMA2-7B, Mixtral 8x7B, Flan-T5, BERT and BigBird, and experimentally demonstrate their shortcomings in our specialized application. Despite being lightweight, our CNN significantly outperforms LLM-based approaches in telecommunications log classification while minimizing the cost of production. Our defect triaging AI model is deployable on edge devices without dedicated hardware and widely applicable across software logs in various industries.