GPT-4 vs. Human Translators: A Comprehensive Evaluation of Translation Quality Across Languages, Domains, and Expertise Levels
作者: Jianhao Yan, Pingchuan Yan, Yulong Chen, Judy Li, Xianchao Zhu, Yue Zhang
分类: cs.CL
发布日期: 2024-07-04
💡 一句话要点
对比人类译员,全面评估GPT-4在多语言、领域和专业水平下的翻译质量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 大型语言模型 GPT-4 翻译质量评估 人机对比
📋 核心要点
- 现有机器翻译模型在不同语言、领域和专业水平下的表现差异缺乏系统性评估,难以充分了解其能力边界。
- 该研究通过对比GPT-4与不同水平人类译员的翻译质量,揭示LLM在翻译任务中的优势与不足。
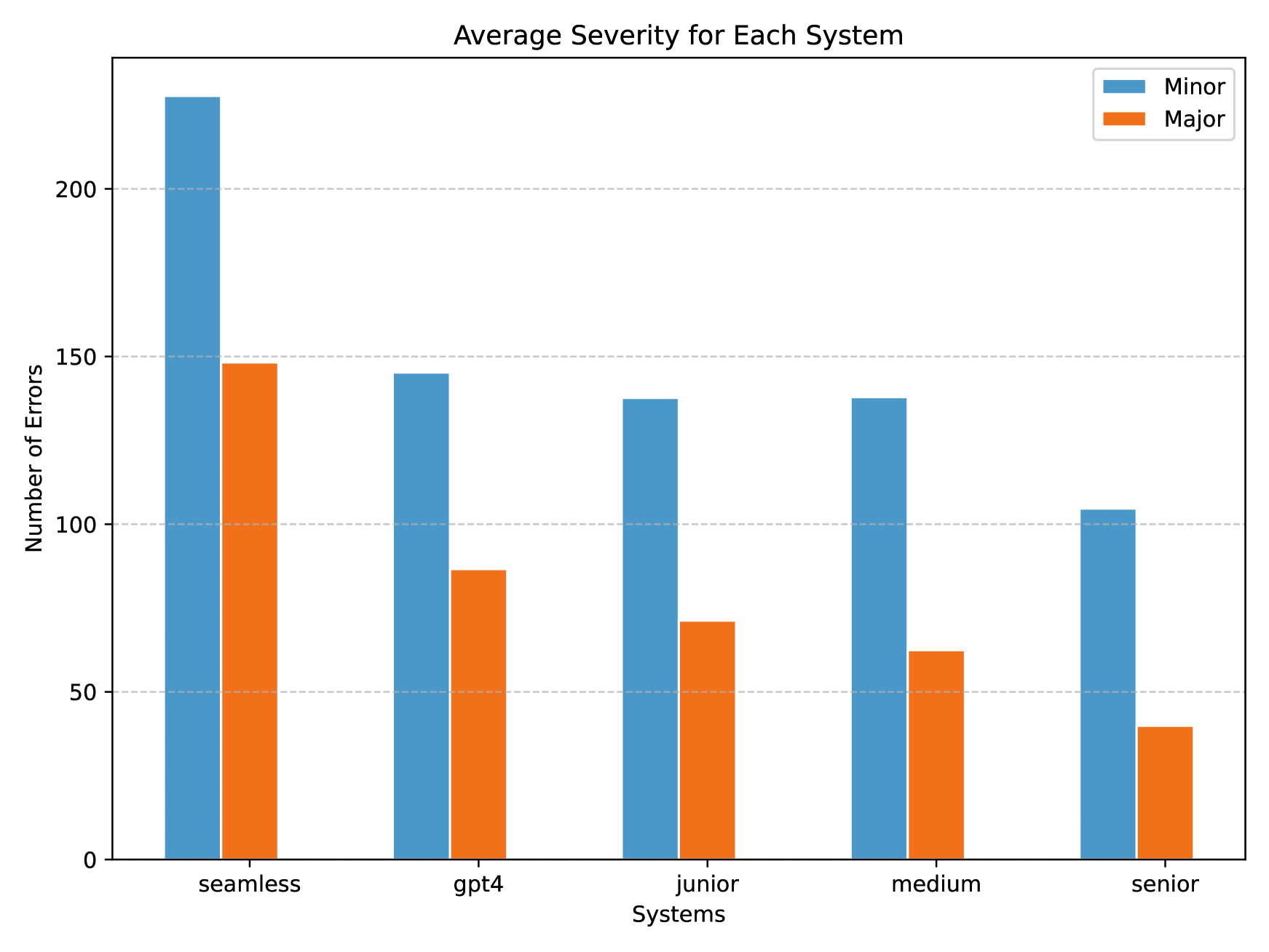
- 实验结果表明,GPT-4的翻译质量与初级译员相当,但在资源匮乏的语言和领域表现较差,存在字面翻译问题。
📝 摘要(中文)
本研究全面评估了大型语言模型(LLMs)的翻译质量,特别是GPT-4,并将其与不同专业水平的人类译员在多种语言对和领域中进行了比较。通过精心设计的标注流程,我们发现GPT-4在总错误数量方面与初级译员的表现相当,但落后于中级和高级译员。我们还观察到不同语言和领域之间的不平衡性能,GPT-4的翻译能力从资源丰富的方向逐渐减弱到资源匮乏的方向。此外,我们对GPT-4和人类译员提供的翻译进行了定性研究,发现GPT-4译员存在字面翻译的问题,而人类译员有时会过度思考背景信息。据我们所知,这项研究首次将LLM与人类译员进行比较,并分析了它们输出之间的系统性差异,为基于LLM的翻译的当前状态及其潜在局限性提供了宝贵的见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在机器翻译任务中的能力评估问题。现有方法缺乏对LLM翻译质量的全面评估,尤其是在不同语言、领域和专业水平下的对比分析。现有评估方法难以揭示LLM翻译的优势与不足,以及与人类译员的差距。
核心思路:论文的核心思路是将GPT-4的翻译结果与不同专业水平(初级、中级、高级)的人类译员的翻译结果进行对比分析。通过人工标注和错误分析,量化评估GPT-4在不同语言对和领域中的翻译质量,并识别其存在的系统性问题。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:收集涵盖多种语言对和领域的翻译文本数据。2) 翻译生成:使用GPT-4和不同水平的人类译员对文本进行翻译。3) 人工标注:由专业标注人员对GPT-4和人类译员的翻译结果进行错误标注和质量评估。4) 结果分析:对标注数据进行统计分析,比较GPT-4和人类译员在不同语言、领域和专业水平下的翻译质量差异。5) 定性分析:对GPT-4和人类译员的翻译结果进行案例分析,识别其存在的典型问题。
关键创新:该研究的创新点在于:1) 首次将LLM(GPT-4)与不同专业水平的人类译员进行全面对比评估。2) 系统性地分析了GPT-4在不同语言、领域和专业水平下的翻译质量差异。3) 揭示了GPT-4在翻译任务中存在的字面翻译等问题,为改进LLM翻译提供了 valuable insights。
关键设计:该研究的关键设计包括:1) 选择具有代表性的语言对和领域,以保证评估结果的generalizability。2) 设计详细的标注指南,确保标注质量和一致性。3) 采用多种评估指标,包括错误数量、翻译流畅度、语义准确性等,以全面评估翻译质量。4) 进行定性分析,深入了解GPT-4和人类译员的翻译策略和思维方式。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GPT-4在总错误数量方面与初级译员相当,但落后于中级和高级译员。GPT-4的翻译能力从资源丰富的语言对到资源匮乏的语言对逐渐减弱。定性分析发现,GPT-4存在字面翻译的问题,而人类译员有时会过度思考背景信息。这些发现揭示了GPT-4在翻译任务中的优势与不足。
🎯 应用场景
该研究成果可应用于改进机器翻译系统,特别是基于LLM的翻译模型。通过了解LLM在不同场景下的翻译能力和局限性,可以针对性地优化模型结构、训练数据和解码策略。此外,该研究还可以为人工翻译提供参考,帮助译员更好地利用LLM辅助翻译工作,提高翻译效率和质量。未来,该研究的思路和方法可以推广到其他自然语言处理任务的评估中。
📄 摘要(原文)
This study comprehensively evaluates the translation quality of Large Language Models (LLMs), specifically GPT-4, against human translators of varying expertise levels across multiple language pairs and domains. Through carefully designed annotation rounds, we find that GPT-4 performs comparably to junior translators in terms of total errors made but lags behind medium and senior translators. We also observe the imbalanced performance across different languages and domains, with GPT-4's translation capability gradually weakening from resource-rich to resource-poor directions. In addition, we qualitatively study the translation given by GPT-4 and human translators, and find that GPT-4 translator suffers from literal translations, but human translators sometimes overthink the background information. To our knowledge, this study is the first to evaluate LLMs against human translators and analyze the systematic differences between their outputs, providing valuable insights into the current state of LLM-based translation and its potential limitations.