Investigating Decoder-only Large Language Models for Speech-to-text Translation
作者: Chao-Wei Huang, Hui Lu, Hongyu Gong, Hirofumi Inaguma, Ilia Kulikov, Ruslan Mavlyutov, Sravya Popuri
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-07-03
备注: Accepted to Interspeech 2024
💡 一句话要点
提出基于Decoder-only LLM的语音到文本翻译模型,无需专有数据达到SOTA
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音到文本翻译 大型语言模型 Decoder-only模型 参数高效微调 CoVoST 2 FLEURS 语音编码 文本生成
📋 核心要点
- 现有的语音翻译模型在推理能力和泛化性方面存在不足,难以处理复杂场景。
- 论文提出一种基于Decoder-only LLM的S2TT架构,直接利用LLM强大的文本生成能力。
- 实验表明,该模型在CoVoST 2和FLEURS数据集上取得了SOTA性能,且未使用专有数据。
📝 摘要(中文)
大型语言模型(LLM)以其卓越的推理能力、泛化性和跨领域流畅性而闻名,为增强语音相关任务提供了一个有希望的途径。本文重点研究将仅解码器的LLM集成到语音到文本翻译(S2TT)任务中。我们提出了一种仅解码器的架构,该架构使LLM能够直接消耗编码的语音表示并生成文本翻译。此外,我们还研究了不同参数高效微调技术和任务公式的影响。我们的模型在CoVoST 2和FLEURS上实现了最先进的性能,这些模型在没有专有数据的情况下进行训练。我们还进行了分析,以验证我们提出的模型的设计选择,并为将LLM集成到S2TT中带来见解。
🔬 方法详解
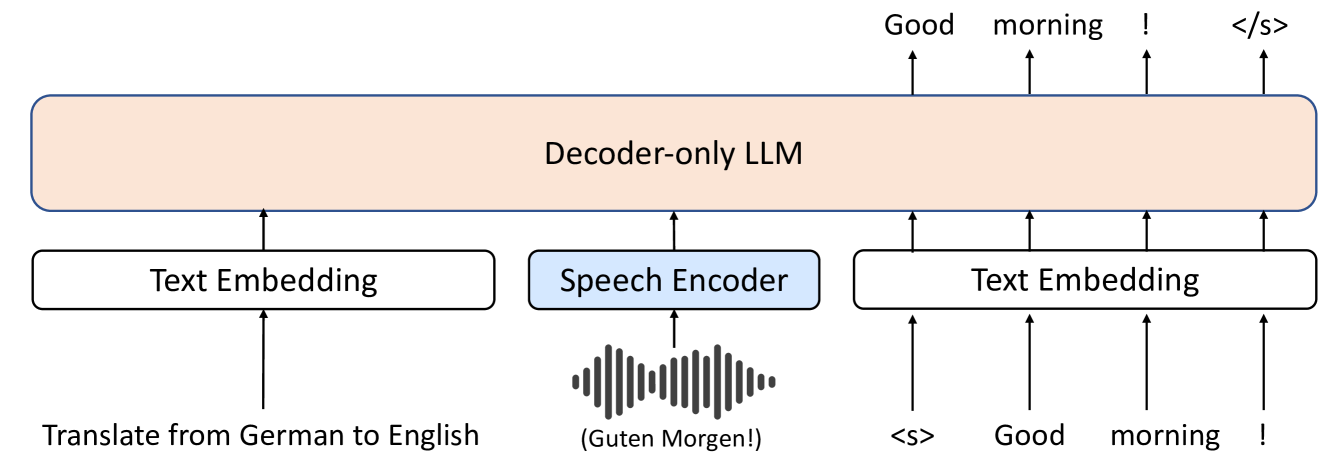
问题定义:论文旨在解决语音到文本翻译(S2TT)任务中,传统模型推理能力和泛化性不足的问题。现有方法通常依赖于encoder-decoder结构,难以充分利用大型语言模型(LLM)的强大能力,尤其是在没有大量标注数据的情况下表现受限。
核心思路:论文的核心思路是将decoder-only的LLM直接应用于S2TT任务。通过将编码后的语音特征作为LLM的输入,利用LLM强大的文本生成能力,直接生成目标语言的翻译文本。这种方法避免了传统encoder-decoder结构的信息瓶颈,并能更好地利用LLM的先验知识。
技术框架:整体框架包含一个语音编码器和一个decoder-only的LLM。语音编码器负责将输入的语音信号转换为高维的特征表示。然后,这些特征表示被输入到LLM中,LLM根据这些特征生成目标语言的翻译文本。整个过程可以看作是一个序列到序列的生成过程,其中输入是语音特征序列,输出是文本序列。
关键创新:最重要的创新点在于直接将decoder-only的LLM应用于S2TT任务,并探索了不同的参数高效微调技术。与传统的encoder-decoder结构相比,这种方法能够更好地利用LLM的文本生成能力,并且可以通过参数高效微调,在有限的计算资源下获得更好的性能。
关键设计:论文探索了不同的参数高效微调技术,例如LoRA和Adapter。此外,论文还研究了不同的任务公式,例如直接生成目标语言文本,或者先生成中间表示再生成目标语言文本。具体的参数设置和网络结构细节在论文中有详细描述,例如LLM的具体选择(例如GPT系列),以及语音编码器的结构和参数。
🖼️ 关键图片
📊 实验亮点
该模型在CoVoST 2和FLEURS数据集上取得了SOTA性能,无需使用专有数据。实验结果表明,该模型能够有效地利用LLM的文本生成能力,并且通过参数高效微调,可以在有限的计算资源下获得显著的性能提升。具体的性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于实时语音翻译、多语言会议、语音助手等领域。通过利用大型语言模型的强大能力,可以显著提升语音翻译的质量和效率,促进跨语言交流。未来,该技术有望应用于更广泛的场景,例如自动字幕生成、语音文档翻译等。
📄 摘要(原文)
Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.