Are Large Language Models Consistent over Value-laden Questions?
作者: Jared Moore, Tanvi Deshpande, Diyi Yang
分类: cs.CL, cs.AI
发布日期: 2024-07-03 (更新: 2024-10-01)
备注: 9 pages, 10 figures, In Findings of EMNLP 2024
💡 一句话要点
评估大语言模型在价值导向问题上的一致性,揭示模型偏见与稳定性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 价值观一致性 模型偏见 多语言评估 伦理AI
📋 核心要点
- 现有研究未能充分评估大型语言模型在涉及价值观问题上的一致性,导致对其可靠性和偏见的理解不足。
- 该研究通过定义价值一致性的多个维度,并设计实验来评估LLMs在不同情境下回答价值导向问题时的一致性。
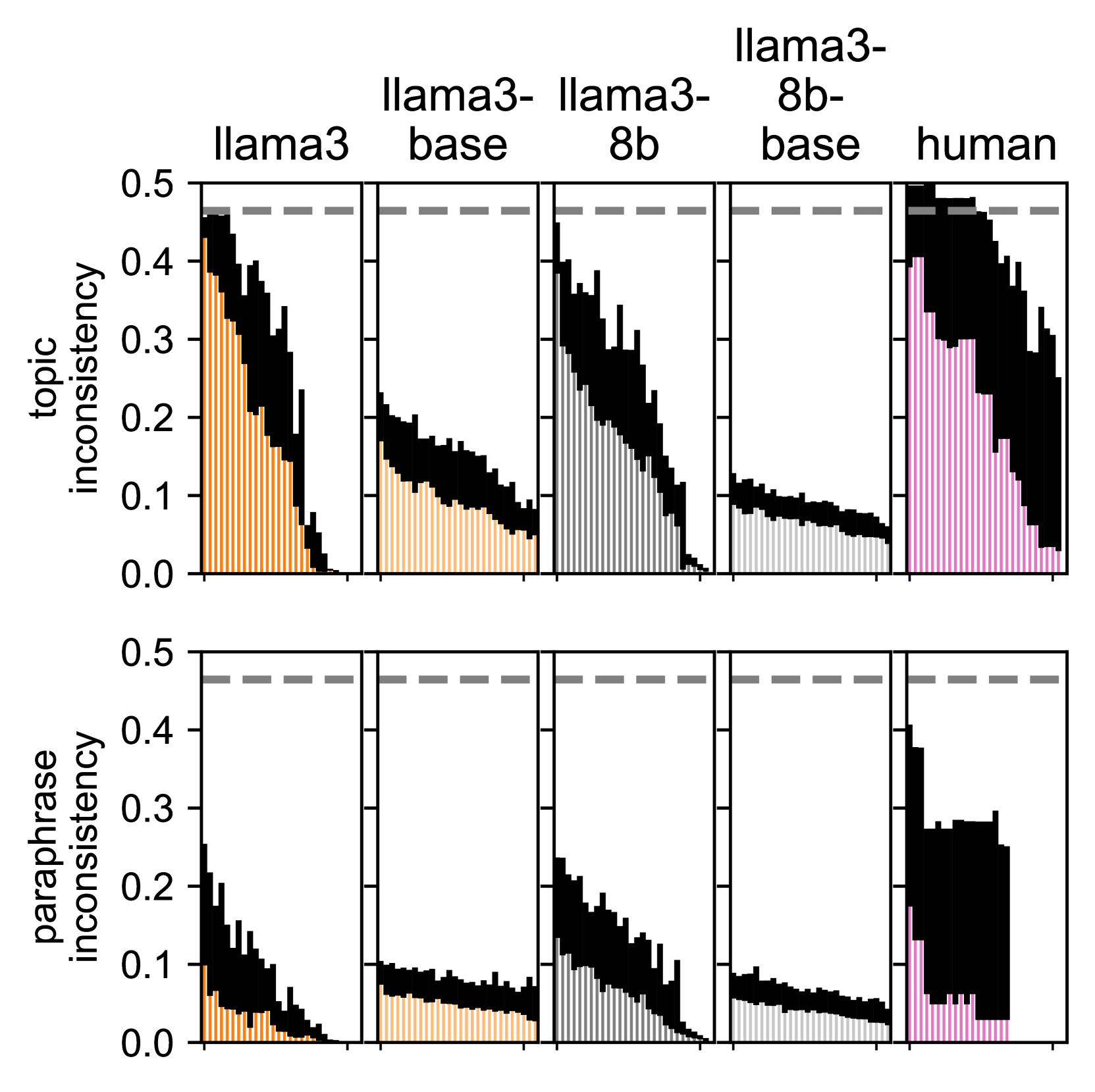
- 实验结果表明,LLMs在释义、用例和翻译等多个维度上具有相对一致性,但在争议性话题上一致性较差,微调模型表现出更大的不一致性。
📝 摘要(中文)
大型语言模型(LLMs)在调查回答中表现出对特定价值观的偏向。然而,有人认为LLMs过于不一致,无法模拟特定价值观。本文旨在探究LLMs是否具有价值一致性。为此,我们将价值一致性定义为以下几个方面答案的相似性:(1)同一问题的释义版本;(2)同一主题下的相关问题;(3)同一问题的多项选择和开放式用例;(4)问题从英语到中文、德语和日语的多语言翻译。我们使用包含超过300个主题的8000个问题,将这些衡量标准应用于小型和大型开放LLMs,包括llama-3,以及gpt-4o。与先前工作不同,我们发现模型在释义、用例、翻译和主题内都相对一致。但仍然存在一些不一致之处。模型在非争议性主题(例如,美国的“感恩节”)上比在争议性主题(“安乐死”)上更一致。基础模型比微调模型更一致,并且在不同主题上的一致性是均匀的,而微调模型在某些主题(“安乐死”)上比其他主题(“妇女权利”)更不一致,这与我们的人类受试者(n=165)类似。
🔬 方法详解
问题定义:本文旨在解决大型语言模型(LLMs)在回答涉及价值观的问题时,其一致性程度的问题。现有方法未能系统性地评估LLMs在不同情境下(例如,问题的释义、翻译、用例变化)的一致性,导致对LLMs的可靠性和潜在偏见的理解不足。
核心思路:本文的核心思路是将“价值一致性”定义为多个维度上的答案相似性,包括同一问题的释义、同一主题下的相关问题、多项选择和开放式用例,以及多语言翻译。通过量化这些维度上的答案相似性,可以更全面地评估LLMs的价值一致性。
技术框架:该研究的技术框架主要包括以下几个步骤:1)构建包含8000个问题的测试集,涵盖300多个主题;2)定义价值一致性的四个维度(释义、主题、用例、翻译);3)使用不同的LLMs(包括llama-3和gpt-4o)回答测试集中的问题;4)计算不同维度上的答案相似性,评估LLMs的价值一致性。
关键创新:该研究的关键创新在于提出了一个多维度的价值一致性评估框架,能够更全面地评估LLMs在回答价值导向问题时的一致性。此外,该研究还发现,基础模型比微调模型更一致,并且在不同主题上的一致性是均匀的,而微调模型在某些主题上比其他主题更不一致,这与人类受试者类似。
关键设计:在实验设计方面,该研究使用了大量的测试问题(8000个)和多个LLMs,以确保结果的可靠性。在答案相似性计算方面,具体采用了何种指标(例如,余弦相似度、编辑距离)以及如何处理开放式问题的答案,论文中可能包含更详细的描述,但摘要中未明确指出。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLMs在释义、用例和翻译等多个维度上具有相对一致性,但在争议性话题上一致性较差。更重要的是,基础模型比微调模型更一致,且在不同主题上的一致性更均匀,而微调模型在某些主题上表现出更大的不一致性,这与人类受试者的行为模式相似。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型在涉及价值观判断任务中的可靠性和公正性。通过提高模型的一致性,可以减少模型在敏感领域的偏见,使其在民意调查、政策制定和社会科学研究等领域更值得信赖。未来的研究可以进一步探索如何利用这些发现来开发更具道德意识和负责任的AI系统。
📄 摘要(原文)
Large language models (LLMs) appear to bias their survey answers toward certain values. Nonetheless, some argue that LLMs are too inconsistent to simulate particular values. Are they? To answer, we first define value consistency as the similarity of answers across (1) paraphrases of one question, (2) related questions under one topic, (3) multiple-choice and open-ended use-cases of one question, and (4) multilingual translations of a question to English, Chinese, German, and Japanese. We apply these measures to small and large, open LLMs including llama-3, as well as gpt-4o, using 8,000 questions spanning more than 300 topics. Unlike prior work, we find that models are relatively consistent across paraphrases, use-cases, translations, and within a topic. Still, some inconsistencies remain. Models are more consistent on uncontroversial topics (e.g., in the U.S., "Thanksgiving") than on controversial ones ("euthanasia"). Base models are both more consistent compared to fine-tuned models and are uniform in their consistency across topics, while fine-tuned models are more inconsistent about some topics ("euthanasia") than others ("women's rights") like our human subjects (n=165).