Learning to Reduce: Towards Improving Performance of Large Language Models on Structured Data
作者: Younghun Lee, Sungchul Kim, Ryan A. Rossi, Tong Yu, Xiang Chen
分类: cs.CL
发布日期: 2024-07-03
备注: ICML 2024 Workshop on Long-Context Foundation Models, Vienna, Austria 2024. arXiv admin note: substantial text overlap with arXiv:2402.14195
💡 一句话要点
提出Learning to Reduce框架,提升大语言模型在结构化数据上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化数据 On-Policy Learning 数据缩减 表格问答 强化学习 Transformer
📋 核心要点
- 现有大语言模型在处理长文本结构化数据时面临挑战,需要有效理解或选择相关证据。
- Learning to Reduce框架通过On-Policy Learning微调语言模型,生成结构化数据的精简版本。
- 实验表明,该框架在数据缩减和表格问答任务上优于现有LLM,尤其是在长文本上下文中。
📝 摘要(中文)
大型语言模型(LLMs)在各种下游任务中表现出色,但现有研究表明,LLMs在结构化数据上的推理面临挑战。这是因为LLMs需要理解冗长的结构化数据,或者在推理前选择最相关的证据,而这两种方法都不容易实现。本文提出了一个名为“Learning to Reduce”的框架,该框架通过On-Policy Learning微调语言模型,以生成输入结构化数据的简化版本。与GPT-4等最先进的LLMs相比,“Learning to Reduce”不仅在减少输入方面表现出色,而且在不同的数据集上表现出泛化能力。我们进一步表明,使用我们的框架微调的模型有助于LLMs更好地执行表格问答任务,尤其是在上下文较长时。
🔬 方法详解
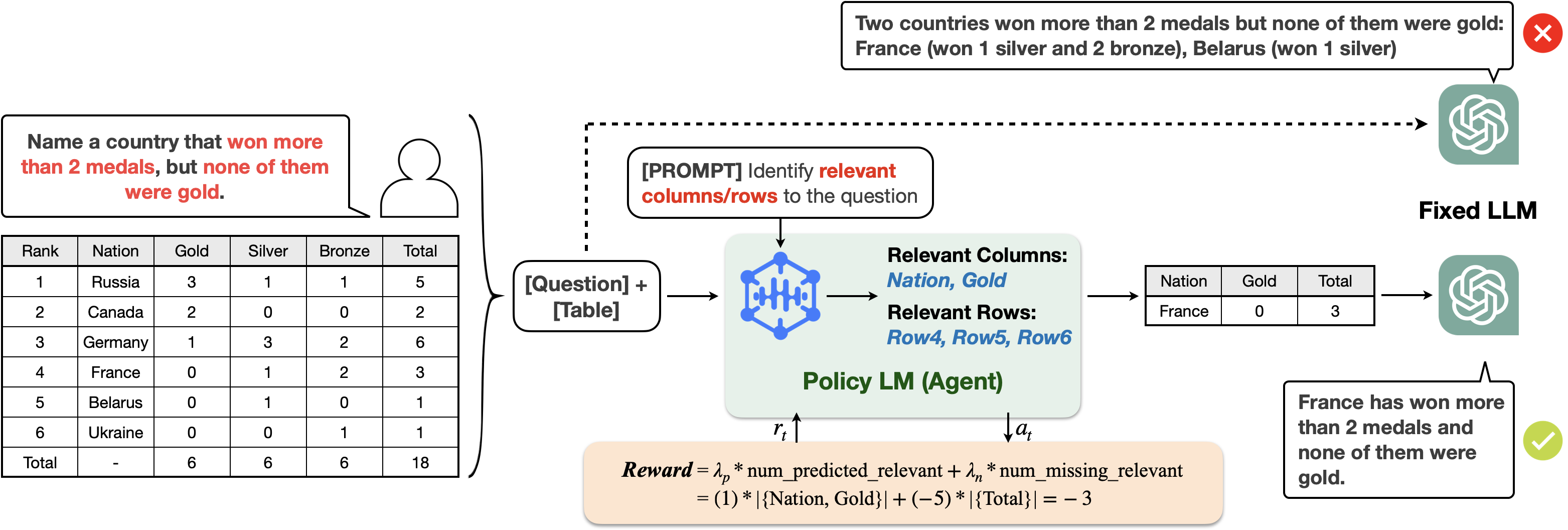
问题定义:论文旨在解决大型语言模型(LLMs)在处理结构化数据时面临的挑战,特别是当数据量大且冗长时。现有的方法要么难以理解长文本,要么难以有效选择相关信息,导致推理性能下降。
核心思路:论文的核心思路是通过学习生成输入结构化数据的简化版本,从而减轻LLMs的负担。通过减少输入数据的长度和复杂度,可以提高LLMs的推理效率和准确性。这种方法类似于人类在处理复杂信息时,首先进行提炼和总结,然后再进行分析和决策。
技术框架:Learning to Reduce框架的核心是使用On-Policy Learning微调语言模型。该框架包含以下主要阶段:1) 使用语言模型生成输入数据的简化版本;2) 使用下游任务的反馈信号(例如,表格问答的准确率)作为奖励;3) 使用On-Policy Learning算法(例如,Policy Gradient)更新语言模型的参数,使其能够生成更好的简化版本。这个过程迭代进行,直到模型收敛。
关键创新:该论文的关键创新在于将强化学习应用于结构化数据的缩减任务。与传统的监督学习方法不同,On-Policy Learning能够直接优化下游任务的性能,而不需要人工标注的缩减数据。此外,该框架具有很强的通用性,可以应用于不同的结构化数据和下游任务。
关键设计:在具体实现上,论文使用了Transformer架构的语言模型作为基础模型。奖励函数的设计至关重要,需要能够准确反映简化数据对下游任务性能的影响。论文中使用了表格问答的准确率作为奖励,并进行了一些平滑处理,以避免奖励过于稀疏。此外,论文还探索了不同的On-Policy Learning算法,并选择了效果最好的算法。
🖼️ 关键图片

📊 实验亮点
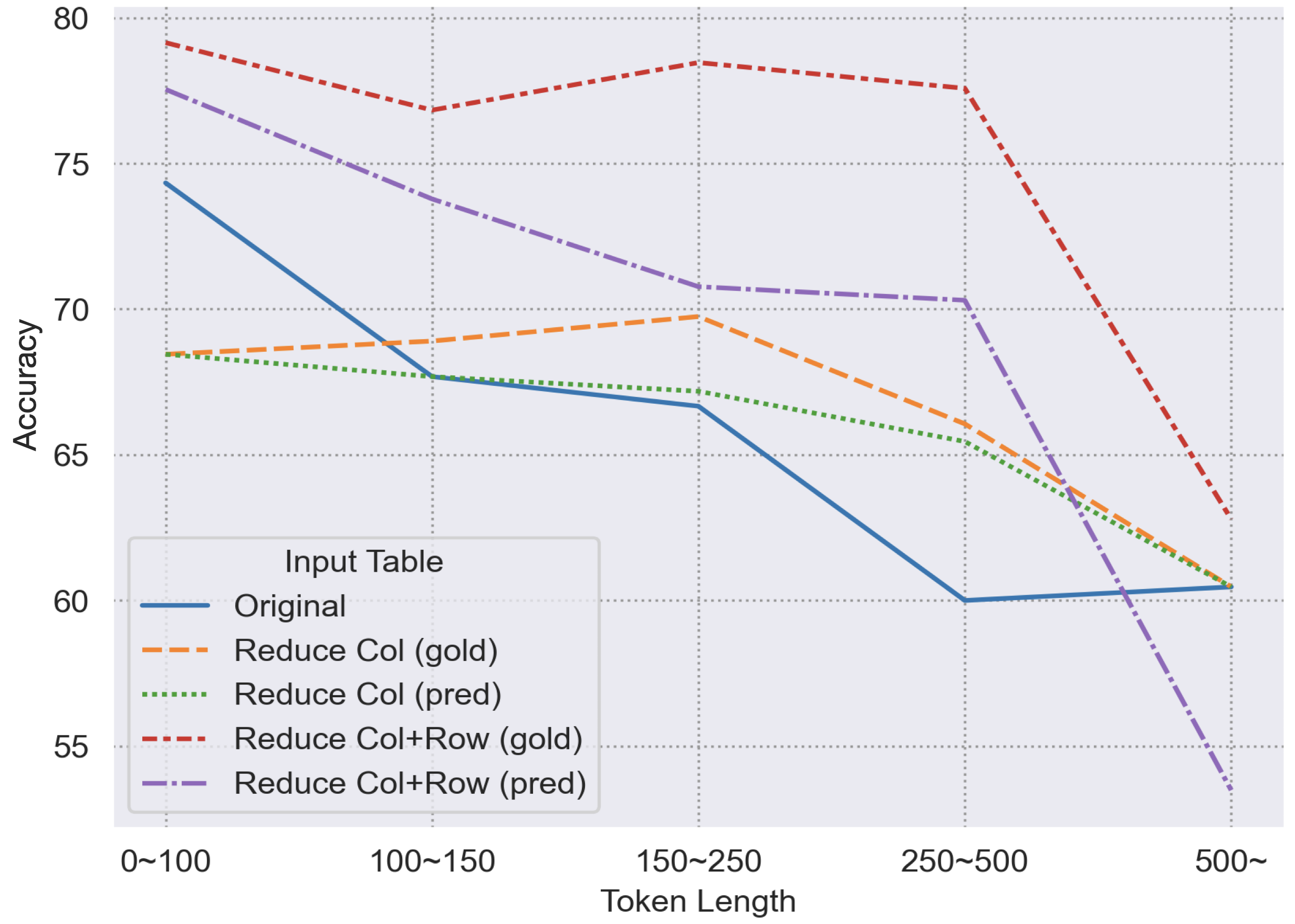
实验结果表明,Learning to Reduce框架在数据缩减方面优于现有方法,并且能够显著提高LLMs在表格问答任务上的性能。与GPT-4等先进模型相比,该框架在不同数据集上表现出良好的泛化能力。尤其是在长文本上下文中,该框架的优势更加明显,能够有效提高LLMs的推理准确率。
🎯 应用场景
该研究成果可广泛应用于需要处理大量结构化数据的场景,例如金融分析、医疗诊断、知识图谱问答等。通过自动缩减数据,可以提高LLMs在这些领域的应用效率和准确性,降低计算成本,并为用户提供更快速、更可靠的服务。未来,该技术有望进一步扩展到其他类型的数据和任务。
📄 摘要(原文)
Large Language Models (LLMs) have been achieving competent performance on a wide range of downstream tasks, yet existing work shows that inference on structured data is challenging for LLMs. This is because LLMs need to either understand long structured data or select the most relevant evidence before inference, and both approaches are not trivial. This paper proposes a framework, Learning to Reduce, that fine-tunes a language model with On-Policy Learning to generate a reduced version of an input structured data. When compared to state-of-the-art LLMs like GPT-4, Learning to Reduce not only achieves outstanding performance in reducing the input, but shows generalizability on different datasets. We further show that the model fine-tuned with our framework helps LLMs better perform on table QA tasks especially when the context is longer.