Predicting vs. Acting: A Trade-off Between World Modeling & Agent Modeling
作者: Margaret Li, Weijia Shi, Artidoro Pagnoni, Peter West, Ari Holtzman
分类: cs.CL, cs.AI
发布日期: 2024-07-02
💡 一句话要点
RLHF模型在生成任务中存在预测能力与行为能力之间的权衡
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: RLHF 语言模型 Agent模型 世界建模 文本生成 下一token预测 锚定跨度
📋 核心要点
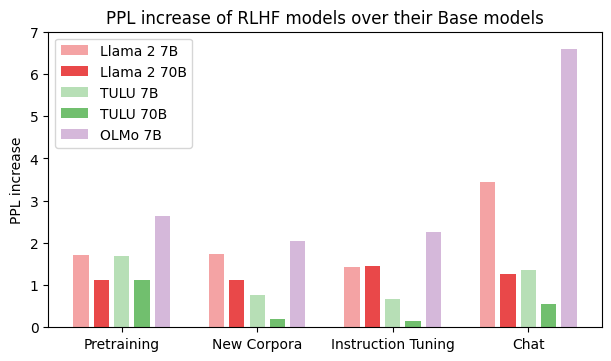
- RLHF对齐的语言模型在长文本生成方面表现出色,但在下一token预测这一基础任务上存在不足。
- 论文提出,RLHF模型为了保证长文本生成的连贯性,会通过隐式蓝图限制随机性,从而牺牲了世界建模能力。
- 实验表明,RLHF模型倾向于生成包含特定锚定跨度的文本,这限制了其生成多样化文档的能力,揭示了预测与行为之间的权衡。
📝 摘要(中文)
经过RLHF对齐的语言模型在基准测试和长文本生成方面表现出前所未有的能力,但它们在下一token预测这一基础任务上表现不佳。随着RLHF模型转变为旨在与人类交互的Agent模型,它们似乎失去了世界建模能力,即预测任意文档中接下来内容的能力,而这正是RLHF所适应的基础语言模型(Base LM)的根本训练目标。除了通过实验证明这种权衡之外,我们还提出了一个潜在的解释:为了执行连贯的长文本生成,RLHF模型通过隐式蓝图来限制随机性。特别是,RLHF模型将概率集中在锚定跨度集合上,这些锚定跨度在同一提示的多个生成中共同出现,充当文本支架,但也限制了模型生成不包含这些跨度的文档的能力。我们研究了这种权衡在当前最有效的Agent模型(即与RLHF对齐的模型)上的表现,同时探讨了为什么这可能仍然是行为模型和预测模型之间的一个根本权衡,即使对齐技术有所改进。
🔬 方法详解
问题定义:论文关注的是经过RLHF(Reinforcement Learning from Human Feedback)对齐的语言模型,在从基础的预测模型转变为与人类交互的Agent模型时,其世界建模能力(即预测文本序列的能力)下降的问题。现有方法,即RLHF,虽然提升了模型在生成任务中的表现,但牺牲了其在下一token预测任务上的准确性。
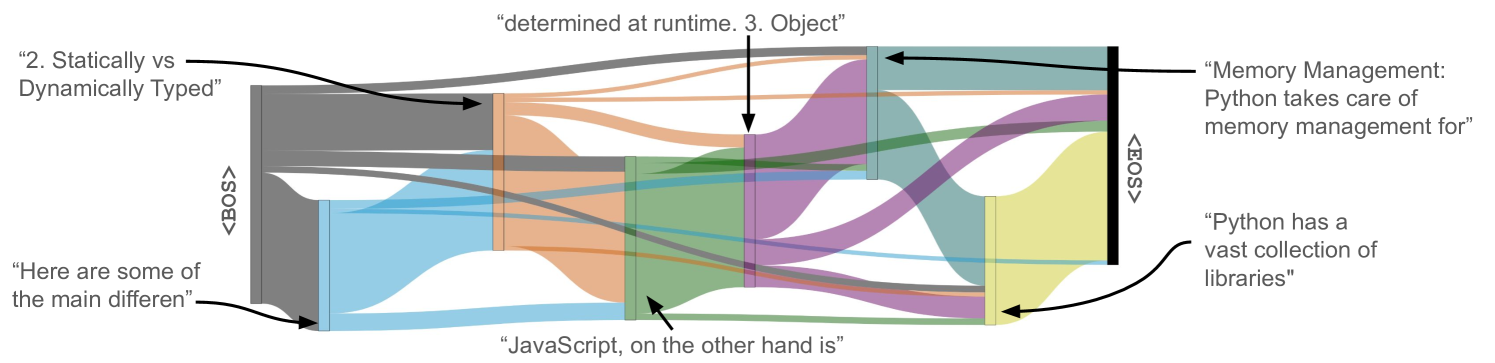
核心思路:论文的核心思路是,RLHF模型为了生成连贯的长文本,会倾向于使用一些“锚定跨度”(anchor spans),这些跨度在多次生成中重复出现,形成一种隐式的“蓝图”。这种蓝图限制了模型的随机性,使其难以生成不包含这些锚定跨度的文本,从而降低了其世界建模能力。因此,预测能力和行为能力之间存在一种权衡。
技术框架:论文没有提出一个全新的技术框架,而是通过实验分析来验证其提出的假设。其研究方法主要包括:1) 分析RLHF模型生成的文本,观察锚定跨度的出现频率;2) 比较RLHF模型和基础语言模型在下一token预测任务上的性能差异;3) 探讨不同RLHF训练策略对锚定跨度和世界建模能力的影响。
关键创新:论文的关键创新在于揭示了RLHF模型在生成任务中存在的预测能力与行为能力之间的权衡。它指出,为了提高生成文本的连贯性和质量,RLHF模型会牺牲其在下一token预测任务上的准确性。这种权衡是由于RLHF模型倾向于使用锚定跨度来构建文本,从而限制了其生成多样化文本的能力。
关键设计:论文没有涉及具体的模型参数或网络结构设计。其主要关注点在于分析RLHF模型在生成文本时的行为模式,以及这种行为模式对模型世界建模能力的影响。论文通过实验分析来验证其提出的假设,并探讨了不同RLHF训练策略对锚定跨度和世界建模能力的影响。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,RLHF模型在生成任务中倾向于使用锚定跨度,这限制了其生成多样化文本的能力,并降低了其在下一token预测任务上的准确性。实验结果表明,RLHF模型的生成质量提升是以牺牲世界建模能力为代价的,揭示了预测能力与行为能力之间的权衡。
🎯 应用场景
该研究成果有助于更好地理解RLHF对齐的语言模型的行为模式,并为未来的模型设计提供指导。例如,在设计Agent模型时,需要在生成质量和世界建模能力之间进行权衡,避免过度依赖锚定跨度,从而提高模型在各种任务中的泛化能力。该研究对对话系统、文本生成等领域具有潜在的应用价值。
📄 摘要(原文)
RLHF-aligned LMs have shown unprecedented ability on both benchmarks and long-form text generation, yet they struggle with one foundational task: next-token prediction. As RLHF models become agent models aimed at interacting with humans, they seem to lose their world modeling -- the ability to predict what comes next in arbitrary documents, which is the foundational training objective of the Base LMs that RLHF adapts. Besides empirically demonstrating this trade-off, we propose a potential explanation: to perform coherent long-form generation, RLHF models restrict randomness via implicit blueprints. In particular, RLHF models concentrate probability on sets of anchor spans that co-occur across multiple generations for the same prompt, serving as textual scaffolding but also limiting a model's ability to generate documents that do not include these spans. We study this trade-off on the most effective current agent models, those aligned with RLHF, while exploring why this may remain a fundamental trade-off between models that act and those that predict, even as alignment techniques improve.