Efficient Sparse Attention needs Adaptive Token Release
作者: Chaoran Zhang, Lixin Zou, Dan Luo, Min Tang, Xiangyang Luo, Zihao Li, Chenliang Li
分类: cs.CL
发布日期: 2024-07-02
备注: Accepted at ACL 2024(Findings)
🔗 代码/项目: GITHUB
💡 一句话要点
提出自适应Token释放的稀疏注意力机制,提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 大型语言模型 自适应Token释放 Key-Value状态管理 模型推理加速
📋 核心要点
- 大型语言模型面临计算和存储瓶颈,尤其是在Transformer的键值状态管理上。
- 提出自适应Token释放策略,通过轻量级控制器近似top-$K$稀疏注意力,保留重要token并重建必要token。
- 实验表明,该方法在性能上与完全注意力相当,并显著提升了吞吐量,最高可达221.8%。
📝 摘要(中文)
近年来,大型语言模型(LLMs)在各种文本任务中表现出卓越的能力。然而,其“大型”规模带来了巨大的计算和存储挑战,尤其是在管理Transformer的键值状态方面,这限制了它们更广泛的应用。因此,我们提出自适应地从缓存中释放资源并重建必要的键值状态。具体来说,我们通过一个轻量级的控制器模块来近似理想的top-$K$稀疏注意力。该模块保留具有最高top-$K$注意力权重的token,并同时重建被丢弃但必要的token,这些token可能对未来的解码至关重要。在自然语言生成和建模方面的综合实验表明,我们的方法不仅在性能方面与完全注意力具有竞争力,而且实现了高达221.8%的吞吐量显著提升。
🔬 方法详解
问题定义:大型语言模型(LLMs)的推理过程需要维护大量的Key-Value状态,这导致了巨大的内存占用和计算开销,限制了LLMs在资源受限环境中的部署。现有的稀疏注意力方法虽然可以减少计算量,但可能会丢弃对未来解码至关重要的token,导致性能下降。
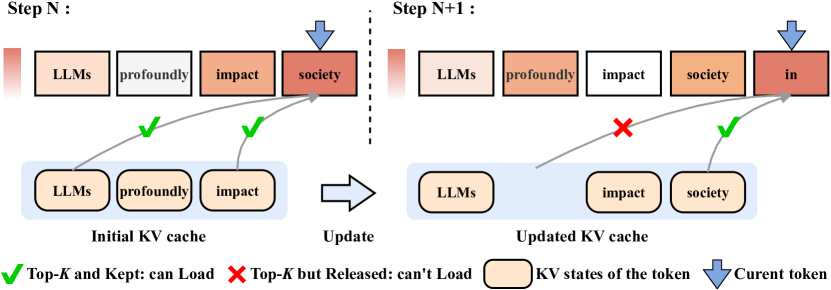
核心思路:论文的核心思路是自适应地释放和重建Key-Value状态中的token。通过一个轻量级的控制器模块,动态地选择保留具有最高注意力权重的top-$K$个token,同时重建那些被丢弃但可能在未来解码中变得重要的token。这样既能减少计算量,又能保证模型的性能。
技术框架:该方法主要包含两个核心模块:Token选择模块和Token重建模块。Token选择模块负责根据注意力权重选择top-$K$个token。Token重建模块则根据一定的策略(例如,预测未来可能重要的token)重建被丢弃的token。这两个模块协同工作,实现Key-Value状态的自适应管理。整体流程是在每一层Transformer中,先进行Token选择,然后进行Token重建,最后再进行正常的注意力计算和前馈网络计算。
关键创新:该方法最重要的创新点在于自适应的Token释放和重建机制。与传统的稀疏注意力方法不同,该方法不仅关注当前时刻的注意力权重,还考虑了未来时刻可能需要的token。通过动态地调整Key-Value状态,实现了计算效率和模型性能的平衡。
关键设计:控制器模块的设计是关键。该模块需要能够准确地预测哪些token在未来可能变得重要。论文中可能使用了某种预测模型(具体细节未知)来实现这一功能。另外,top-$K$值的选择也是一个重要的参数,需要根据具体的任务和数据集进行调整。损失函数的设计也需要考虑如何平衡计算效率和模型性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在自然语言生成和建模任务中,能够在保持与完全注意力相当的性能水平下,显著提升吞吐量,最高可达221.8%。这表明该方法在提高LLM推理效率方面具有显著优势,为LLM的实际应用提供了新的解决方案。
🎯 应用场景
该研究成果可应用于各种需要高效LLM推理的场景,如移动设备上的本地部署、边缘计算环境下的实时翻译、以及资源受限的数据中心。通过降低LLM的计算和存储需求,可以使其更广泛地应用于实际场景,加速人工智能技术的普及。
📄 摘要(原文)
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities across a wide array of text-centric tasks. However, their `large' scale introduces significant computational and storage challenges, particularly in managing the key-value states of the transformer, which limits their wider applicability. Therefore, we propose to adaptively release resources from caches and rebuild the necessary key-value states. Particularly, we accomplish this by a lightweight controller module to approximate an ideal top-$K$ sparse attention. This module retains the tokens with the highest top-$K$ attention weights and simultaneously rebuilds the discarded but necessary tokens, which may become essential for future decoding. Comprehensive experiments in natural language generation and modeling reveal that our method is not only competitive with full attention in terms of performance but also achieves a significant throughput improvement of up to 221.8%. The code for replication is available on the https://github.com/WHUIR/ADORE.