Exploring the Role of Transliteration in In-Context Learning for Low-resource Languages Written in Non-Latin Scripts
作者: Chunlan Ma, Yihong Liu, Haotian Ye, Hinrich Schütze
分类: cs.CL, cs.AI
发布日期: 2024-07-02
💡 一句话要点
探索音译在非拉丁文字低资源语言LLM上下文学习中的作用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 音译 上下文学习 大型语言模型 非拉丁文字 文本分类 序列标注
📋 核心要点
- 现有LLM在低资源非拉丁语上的上下文学习能力不足,限制了其应用。
- 论文探索了音译在提升LLM处理低资源非拉丁语任务性能方面的潜力。
- 实验表明,音译对序列标注任务有显著提升,效果受任务类型和模型大小影响。
📝 摘要(中文)
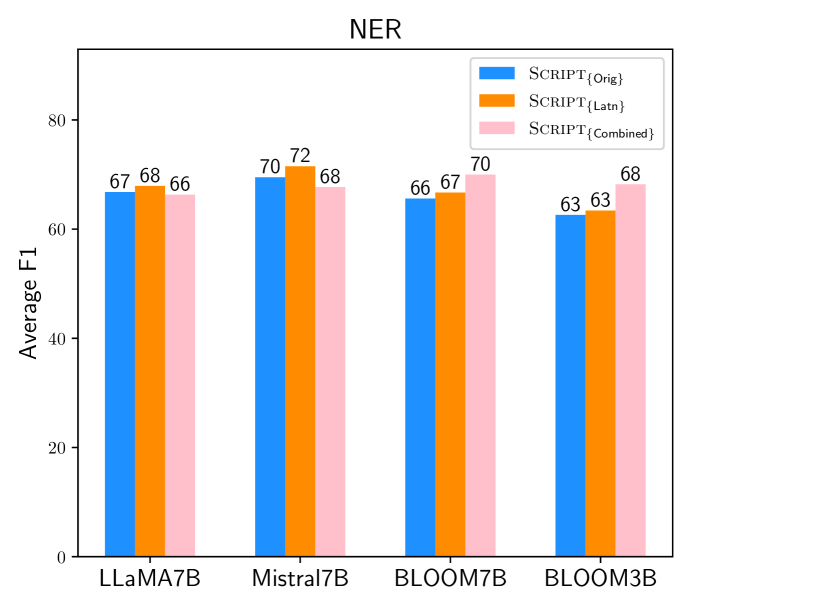
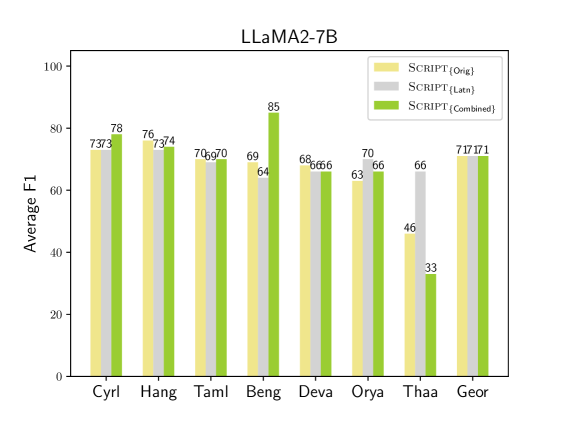
仅使用解码器的大型语言模型(LLM)通过少样本或零样本上下文学习(ICL)在各种任务的高资源语言中表现出色。然而,它们的性能通常不能很好地转移到低资源语言,特别是那些用非拉丁文字书写的语言。受最近在仅使用编码器的模型中利用音译的工作的启发,我们研究了音译是否也能有效地提高LLM在非拉丁文字低资源语言中的性能。为此,我们提出了三种提示模板,其中目标语言文本以(1)其原始文字,(2)拉丁文字,或(3)两者表示。我们将这些方法应用于不同大小的几个代表性LLM,用于包括文本分类和序列标注在内的各种任务。我们的研究结果表明,音译的有效性因任务类型和模型大小而异。例如,所有模型都受益于序列标注的音译(提升高达25%)。
🔬 方法详解
问题定义:论文旨在解决低资源非拉丁语在大型语言模型(LLM)上下文学习中表现不佳的问题。现有方法直接使用原始非拉丁语文本作为输入,但由于LLM主要在高资源拉丁语数据上训练,对非拉丁语的理解能力有限,导致性能下降。
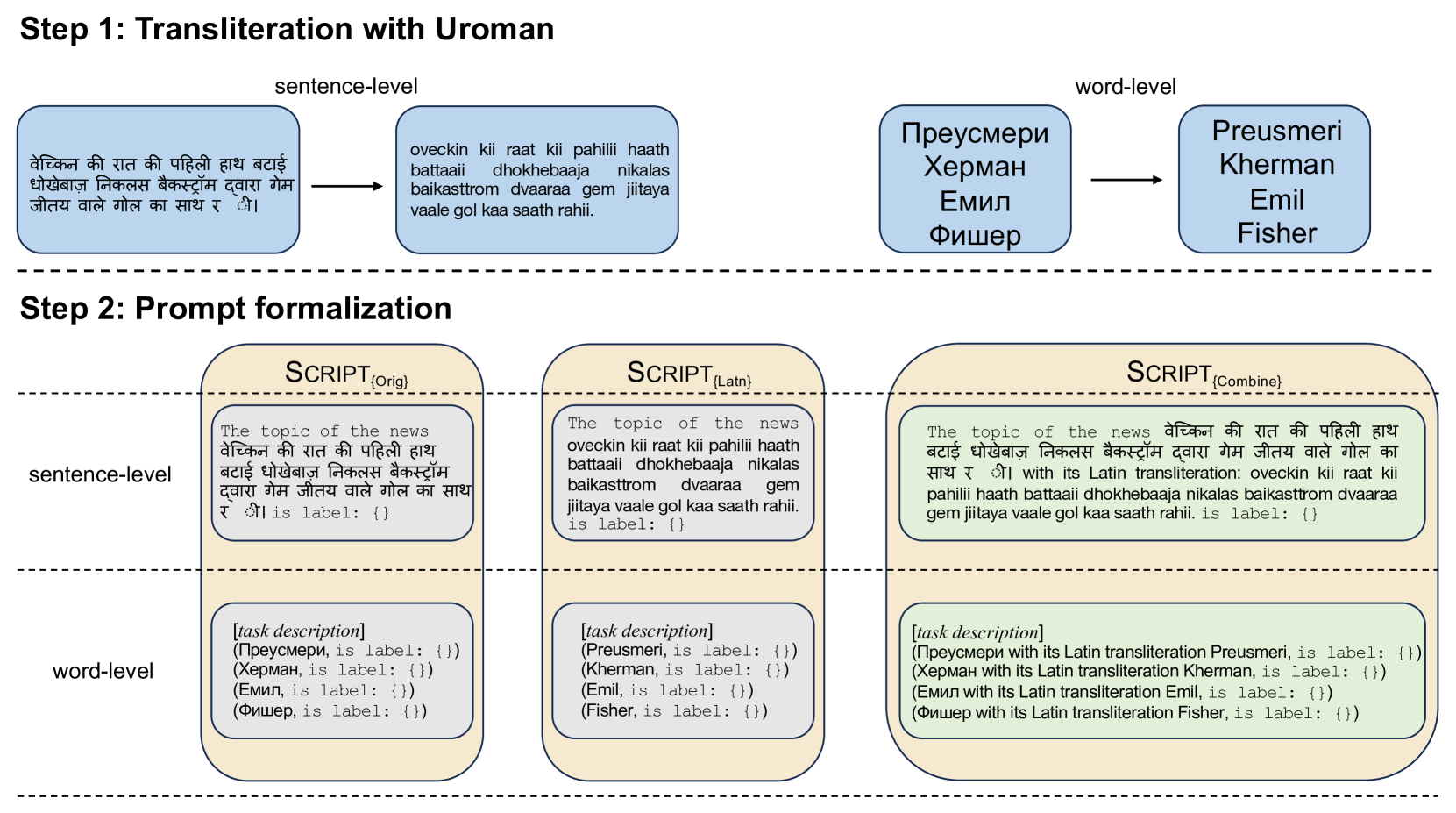
核心思路:论文的核心思路是利用音译将非拉丁语文本转换为拉丁语文本,从而使LLM能够更好地理解和处理这些文本。通过将非拉丁语文本转换为LLM更熟悉的拉丁语形式,可以提高LLM在低资源非拉丁语任务上的性能。论文同时探索了原始文字、拉丁文字和两者结合三种提示模板。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择低资源非拉丁语数据集和相应的任务(文本分类、序列标注);2) 设计三种不同的提示模板:原始文字、拉丁文字、原始文字+拉丁文字;3) 使用不同的LLM(不同大小的模型)在这些数据集上进行实验;4) 评估LLM在不同提示模板下的性能。
关键创新:论文的关键创新在于探索了音译在LLM上下文学习中的作用,并提出了三种不同的提示模板。与直接使用原始非拉丁语文本作为输入的方法相比,论文提出的方法能够显著提高LLM在低资源非拉丁语任务上的性能。此外,论文还分析了音译的有效性与任务类型和模型大小之间的关系。
关键设计:论文的关键设计包括:1) 三种提示模板的设计,分别使用原始文字、拉丁文字和两者结合的方式表示目标语言文本;2) 实验中选择了不同大小的LLM,以评估模型大小对音译效果的影响;3) 实验中选择了文本分类和序列标注两种不同的任务类型,以评估音译在不同任务上的有效性;4) 评估指标的选择,使用了准确率、F1值等常用指标来评估模型性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,音译对序列标注任务有显著提升,最高可达25%。不同大小的LLM在不同提示模板下的性能表现不同,表明音译的有效性与模型大小和任务类型有关。例如,对于序列标注任务,所有模型都受益于音译。
🎯 应用场景
该研究成果可应用于各种低资源非拉丁语的自然语言处理任务,例如机器翻译、文本摘要、情感分析等。通过提高LLM在这些语言上的性能,可以促进文化交流和信息共享,并为这些语言的使用者提供更好的服务。未来,该研究可以扩展到更多的低资源语言和任务,并探索更有效的音译方法。
📄 摘要(原文)
Decoder-only large language models (LLMs) excel in high-resource languages across various tasks through few-shot or even zero-shot in-context learning (ICL). However, their performance often does not transfer well to low-resource languages, especially those written in non-Latin scripts. Inspired by recent work that leverages transliteration in encoder-only models, we investigate whether transliteration is also effective in improving LLMs' performance for low-resource languages written in non-Latin scripts. To this end, we propose three prompt templates, where the target-language text is represented in (1) its original script, (2) Latin script, or (3) both. We apply these methods to several representative LLMs of different sizes on various tasks including text classification and sequential labeling. Our findings show that the effectiveness of transliteration varies by task type and model size. For instance, all models benefit from transliterations for sequential labeling (with increases of up to 25%).