Towards Human Understanding of Paraphrase Types in Large Language Models
作者: Dominik Meier, Jan Philip Wahle, Terry Ruas, Bela Gipp
分类: cs.CL
发布日期: 2024-07-02 (更新: 2025-02-18)
期刊: Proceedings of the 31st International Conference on Computational Linguistics (2025), pages 6298-6316
💡 一句话要点
提出APTY数据集,评估大型语言模型在原子释义类型上的理解能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 释义生成 原子释义类型 数据集构建 人类偏好 自然语言处理 文本改写
📋 核心要点
- 现有释义评估方法缺乏对语言模型生成释义时具体语言变化的细粒度解释。
- 论文提出APTY数据集,包含原子释义类型标注和人类偏好排序,用于评估和指导语言模型。
- 实验表明,ChatGPT在简单原子释义类型上表现较好,但在复杂结构上存在困难,APTY数据集可用于提升模型能力。
📝 摘要(中文)
释义代表了人类理解不同表达方式的直观能力。目前对语言模型的释义评估主要采用二元方法,对特定文本变化的解释性有限。原子释义类型(APT)将释义分解为不同的语言变化,并提供了语言表达灵活性的细粒度视图(例如,句法或词汇的转变)。本研究评估了人类对ChatGPT在生成具有十种APT和五种提示技术的英语释义方面的偏好。我们引入了APTY(原子释义类型)数据集,该数据集包含15位注释者提供的800个句子级和单词级注释。该数据集还提供了具有不同类型的释义的人类偏好排名,可用于使用RLHF和DPO方法微调模型。结果表明,ChatGPT和一个经过DPO训练的LLama 7B模型可以生成简单的APT,例如添加和删除,但在复杂的结构(例如,从属关系变化)方面表现不佳。本研究有助于理解语言模型在释义的哪些方面已经成功理解,以及哪些方面仍然难以捉摸。此外,我们展示了我们策划的数据集如何用于开发具有特定语言能力的语言模型。
🔬 方法详解
问题定义:现有语言模型释义评估方法主要采用二元判断,无法深入了解模型在生成释义时所做的具体语言修改,缺乏细粒度的可解释性。这使得我们难以理解模型在哪些语言能力上已经成功,以及哪些方面仍然存在不足。
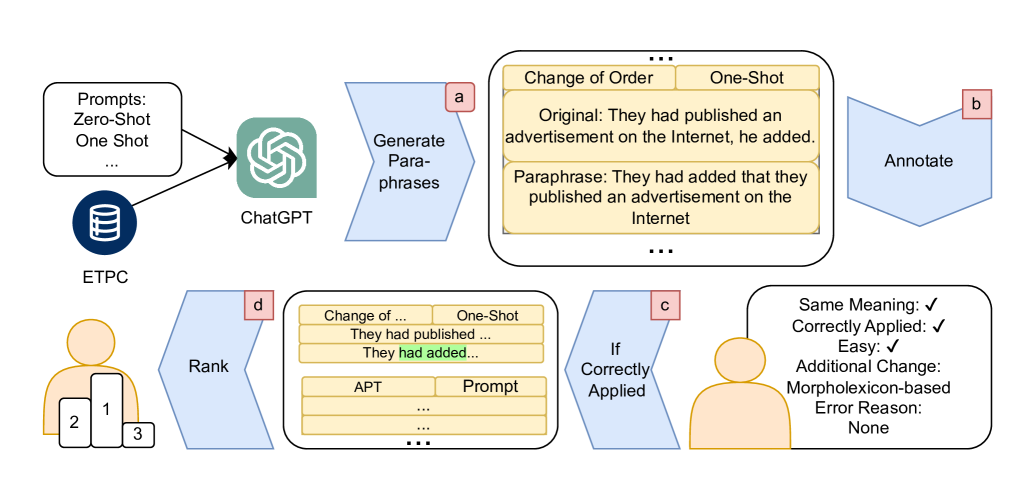
核心思路:论文的核心思路是将释义分解为更小的、原子级别的语言变化类型(Atomic Paraphrase Types, APTs),例如添加、删除、句法变化等。通过分析模型在不同APT上的表现,可以更精确地评估其释义能力,并指导模型改进。
技术框架:论文主要包含以下几个部分:1) 定义了一组原子释义类型(APTs);2) 构建了一个名为APTY的数据集,包含句子级和词汇级的APTs标注以及人类偏好排序;3) 使用APTY数据集评估了ChatGPT和DPO训练的LLama 7B模型在生成不同APTs释义方面的能力;4) 探讨了如何利用APTY数据集来提升语言模型的特定语言能力。
关键创新:论文的关键创新在于提出了原子释义类型(APTs)的概念,并构建了相应的APTY数据集。与传统的二元释义评估方法相比,APTs提供了更细粒度的释义分析,能够更准确地评估语言模型的释义能力。APTY数据集包含了人类偏好排序,可以用于通过RLHF或DPO等方法微调语言模型,提升其释义质量。
关键设计:APTY数据集包含800个句子级和词汇级的标注,由15位注释者完成。论文定义了10种APTs,涵盖了词汇、句法、语义等多个方面。人类偏好排序是通过比较不同APTs生成的释义,并让人类选择更符合要求的释义来获得的。在实验中,论文使用了不同的prompting技术来引导ChatGPT生成释义,并分析了其在不同APTs上的表现。
🖼️ 关键图片

📊 实验亮点
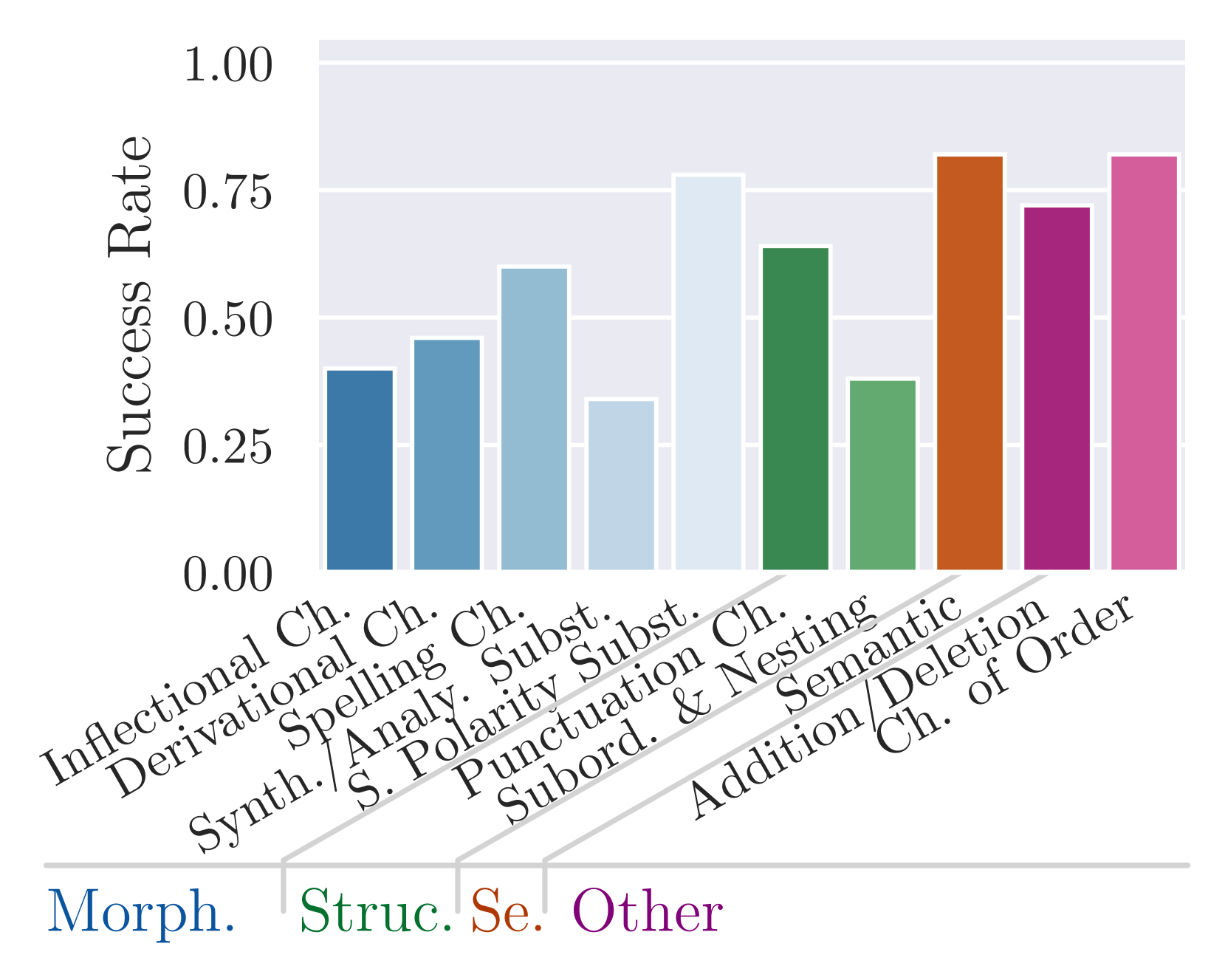
实验结果表明,ChatGPT和DPO训练的LLama 7B模型在生成简单的原子释义类型(如添加和删除)方面表现较好,但在处理复杂的结构变化(如从属关系变化)时存在困难。APTY数据集能够有效区分模型在不同APTs上的表现差异,并为模型改进提供指导。
🎯 应用场景
该研究成果可应用于提升大型语言模型的自然语言生成能力,尤其是在文本改写、机器翻译、文本摘要等领域。通过利用APTY数据集进行微调,可以使模型生成更符合人类偏好、更具多样性的释义,从而提高下游任务的性能和用户体验。未来,该研究可以扩展到更多语言和更复杂的释义场景。
📄 摘要(原文)
Paraphrases represent a human's intuitive ability to understand expressions presented in various different ways. Current paraphrase evaluations of language models primarily use binary approaches, offering limited interpretability of specific text changes. Atomic paraphrase types (APT) decompose paraphrases into different linguistic changes and offer a granular view of the flexibility in linguistic expression (e.g., a shift in syntax or vocabulary used). In this study, we assess the human preferences towards ChatGPT in generating English paraphrases with ten APTs and five prompting techniques. We introduce APTY (Atomic Paraphrase TYpes), a dataset of 800 sentence-level and word-level annotations by 15 annotators. The dataset also provides a human preference ranking of paraphrases with different types that can be used to fine-tune models with RLHF and DPO methods. Our results reveal that ChatGPT and a DPO-trained LLama 7B model can generate simple APTs, such as additions and deletions, but struggle with complex structures (e.g., subordination changes). This study contributes to understanding which aspects of paraphrasing language models have already succeeded at understanding and what remains elusive. In addition, we show how our curated datasets can be used to develop language models with specific linguistic capabilities.