GemmAr: Enhancing LLMs Through Arabic Instruction-Tuning
作者: Hasna Chouikhi, Manel Aloui, Cyrine Ben Hammou, Ghaith Chaabane, Haithem Kchaou, Chehir Dhaouadi
分类: cs.CL, cs.AI
发布日期: 2024-07-02 (更新: 2024-07-09)
💡 一句话要点
GemmAr:通过阿拉伯语指令微调增强大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 阿拉伯语NLP 指令微调 大型语言模型 数据集构建 Gemma-7B
📋 核心要点
- 现有大型语言模型在阿拉伯语NLP任务中表现不佳,主要原因是缺乏高质量的阿拉伯语指令数据集。
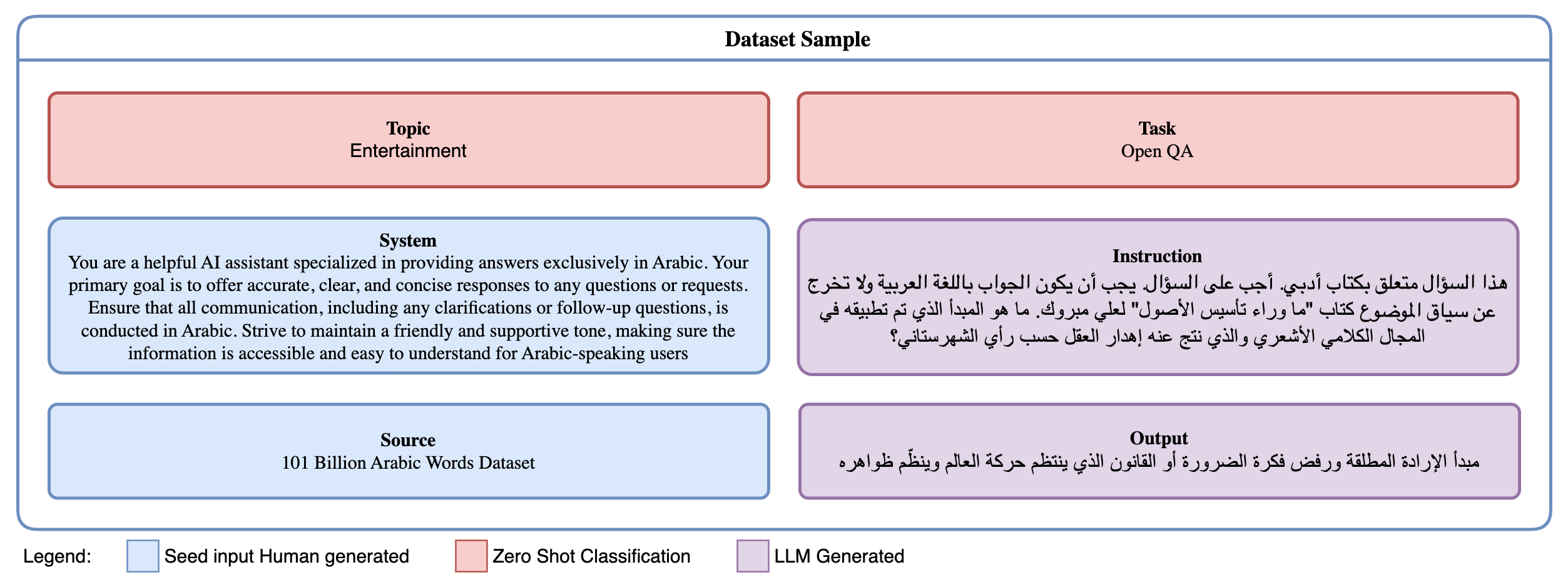
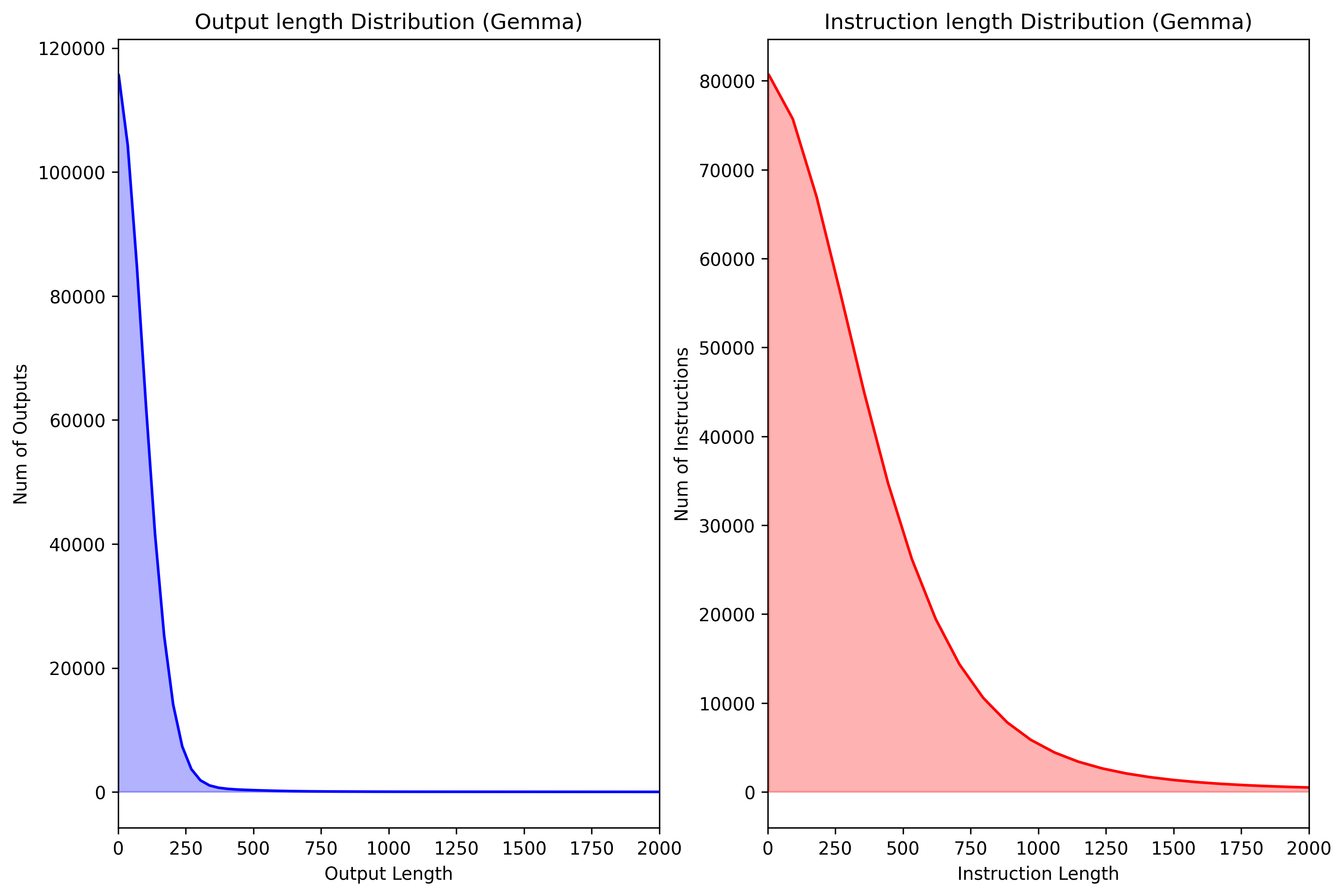
- 论文提出InstAr-500k数据集,包含50万条阿拉伯语指令,覆盖多个领域和指令类型,用于微调LLM。
- 通过在Gemma-7B上进行微调,并在多个阿拉伯语NLP基准测试中评估,验证了数据集的有效性,提升了模型性能。
📝 摘要(中文)
大型语言模型(LLMs)极大地影响了自然语言处理(NLP)领域,尤其是在英语方面。这些模型在理解和生成类人文本方面表现出强大的能力。语言模型的成功很大程度上取决于高质量指令数据集的可用性,这些数据集包含详细的任务描述和相应的响应,这对于训练模型准确地处理各种提示至关重要。然而,这些资源的可用性和质量因语言而异。虽然模型在英语方面表现良好,但由于缺乏用于微调阿拉伯语特定任务的数据集,它们在阿拉伯语等语言方面通常需要帮助。为了解决这个问题,我们引入了InstAr-500k,这是一个新的阿拉伯语指令数据集,通过生成和收集涵盖多个领域和指令类型的内容而创建。我们通过在多个下游任务上微调开源Gemma-7B模型来评估此数据集,以提高其功能。基于多次评估,我们微调后的模型在多个阿拉伯语NLP基准测试中取得了优异的性能。这些结果强调了我们的数据集在提升阿拉伯语语言模型能力方面的有效性。我们的指令数据集通过提供增强阿拉伯语NLP开发的资源,弥合了英语和阿拉伯语语言模型之间的性能差距。在此基础上,我们开发了一个专门用于擅长各种阿拉伯语NLP任务的模型GemmAr-7B-V1。
🔬 方法详解
问题定义:现有的大型语言模型在处理阿拉伯语NLP任务时,性能显著低于英语等资源丰富的语言。主要痛点在于缺乏高质量、大规模的阿拉伯语指令数据集,这限制了模型在阿拉伯语环境下的微调和优化,导致模型无法有效理解和生成阿拉伯语文本。
核心思路:论文的核心思路是构建一个高质量的阿拉伯语指令数据集InstAr-500k,并利用该数据集对开源的Gemma-7B模型进行指令微调。通过指令微调,使模型能够更好地理解和执行各种阿拉伯语NLP任务,从而提升模型在阿拉伯语环境下的性能。
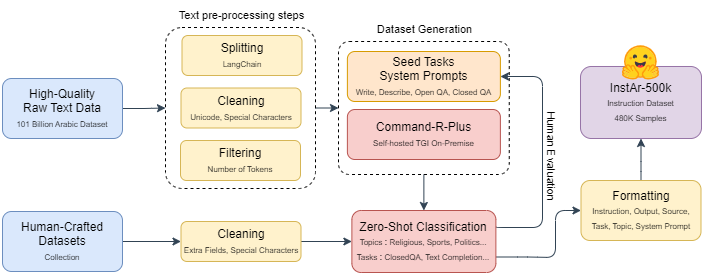
技术框架:整体框架包括两个主要阶段:1) 数据集构建阶段:生成和收集涵盖多个领域和指令类型的阿拉伯语指令数据,构建InstAr-500k数据集。2) 模型微调阶段:使用InstAr-500k数据集对Gemma-7B模型进行指令微调,得到针对阿拉伯语NLP任务优化的GemmAr-7B-V1模型。
关键创新:关键创新在于构建了大规模、高质量的阿拉伯语指令数据集InstAr-500k。与现有方法相比,该数据集覆盖了更广泛的领域和指令类型,能够更有效地指导模型学习阿拉伯语的语言特性和任务要求。此外,论文还验证了该数据集在提升开源LLM在阿拉伯语NLP任务上的性能方面的有效性。
关键设计:关于数据集构建的细节未知。关于模型微调,论文使用了开源的Gemma-7B模型作为基础模型,并使用InstAr-500k数据集进行指令微调。具体的参数设置、损失函数和网络结构等技术细节在论文中没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
论文通过在多个阿拉伯语NLP基准测试中评估微调后的GemmAr模型,证明了InstAr-500k数据集的有效性。具体性能数据和对比基线在摘要中未提及,但强调了该模型在多个基准测试中取得了优异的性能,表明该数据集能够显著提升LLM在阿拉伯语NLP任务上的能力。
🎯 应用场景
该研究成果可广泛应用于各种阿拉伯语自然语言处理任务,如机器翻译、文本摘要、情感分析、问答系统等。GemmAr模型能够提升阿拉伯语NLP应用的性能和用户体验,促进阿拉伯语信息处理技术的发展,并为阿拉伯语地区的数字化转型提供支持。该研究还有助于推动多语言自然语言处理的发展,缩小不同语言之间的技术差距。
📄 摘要(原文)
Large language models (LLMs) have greatly impacted the natural language processing (NLP) field, particularly for the English language. These models have demonstrated capabilities in understanding and generating human-like text. The success of language models largely depends on the availability of high-quality instruction datasets, which consist of detailed task descriptions and corresponding responses that are essential for training the models to address a variety of prompts accurately. However, the availability and quality of these resources vary by language. While models perform well in English, they often need help with languages like Arabic, due to the lack of datasets for fine-tuning Arabic-specific tasks. To address this issue, we introduce InstAr-500k, a new Arabic instruction dataset created by generating and collecting content that covers several domains and instruction types. We assess this dataset by fine-tuning an open-source Gemma-7B model on several downstream tasks to improve its functionality. Based on multiple evaluations, our fine-tuned model achieves excellent performance on several Arabic NLP benchmarks. These outcomes emphasize the effectiveness of our dataset in elevating the capabilities of language models for Arabic. Our instruction dataset bridges the performance gap between English and Arabic language models by providing resources that amplify Arabic NLP development. Building on this foundation, we developed a model, GemmAr-7B-V1, specifically tuned to excel at a wide range of Arabic NLP tasks.