Large Language Model Enhanced Knowledge Representation Learning: A Survey
作者: Xin Wang, Zirui Chen, Haofen Wang, Leong Hou U, Zhao Li, Wenbin Guo
分类: cs.CL, cs.AI
发布日期: 2024-07-01 (更新: 2025-04-08)
💡 一句话要点
综述:利用大型语言模型增强知识表示学习,解决知识图谱稀疏性问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识表示学习 大型语言模型 知识图谱 信息稀疏性 Transformer 编码器-解码器 下游任务
📋 核心要点
- 知识图谱的稀疏性限制了知识表示学习(KRL)方法的性能,阻碍了其在下游任务中的应用。
- 该综述探讨了如何利用大型语言模型(LLM)的强大能力,通过融合文本信息来缓解知识图谱的稀疏性问题,提升KRL效果。
- 综述总结了基于编码器、编码器-解码器和解码器三种LLM增强KRL的方法,并展望了该领域未来的研究方向。
📝 摘要(中文)
知识表示学习(KRL)通过将知识图谱(KG)中的知识事实投影到向量空间,对于将符号知识应用于下游任务至关重要。尽管KRL方法在建模KG结构信息方面有效,但它们受到KG稀疏性的影响。构建于Transformer架构之上的大型语言模型(LLM)的兴起,通过结合文本信息来解决KG中的信息稀疏性,为增强KRL提供了有希望的机会。基于LLM增强的KRL方法,包括利用详细上下文信息的基于编码器的方法,利用统一的Seq2Seq模型进行全面编码和解码的基于编码器-解码器的方法,以及利用来自大型语料库的广泛知识的基于解码器的方法,已显著提高了KRL在解决各种下游任务中的有效性和泛化能力。本文对下游任务进行了广泛的概述,同时确定了这些不断发展的领域中新兴的研究方向。
🔬 方法详解
问题定义:知识表示学习旨在将知识图谱中的实体和关系嵌入到低维向量空间中,以便进行知识推理和下游任务。然而,现实世界的知识图谱通常非常稀疏,导致许多实体和关系缺乏足够的上下文信息,从而影响了知识表示学习的性能。现有的KRL方法难以有效处理这种稀疏性问题。
核心思路:该综述的核心思路是利用大型语言模型(LLM)强大的文本理解和生成能力,将知识图谱中的实体和关系与丰富的文本信息相结合,从而缓解知识图谱的稀疏性问题。通过融合文本信息,可以为实体和关系提供更全面的上下文表示,提高知识表示学习的质量。
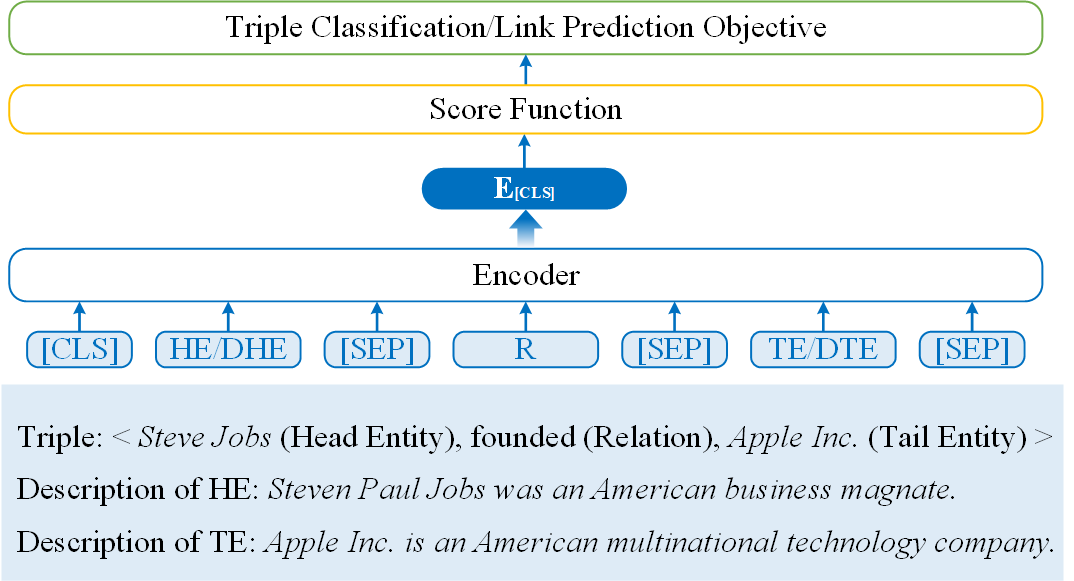
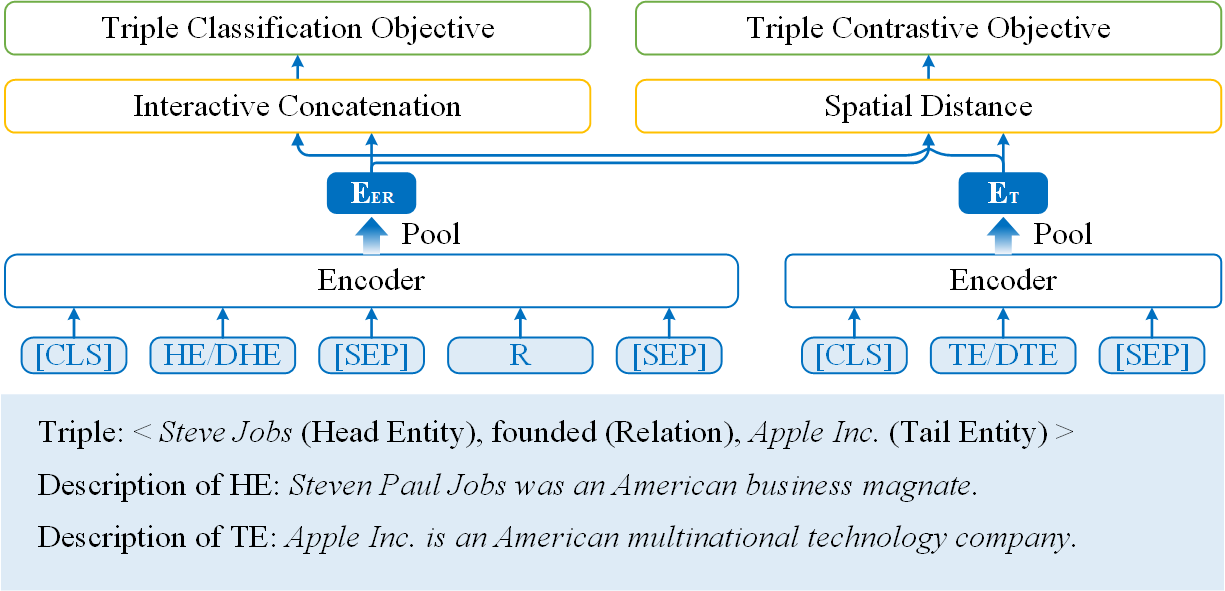
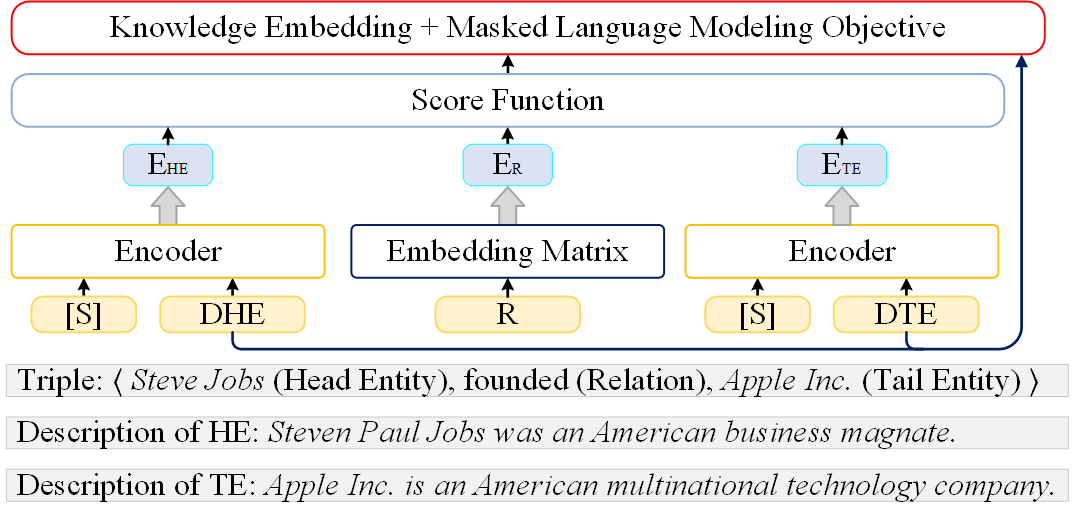
技术框架:该综述将LLM增强的KRL方法分为三类:基于编码器的方法、基于编码器-解码器的方法和基于解码器的方法。基于编码器的方法利用LLM对实体和关系的文本描述进行编码,生成上下文感知的嵌入表示。基于编码器-解码器的方法使用Seq2Seq模型对知识图谱中的三元组进行编码和解码,从而学习实体和关系的表示。基于解码器的方法利用LLM生成与知识图谱中的实体和关系相关的文本,从而丰富实体和关系的语义信息。
关键创新:该综述的关键创新在于系统地总结和分析了利用大型语言模型增强知识表示学习的各种方法,并对这些方法的优缺点进行了比较。此外,该综述还指出了该领域未来的研究方向,例如如何更好地融合知识图谱的结构信息和文本信息,以及如何利用LLM进行知识推理。
关键设计:不同的LLM增强KRL方法在关键设计上有所不同。例如,基于编码器的方法通常需要选择合适的LLM作为编码器,并设计合适的损失函数来训练模型。基于编码器-解码器的方法需要设计合适的Seq2Seq模型结构,并选择合适的训练目标。基于解码器的方法需要设计合适的文本生成策略,并评估生成文本的质量。
🖼️ 关键图片
📊 实验亮点
该综述总结了多种利用LLM增强KRL的方法,并分析了它们在不同下游任务上的表现。虽然没有提供具体的实验数据,但综述强调了LLM在缓解知识图谱稀疏性方面的有效性,并指出LLM增强的KRL方法在各种下游任务中都取得了显著的性能提升。
🎯 应用场景
该研究成果可广泛应用于知识图谱相关的下游任务,如知识图谱补全、实体链接、关系抽取、问答系统等。通过提升知识表示学习的质量,可以提高这些下游任务的性能,从而为智能搜索、推荐系统、自然语言理解等领域带来实际价值和未来影响。
📄 摘要(原文)
Knowledge Representation Learning (KRL) is crucial for enabling applications of symbolic knowledge from Knowledge Graphs (KGs) to downstream tasks by projecting knowledge facts into vector spaces. Despite their effectiveness in modeling KG structural information, KRL methods are suffering from the sparseness of KGs. The rise of Large Language Models (LLMs) built on the Transformer architecture presents promising opportunities for enhancing KRL by incorporating textual information to address information sparsity in KGs. LLM-enhanced KRL methods, including three key approaches, encoder-based methods that leverage detailed contextual information, encoder-decoder-based methods that utilize a unified Seq2Seq model for comprehensive encoding and decoding, and decoder-based methods that utilize extensive knowledge from large corpora, have significantly advanced the effectiveness and generalization of KRL in addressing a wide range of downstream tasks. This work provides a broad overview of downstream tasks while simultaneously identifying emerging research directions in these evolving domains.