Step-Controlled DPO: Leveraging Stepwise Error for Enhanced Mathematical Reasoning
作者: Zimu Lu, Aojun Zhou, Ke Wang, Houxing Ren, Weikang Shi, Junting Pan, Mingjie Zhan, Hongsheng Li
分类: cs.CL
发布日期: 2024-06-30 (更新: 2024-07-15)
💡 一句话要点
提出Step-Controlled DPO,通过步进式误差监督提升数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 直接偏好优化 步进式误差监督 数学推理 大型语言模型 错误识别
📋 核心要点
- 现有DPO方法在数学推理任务中缺乏对推理步骤错误的细粒度监督,导致模型难以识别和纠正错误。
- SCDPO通过生成在特定步骤引入错误的负样本,为模型提供步进式误差监督,从而提升模型对错误推理的识别能力。
- 实验表明,SCDPO在多个SFT模型上优于DPO,并在InternLM2-20B上取得了领先的数学推理性能,GSM8K达到88.5%,MATH达到58.1%。
📝 摘要(中文)
直接偏好优化(DPO)已被证明能有效提升大型语言模型(LLM)在推理和对齐等下游任务上的性能。本文提出Step-Controlled DPO(SCDPO),该方法通过创建在特定步骤开始出错的数学推理过程的反例,自动提供步进式误差监督。通过在DPO训练中应用这些样本,SCDPO可以更好地对齐模型,使其理解推理错误并输出准确的推理步骤。我们将SCDPO应用于代码集成和思维链解决方案,经验表明,与朴素DPO相比,SCDPO在三种不同的SFT模型上始终能提高性能,包括一个现有的SFT模型和我们微调的两个模型。对SCDPO和DPO的信用分配的定性分析表明,SCDPO在识别数学解决方案中的错误方面非常有效。然后,我们将SCDPO应用于InternLM2-20B模型,从而产生一个20B模型,在GSM8K上达到88.5%的高分,在MATH上达到58.1%的高分,与所有其他开源LLM相媲美,显示了我们方法的巨大潜力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在数学推理任务中,由于缺乏对推理步骤的细粒度错误监督,导致模型难以识别和纠正推理错误的问题。现有的DPO方法通常只关注最终结果的正确性,而忽略了中间推理步骤的正确性,这使得模型难以学习到正确的推理路径。
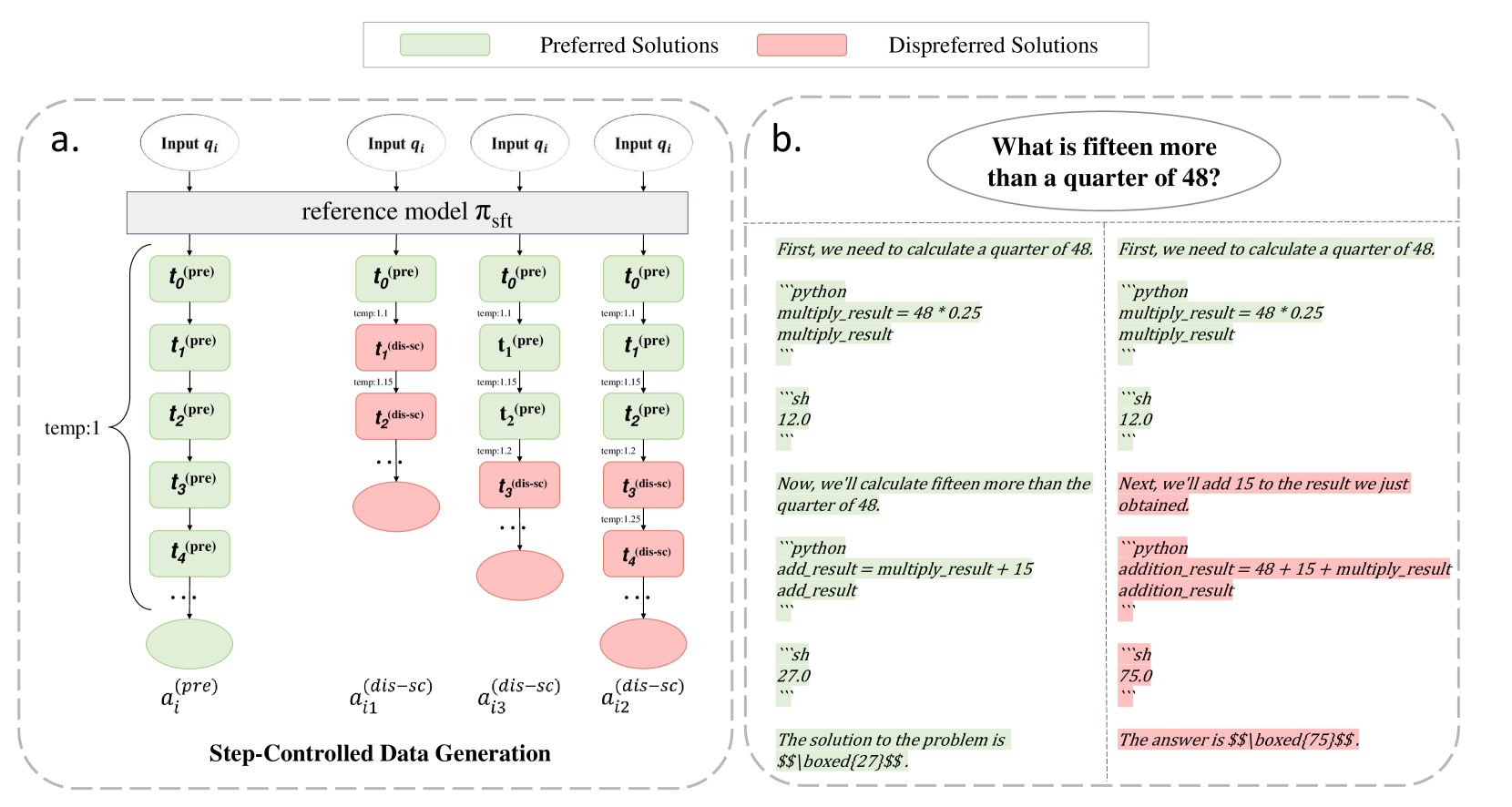
核心思路:论文的核心思路是通过生成在特定步骤引入错误的负样本,为模型提供步进式误差监督。具体来说,对于一个正确的数学推理过程,SCDPO会生成一系列负样本,每个负样本在不同的步骤开始出错。通过对比这些负样本和正确的推理过程,模型可以学习到在每个步骤应该采取的正确行动,从而提升模型的推理能力。
技术框架:SCDPO方法主要包含以下几个步骤:1) 获取正确的数学推理过程;2) 在不同的步骤引入错误,生成负样本;3) 使用DPO算法,以正确的推理过程作为正样本,生成的负样本作为负样本,训练语言模型。整个框架的核心是负样本的生成策略,即如何在不同的步骤引入合理的错误。
关键创新:SCDPO最重要的技术创新点在于其步进式误差监督的思想。与传统的DPO方法只关注最终结果的正确性不同,SCDPO通过对中间推理步骤进行监督,使得模型可以学习到更加细粒度的推理知识。这种步进式监督的方式可以帮助模型更好地理解推理过程中的错误,从而提升模型的推理能力。
关键设计:SCDPO的关键设计在于如何生成合理的负样本。论文中并没有详细描述生成负样本的具体方法,这部分内容可能需要参考其他文献或者根据具体的任务进行设计。此外,DPO算法中的超参数设置,例如学习率、batch size等,也会影响SCDPO的性能。论文中使用了标准的DPO损失函数,并没有进行特殊的修改。
🖼️ 关键图片


📊 实验亮点
SCDPO在多个数学推理数据集上取得了显著的性能提升。在GSM8K数据集上,使用SCDPO训练的InternLM2-20B模型达到了88.5%的准确率,在MATH数据集上达到了58.1%的准确率,超越了其他开源LLM。此外,定性分析表明,SCDPO能够更准确地识别数学推理过程中的错误步骤,从而更好地指导模型的学习。
🎯 应用场景
SCDPO方法可应用于各种需要复杂推理的任务,例如数学问题求解、代码生成、逻辑推理等。该方法可以提高LLM在这些任务中的准确性和可靠性,从而在教育、科研、金融等领域发挥重要作用。未来,SCDPO可以与其他技术结合,例如知识图谱、符号推理等,进一步提升LLM的推理能力。
📄 摘要(原文)
Direct Preference Optimization (DPO) has proven effective at improving the performance of large language models (LLMs) on downstream tasks such as reasoning and alignment. In this work, we propose Step-Controlled DPO (SCDPO), a method for automatically providing stepwise error supervision by creating negative samples of mathematical reasoning rationales that start making errors at a specified step. By applying these samples in DPO training, SCDPO can better align the model to understand reasoning errors and output accurate reasoning steps. We apply SCDPO to both code-integrated and chain-of-thought solutions, empirically showing that it consistently improves the performance compared to naive DPO on three different SFT models, including one existing SFT model and two models we finetuned. Qualitative analysis of the credit assignment of SCDPO and DPO demonstrates the effectiveness of SCDPO at identifying errors in mathematical solutions. We then apply SCDPO to an InternLM2-20B model, resulting in a 20B model that achieves high scores of 88.5% on GSM8K and 58.1% on MATH, rivaling all other open-source LLMs, showing the great potential of our method.