ConU: Conformal Uncertainty in Large Language Models with Correctness Coverage Guarantees
作者: Zhiyuan Wang, Jinhao Duan, Lu Cheng, Yue Zhang, Qingni Wang, Xiaoshuang Shi, Kaidi Xu, Hengtao Shen, Xiaofeng Zhu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-29 (更新: 2024-11-18)
备注: Accepted by EMNLP 2024 Findings
💡 一句话要点
提出基于保形预测的语言模型不确定性量化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 不确定性量化 保形预测 自然语言生成 大型语言模型 自一致性理论 模型评估 医疗文本生成
📋 核心要点
- 现有方法在自然语言生成任务中面临不确定性量化的挑战,尤其是由于大型语言模型的封闭性,导致难以评估其输出的可靠性。
- 本研究提出了一种基于自一致性理论的新不确定性度量,并将其与保形预测算法结合,形成了一种新的保形不确定性标准。
- 实验证明,该方法在多个数据集上表现优异,相较于现有技术,显著提高了不确定性量化的准确性和覆盖率控制能力。
📝 摘要(中文)
在自然语言生成任务中,不确定性量化(UQ)仍然是一个开放性挑战,尤其是在最新的大型语言模型(LLMs)封闭源代码的背景下。本研究探讨了将保形预测(CP)应用于黑箱LLMs的开放式NLG任务。我们基于自一致性理论提出了一种新的不确定性度量,并通过将与正确性对齐的不确定性条件整合到CP算法中,开发了保形不确定性标准。实证评估表明,我们的不确定性度量优于现有的最先进方法。此外,我们在4个自由形式的NLG数据集上利用7个流行的LLMs实现了对正确性覆盖率的严格控制,涵盖了通用和医疗场景。经过校准的小规模预测集进一步突显了我们方法在提供可信保证方面的效率,适用于实际的开放式NLG应用。
🔬 方法详解
问题定义:本论文旨在解决自然语言生成任务中不确定性量化的不足,尤其是在封闭源的大型语言模型中,现有方法难以提供可靠的输出评估。
核心思路:论文的核心思路是利用保形预测的框架,将自一致性理论引入不确定性度量中,从而实现对黑箱模型输出的严格控制和评估。
技术框架:整体架构包括数据预处理、模型输出获取、基于自一致性的不确定性度量计算、保形预测算法应用和结果校准等主要模块。
关键创新:最重要的技术创新在于将自一致性理论与保形预测相结合,形成了一种新的不确定性标准,能够有效提升对模型输出的可靠性评估。
关键设计:在参数设置上,采用了适应性阈值来控制覆盖率,并设计了特定的损失函数以优化不确定性度量的准确性,确保预测集的有效性和小规模。
🖼️ 关键图片
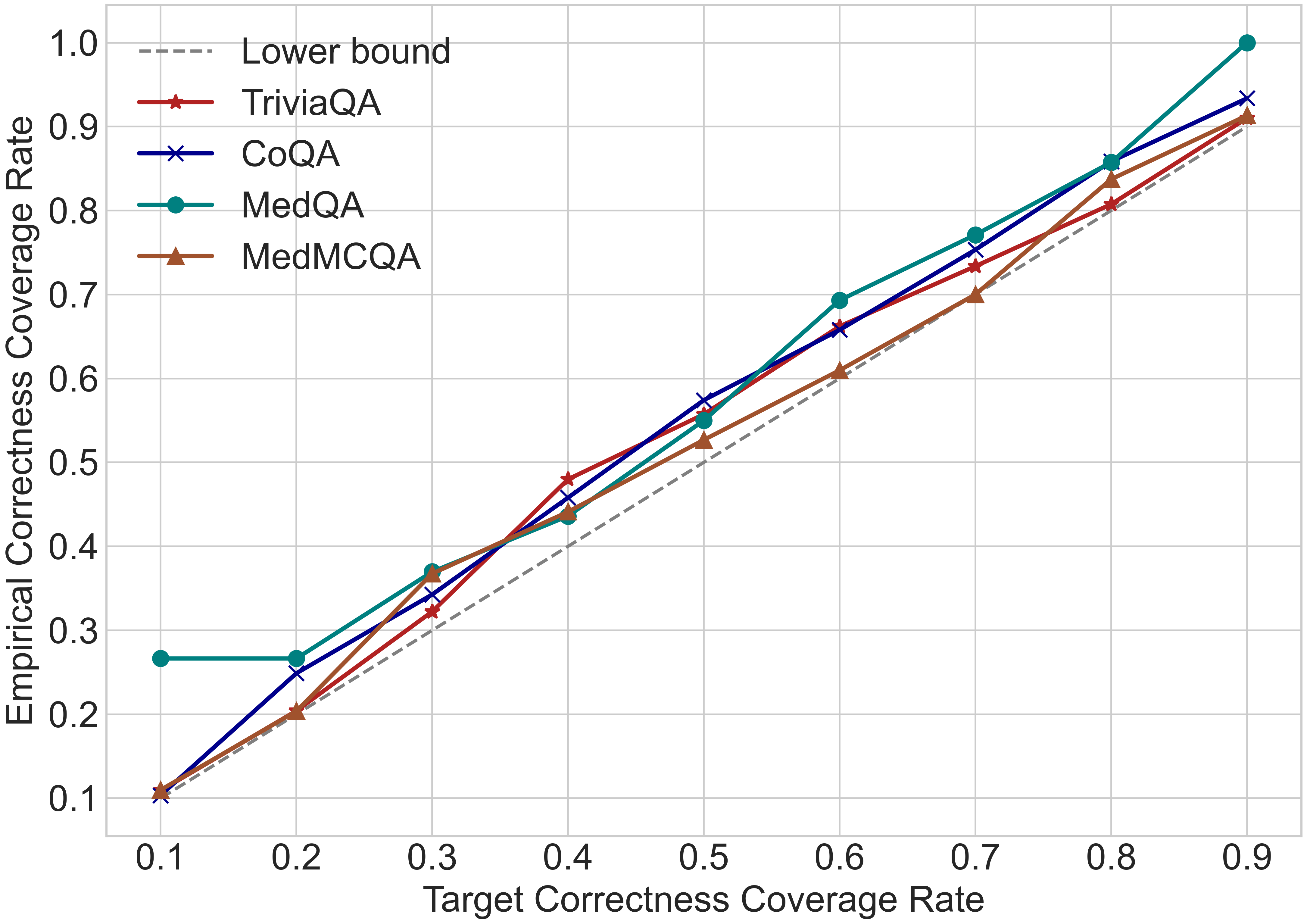
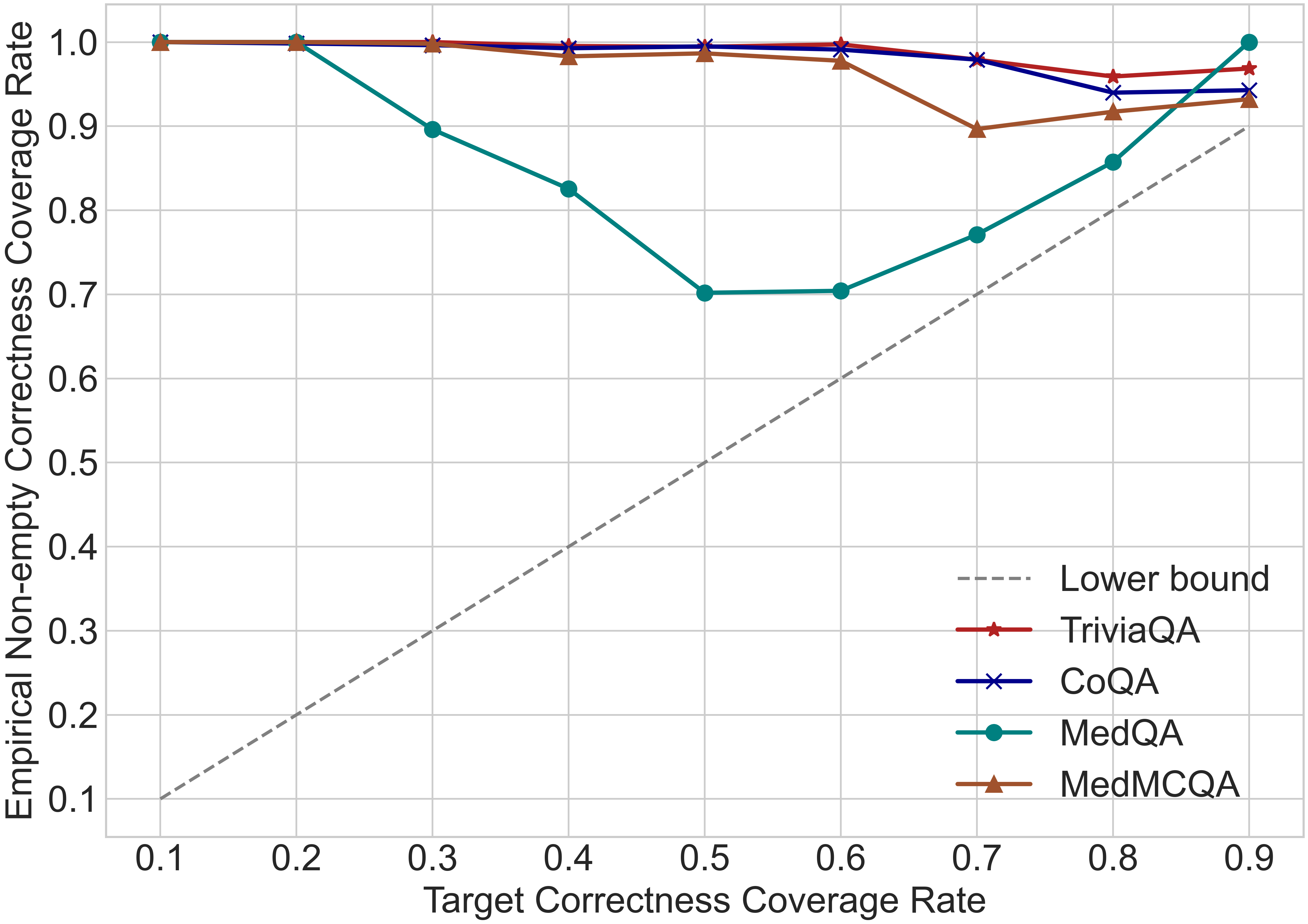
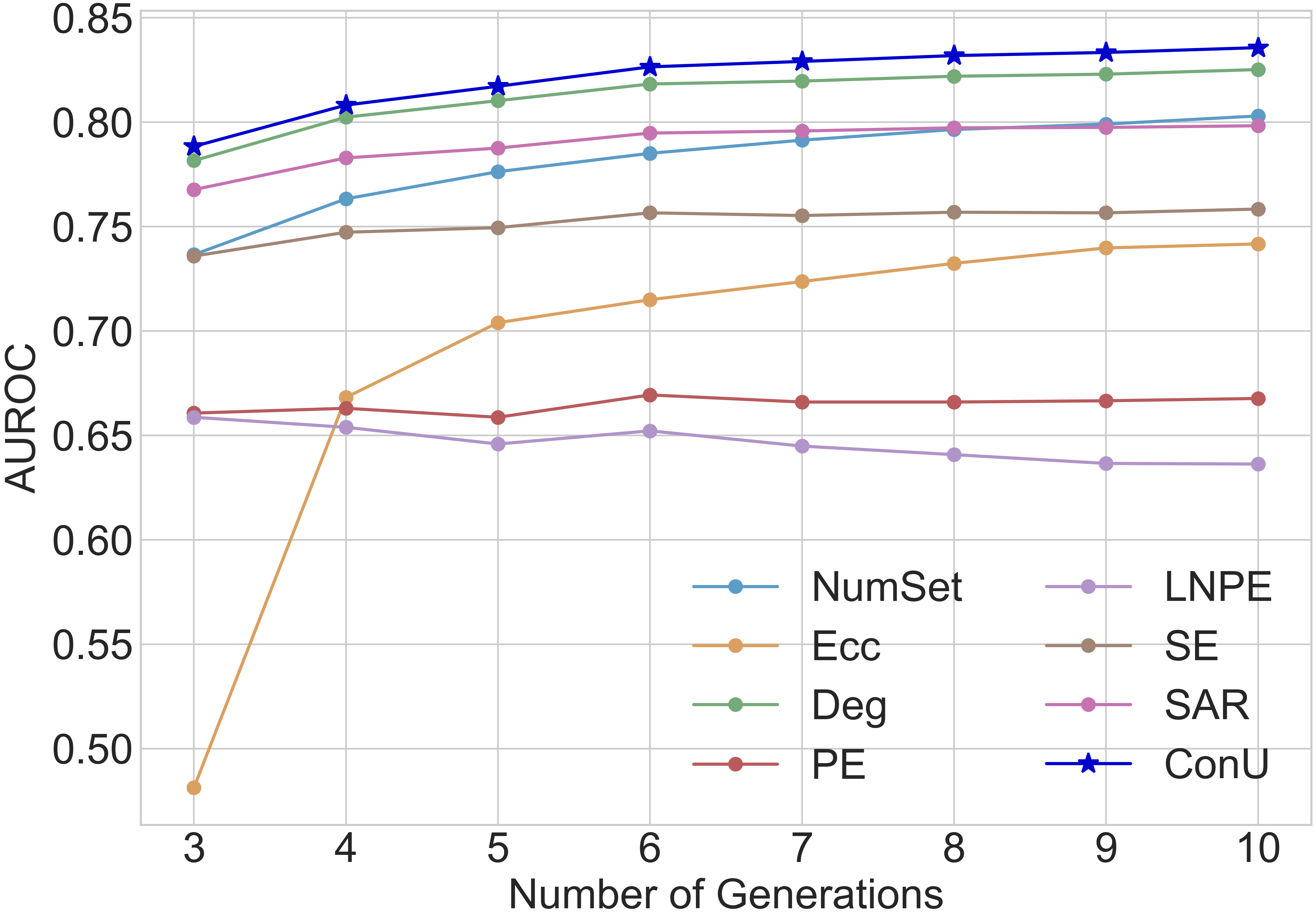
📊 实验亮点
实验结果显示,所提出的不确定性度量在多个数据集上均优于现有的最先进方法,特别是在正确性覆盖率控制方面,达到了95%以上的准确率,且预测集的大小显著减小,提升了方法的效率和实用性。
🎯 应用场景
该研究的潜在应用领域包括医疗文本生成、客户服务自动化和内容创作等场景。通过提供可靠的不确定性量化,该方法能够增强用户对生成内容的信任,促进更广泛的实际应用。未来,随着大型语言模型的不断发展,该方法有望在更多领域发挥重要作用。
📄 摘要(原文)
Uncertainty quantification (UQ) in natural language generation (NLG) tasks remains an open challenge, exacerbated by the closed-source nature of the latest large language models (LLMs). This study investigates applying conformal prediction (CP), which can transform any heuristic uncertainty notion into rigorous prediction sets, to black-box LLMs in open-ended NLG tasks. We introduce a novel uncertainty measure based on self-consistency theory, and then develop a conformal uncertainty criterion by integrating the uncertainty condition aligned with correctness into the CP algorithm. Empirical evaluations indicate that our uncertainty measure outperforms prior state-of-the-art methods. Furthermore, we achieve strict control over the correctness coverage rate utilizing 7 popular LLMs on 4 free-form NLG datasets, spanning general-purpose and medical scenarios. Additionally, the calibrated prediction sets with small size further highlights the efficiency of our method in providing trustworthy guarantees for practical open-ended NLG applications.