LLMs-as-Instructors: Learning from Errors Toward Automating Model Improvement
作者: Jiahao Ying, Mingbao Lin, Yixin Cao, Wei Tang, Bo Wang, Qianru Sun, Xuanjing Huang, Shuicheng Yan
分类: cs.CL
发布日期: 2024-06-29
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出LLMs-as-Instructors框架,利用大模型自动提升小模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型训练 错误分析 对比学习 知识蒸馏
📋 核心要点
- 现有小模型训练缺乏针对性,难以有效提升特定任务性能,尤其是在错误样本上的学习。
- LLMs-as-Instructors框架利用大模型分析小模型的错误,生成针对性训练数据,提升训练效率。
- 实验表明,该框架显著提升了小模型在数学、编码和知识问答等任务上的性能,甚至超越了ChatGPT。
📝 摘要(中文)
本文介绍了一种创新的“LLMs-as-Instructors”框架,该框架利用先进的大语言模型(LLMs)自主增强较小目标模型的训练。受到“从错误中学习”理论的启发,该框架采用一个指导者LLM来细致地分析目标模型中的特定错误,从而促进有针对性和高效的训练循环。在该框架内,我们实施了两种策略:“从错误中学习”,它仅关注不正确的响应来定制训练数据;以及“通过对比从错误中学习”,它使用对比学习来分析正确和不正确的响应,以更深入地理解错误。我们使用多个开源模型进行的实证研究表明,在包括数学推理、编码能力和事实知识在内的多个基准测试中,性能得到了显著提高。值得注意的是,改进后的Llama-3-8b-Instruction已经超越了ChatGPT,这说明了我们方法的有效性。通过利用这两种策略的优势,我们在领域内和领域外的基准测试中都获得了更均衡的性能提升。我们的代码可以在https://yingjiahao14.github.io/LLMs-as-Instructors-pages/找到。
🔬 方法详解
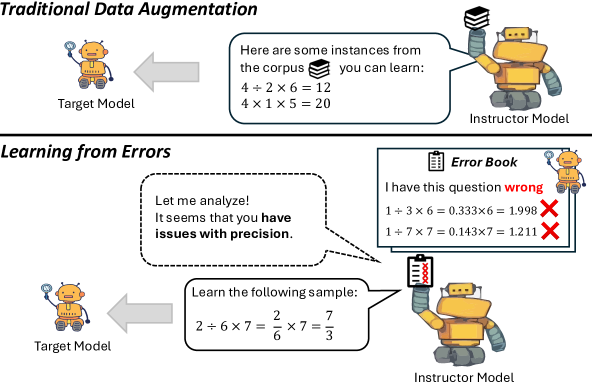
问题定义:论文旨在解决如何更有效地训练小规模语言模型,使其在特定任务上达到甚至超越大型模型的性能。现有方法通常采用通用数据集进行训练,缺乏针对性,尤其是在处理模型容易出错的样本时,训练效果不佳。因此,如何让小模型从自身的错误中学习,成为一个关键问题。
核心思路:论文的核心思路是利用大型语言模型(LLMs)作为“指导者”,分析小模型的错误,并生成针对性的训练数据。这种方法模拟了人类学习的过程,即通过识别错误、分析原因并进行针对性练习来提高技能。通过让LLM扮演指导者的角色,可以更有效地指导小模型进行学习。
技术框架:LLMs-as-Instructors框架包含以下主要阶段:1) 错误分析:使用目标模型对验证集进行预测,识别错误样本。2) 指导者LLM:使用LLM(如GPT-4)分析错误样本,理解错误原因,并生成新的训练样本。3) 数据增强:将生成的训练样本添加到原始训练集中,用于训练目标模型。4) 模型训练:使用增强后的数据集训练目标模型。论文提出了两种策略:“从错误中学习”(Learning from Error)和“通过对比从错误中学习”(Learning from Error by Contrast)。前者只关注错误样本,后者则同时分析正确和错误样本。
关键创新:该方法的核心创新在于利用LLM作为指导者,自动生成针对性的训练数据。与传统的数据增强方法相比,这种方法能够更准确地识别模型的弱点,并生成更有效的训练样本。此外,通过对比学习,可以更深入地理解错误的原因,从而生成更具针对性的训练数据。
关键设计:在“从错误中学习”策略中,LLM被提示分析错误样本,并生成类似的但正确的样本。在“通过对比从错误中学习”策略中,LLM被提示同时分析正确和错误样本,并生成能够区分两者的样本。具体的提示工程(prompt engineering)对于LLM的性能至关重要。论文中使用了精心设计的提示语,以确保LLM能够有效地分析错误并生成高质量的训练数据。损失函数方面,主要使用交叉熵损失函数进行训练。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过LLMs-as-Instructors框架训练的Llama-3-8b-Instruction模型在多个基准测试中取得了显著提升,甚至超越了ChatGPT。具体而言,在数学推理、编码能力和事实知识等方面均有明显改进。通过结合“从错误中学习”和“通过对比从错误中学习”两种策略,模型在领域内和领域外的基准测试中都获得了更均衡的性能提升。
🎯 应用场景
该研究成果可广泛应用于各种需要定制化模型训练的场景,例如特定领域的知识问答、代码生成、数学推理等。通过利用LLMs-as-Instructors框架,可以显著降低训练成本,提高模型性能,加速人工智能技术在各行业的落地。未来,该方法有望扩展到其他模态,例如图像和语音,实现更广泛的应用。
📄 摘要(原文)
This paper introduces the innovative "LLMs-as-Instructors" framework, which leverages the advanced Large Language Models (LLMs) to autonomously enhance the training of smaller target models. Inspired by the theory of "Learning from Errors", this framework employs an instructor LLM to meticulously analyze the specific errors within a target model, facilitating targeted and efficient training cycles. Within this framework, we implement two strategies: "Learning from Error," which focuses solely on incorrect responses to tailor training data, and "Learning from Error by Contrast", which uses contrastive learning to analyze both correct and incorrect responses for a deeper understanding of errors. Our empirical studies, conducted with several open-source models, demonstrate significant improvements across multiple benchmarks, including mathematical reasoning, coding abilities, and factual knowledge. Notably, the refined Llama-3-8b-Instruction has outperformed ChatGPT, illustrating the effectiveness of our approach. By leveraging the strengths of both strategies, we have attained a more balanced performance improvement on both in-domain and out-of-domain benchmarks. Our code can be found at https://yingjiahao14.github.io/LLMs-as-Instructors-pages/.