Self-Translate-Train: Enhancing Cross-Lingual Transfer of Large Language Models via Inherent Capability
作者: Ryokan Ri, Shun Kiyono, Sho Takase
分类: cs.CL
发布日期: 2024-06-29 (更新: 2024-09-17)
💡 一句话要点
提出Self-Translate-Train方法,提升大型语言模型在跨语言迁移中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言迁移 大型语言模型 自翻译训练 低资源语言 零样本学习
📋 核心要点
- 现有跨语言迁移方法在低资源语言上表现不佳,主要原因是语言间内部表征不对齐。
- Self-Translate-Train方法利用LLM自身翻译能力,生成目标语言数据并进行微调,从而提升跨语言迁移性能。
- 实验结果表明,Self-Translate-Train方法优于零样本迁移,验证了该方法在激发LLM跨语言能力方面的有效性。
📝 摘要(中文)
通过微调多语言预训练模型进行零样本跨语言迁移在低资源语言上展现了潜力,但通常受到语言间内部表征不对齐的影响。我们假设,即使模型在微调中不能有效地跨语言泛化,它仍然捕获了对跨语言迁移有用的跨语言对应关系。我们通过Self-Translate-Train方法探索了这个假设,该方法让大型语言模型(LLM)将训练数据翻译成目标语言,并用其自身生成的数据对模型进行微调。通过证明Self-Translate-Train优于零样本迁移,我们鼓励进一步探索更好的方法来激发LLM的跨语言能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在跨语言迁移中,由于不同语言的内部表征不对齐,导致零样本迁移效果不佳的问题。现有方法难以有效利用LLM中蕴含的跨语言知识,尤其是在低资源语言场景下,性能提升有限。
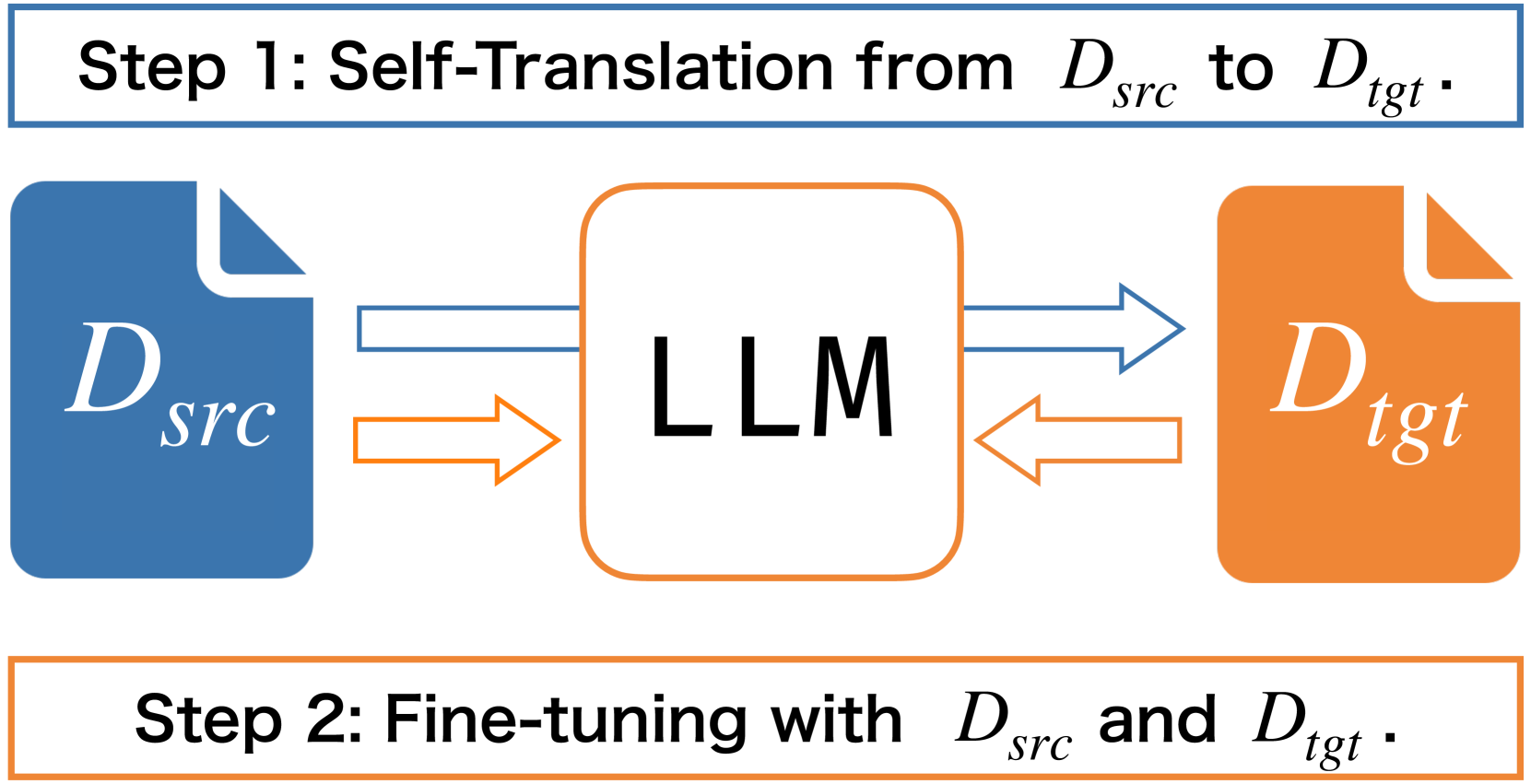
核心思路:论文的核心思路是利用LLM自身具备的翻译能力,将源语言的训练数据翻译成目标语言,然后使用这些翻译后的数据对LLM进行微调。这样做的目的是让模型更好地理解目标语言的语义信息,从而提升其在目标语言上的泛化能力。作者认为即使模型不能直接进行有效的跨语言泛化,其内部仍然蕴含着有用的跨语言对应关系,可以通过自翻译训练来激发。
技术框架:Self-Translate-Train方法主要包含两个阶段:1) 数据翻译阶段:使用LLM将源语言的训练数据翻译成目标语言。这一步的关键在于选择合适的LLM和翻译策略,以保证翻译质量。2) 模型微调阶段:使用翻译后的数据对LLM进行微调。微调的目标是让模型适应目标语言的语义特征,从而提升其在目标语言上的性能。
关键创新:该方法最重要的创新点在于利用LLM自身的翻译能力来生成训练数据,避免了对外部翻译资源的依赖。这种自翻译训练的方式能够更好地利用LLM内部蕴含的跨语言知识,从而提升跨语言迁移的性能。与传统的零样本迁移或依赖外部翻译的方法相比,Self-Translate-Train更加高效和灵活。
关键设计:论文中可能涉及的关键设计包括:1) LLM的选择:选择具有较强翻译能力和泛化能力的大型语言模型。2) 翻译策略:采用合适的翻译策略,例如prompt engineering,以提高翻译质量。3) 微调参数设置:设置合适的学习率、batch size等超参数,以保证微调效果。4) 损失函数:使用交叉熵损失函数等常见的语言模型训练损失函数。
🖼️ 关键图片

📊 实验亮点
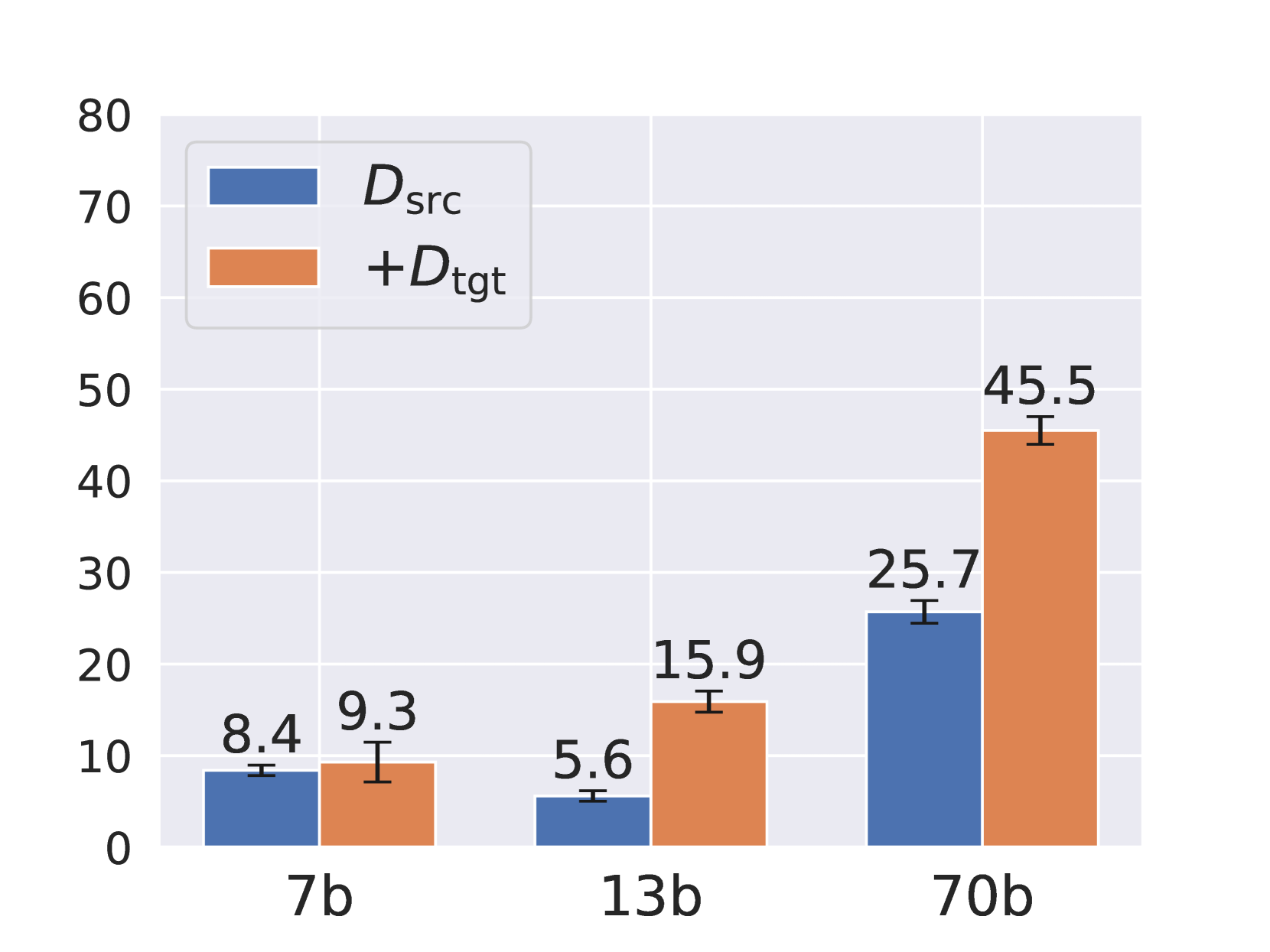
论文通过实验证明,Self-Translate-Train方法在跨语言迁移任务中优于零样本迁移。具体的性能提升幅度取决于具体的任务和数据集,但总体趋势表明,该方法能够有效提升LLM在目标语言上的性能。实验结果验证了利用LLM自身翻译能力进行自训练的有效性。
🎯 应用场景
该研究成果可应用于低资源语言的自然语言处理任务,例如机器翻译、文本分类、情感分析等。通过Self-Translate-Train方法,可以有效提升LLM在这些低资源语言上的性能,从而促进相关应用的发展。此外,该方法还可以应用于多语言知识迁移、跨语言信息检索等领域,具有广泛的应用前景。
📄 摘要(原文)
Zero-shot cross-lingual transfer by fine-tuning multilingual pretrained models shows promise for low-resource languages, but often suffers from misalignment of internal representations between languages. We hypothesize that even when the model cannot generalize across languages effectively in fine-tuning, it still captures cross-lingual correspondence useful for cross-lingual transfer. We explore this hypothesis with Self-Translate-Train, a method that lets large language models (LLMs) to translate training data into the target language and fine-tunes the model on its own generated data. By demonstrating that Self-Translate-Train outperforms zero-shot transfer, we encourage further exploration of better methods to elicit cross-lingual capabilities of LLMs.