Advancing Process Verification for Large Language Models via Tree-Based Preference Learning
作者: Mingqian He, Yongliang Shen, Wenqi Zhang, Zeqi Tan, Weiming Lu
分类: cs.CL
发布日期: 2024-06-29
💡 一句话要点
提出基于树搜索偏好学习的验证器Tree-PLV,提升LLM推理过程验证精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理验证 偏好学习 推理树 步骤级评估
📋 核心要点
- 现有LLM推理验证器依赖二元标签,无法充分利用中间步骤的相对优劣信息。
- 提出Tree-PLV,通过构建推理树并进行步骤级偏好学习,更精细地评估推理路径。
- 实验表明,Tree-PLV在多个推理任务上显著优于现有基线,提升了LLM的推理能力。
📝 摘要(中文)
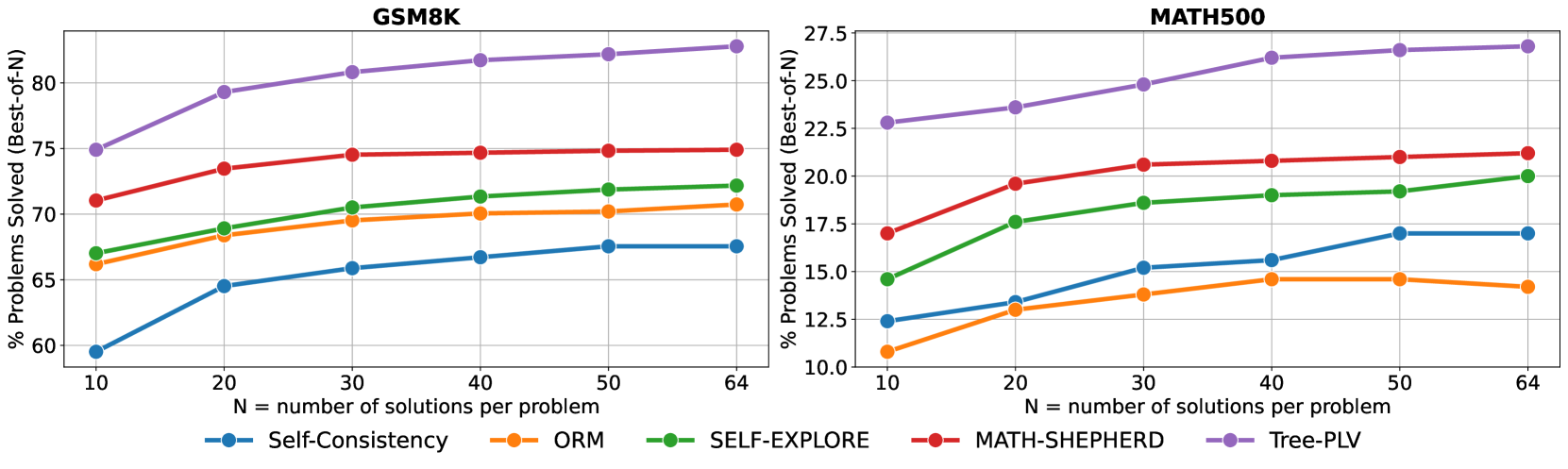
大型语言模型(LLMs)在处理复杂的推理任务时,通过生成逐步的推理过程展现了卓越的潜力。一些方法通过引入额外的验证器来评估这些推理路径,从而有效地提高了准确性。然而,现有的验证器通常在二元标记的推理路径上进行训练,未能充分利用中间步骤的相对优点,从而限制了所提供反馈的有效性。为了克服这一限制,我们提出了一种新的方法,即基于树的偏好学习验证器(Tree-PLV),该方法通过最佳优先搜索算法构建推理树,并收集步骤级别的配对数据用于偏好训练。与传统的二元分类相比,步骤级别的偏好更精细地捕捉了推理步骤之间的细微差别,从而可以更精确地评估完整的推理路径。我们在一系列算术和常识推理任务中对Tree-PLV进行了实证评估,结果表明它显著优于现有的基准。例如,在GSM8K(67.55%到82.79%)、MATH(17.00%到26.80%)、CSQA(68.14%到72.97%)和StrategyQA(82.86%到83.25%)上,Tree-PLV相对于Mistral-7B自洽性基线取得了显著的性能提升。此外,我们的研究还探讨了应用偏好学习的适当粒度,结果表明步骤级别的指导提供了与推理过程评估更一致的反馈。
🔬 方法详解
问题定义:现有的大语言模型推理验证方法,通常采用二元标签(正确/错误)来训练验证器,这种方式无法充分利用推理过程中各个步骤的细微差别和相对优劣。因此,验证器提供的反馈不够精确,限制了其提升LLM推理能力的效果。
核心思路:论文的核心思路是利用步骤级别的偏好学习,更精细地捕捉推理步骤之间的差异。通过构建推理树,并收集步骤级别的配对数据,训练验证器学习不同步骤之间的偏好关系,从而实现对完整推理路径的更精确评估。这种方法能够提供更细粒度的反馈,指导LLM进行更有效的推理。
技术框架:Tree-PLV的技术框架主要包含以下几个阶段:1) 推理树构建:使用最佳优先搜索算法,从初始问题出发,逐步生成推理步骤,构建推理树。2) 数据收集:在推理树的每个节点(推理步骤)上,收集步骤级别的配对数据,用于偏好训练。3) 偏好学习:使用收集到的配对数据,训练验证器学习不同步骤之间的偏好关系。4) 推理路径评估:使用训练好的验证器,评估完整的推理路径,并选择最优路径。
关键创新:最重要的技术创新点在于引入了步骤级别的偏好学习,取代了传统的二元分类。这种方法能够更精细地捕捉推理步骤之间的细微差别,从而实现对推理过程的更精确评估。与现有方法相比,Tree-PLV能够提供更细粒度的反馈,指导LLM进行更有效的推理。
关键设计:在推理树构建过程中,需要设计合适的搜索策略和停止条件,以保证推理树的质量和效率。在偏好学习过程中,需要选择合适的损失函数和网络结构,以有效地学习步骤之间的偏好关系。论文中具体使用的损失函数和网络结构未知。
🖼️ 关键图片


📊 实验亮点
Tree-PLV在多个推理任务上取得了显著的性能提升。在GSM8K数据集上,Tree-PLV将Mistral-7B自洽性基线的性能从67.55%提升到82.79%。在MATH数据集上,性能从17.00%提升到26.80%。在CSQA数据集上,性能从68.14%提升到72.97%。在StrategyQA数据集上,性能从82.86%提升到83.25%。这些结果表明,Tree-PLV能够有效地提高LLM的推理能力。
🎯 应用场景
该研究成果可应用于各种需要LLM进行复杂推理的场景,例如数学问题求解、常识推理、策略规划等。通过提高LLM推理过程的验证精度,可以提升LLM在这些场景下的性能和可靠性。未来,该方法有望被集成到LLM的训练和部署流程中,进一步提升LLM的智能化水平。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable potential in handling complex reasoning tasks by generating step-by-step rationales.Some methods have proven effective in boosting accuracy by introducing extra verifiers to assess these paths. However, existing verifiers, typically trained on binary-labeled reasoning paths, fail to fully utilize the relative merits of intermediate steps, thereby limiting the effectiveness of the feedback provided. To overcome this limitation, we propose Tree-based Preference Learning Verifier (Tree-PLV), a novel approach that constructs reasoning trees via a best-first search algorithm and collects step-level paired data for preference training. Compared to traditional binary classification, step-level preferences more finely capture the nuances between reasoning steps, allowing for a more precise evaluation of the complete reasoning path. We empirically evaluate Tree-PLV across a range of arithmetic and commonsense reasoning tasks, where it significantly outperforms existing benchmarks. For instance, Tree-PLV achieved substantial performance gains over the Mistral-7B self-consistency baseline on GSM8K (67.55% to 82.79%), MATH (17.00% to 26.80%), CSQA (68.14% to 72.97%), and StrategyQA (82.86% to 83.25%).Additionally, our study explores the appropriate granularity for applying preference learning, revealing that step-level guidance provides feedback that better aligns with the evaluation of the reasoning process.