ITERTL: An Iterative Framework for Fine-tuning LLMs for RTL Code Generation
作者: Peiyang Wu, Nan Guo, Xiao Xiao, Wenming Li, Xiaochun Ye, Dongrui Fan
分类: cs.CL, cs.AI
发布日期: 2024-06-28 (更新: 2025-04-23)
💡 一句话要点
ITERTL:一种迭代框架,用于微调LLM以生成RTL代码
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RTL代码生成 大型语言模型 迭代训练 微调 硬件设计
📋 核心要点
- 现有RTL代码生成方法依赖固定数据集微调LLM,数据需求量大且无法充分利用LLM的潜力。
- ITERTL采用迭代训练,利用模型自身生成的数据进行再训练,并结合数据过滤策略提升代码质量。
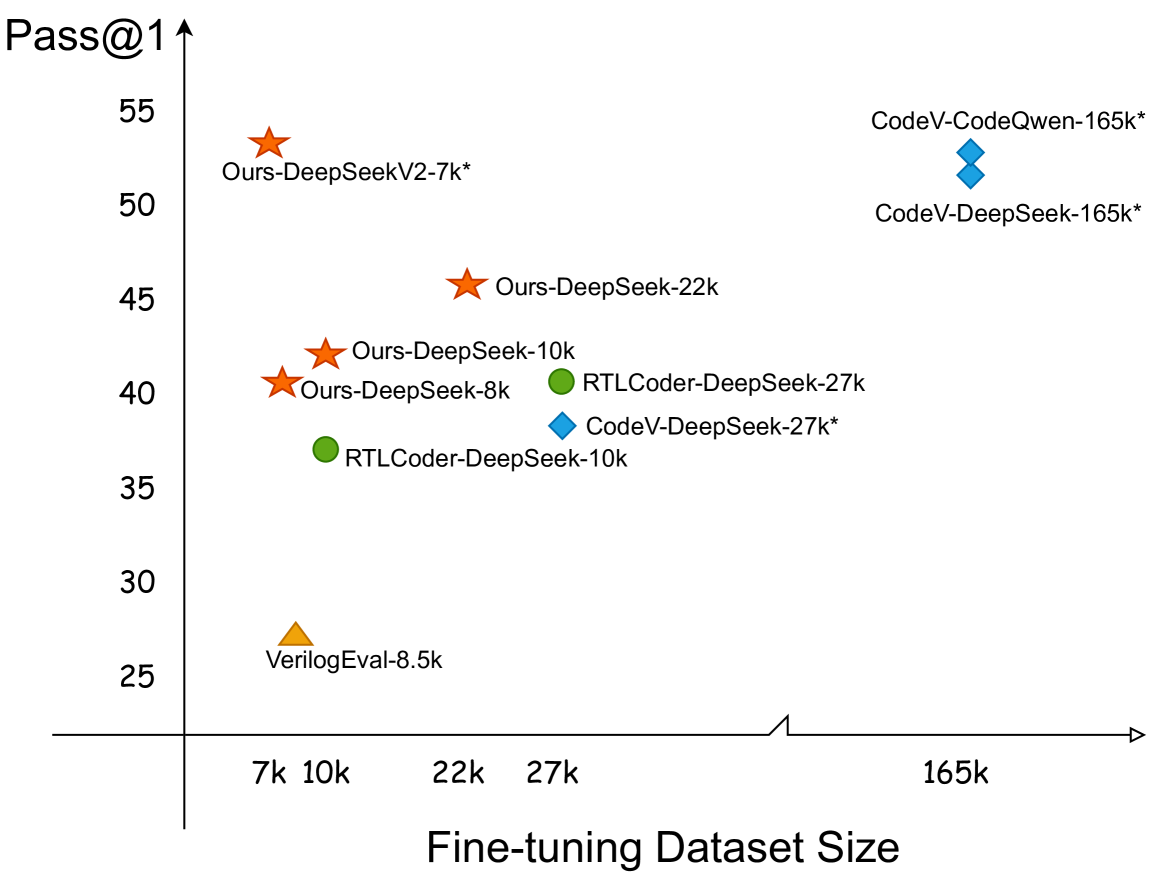
- 实验表明,ITERTL在VerilogEval-human基准测试中超越GPT4和SOTA模型,pass@1率达53.8%。
📝 摘要(中文)
本文提出了一种名为ITERTL的迭代训练范式,旨在提升大型语言模型(LLM)在寄存器传输级(RTL)代码生成方面的性能。现有方法通常在固定数据集上微调LLM,无法充分激发LLM的能力,且需要大量昂贵的参考数据。ITERTL通过迭代的方式,在每一轮迭代中,从前一轮训练的模型中抽取样本,并将其用于当前循环的训练。此外,还引入了一种即插即用的数据过滤策略,鼓励模型生成高质量、自包含的代码。实验结果表明,该模型优于GPT4和最先进的开源模型,在VerilogEval-human基准测试中达到了53.8%的pass@1率。在数据量和质量相似的条件下,该方法显著优于基线。
🔬 方法详解
问题定义:现有基于LLM的RTL代码生成方法主要面临两个痛点:一是需要大量高质量的RTL代码数据集进行微调,而这些数据的获取成本很高;二是传统的微调方法通常在固定数据集上进行,无法充分挖掘LLM的潜力,使其更好地适应RTL代码生成的任务。
核心思路:ITERTL的核心思路是通过迭代训练的方式,让LLM能够从自身生成的代码中学习,并不断提升代码生成的质量。每一轮迭代都利用上一轮模型生成的数据进行训练,相当于让模型在自我反馈中不断进化。同时,引入数据过滤策略,筛选出高质量的自包含代码,避免引入噪声数据。
技术框架:ITERTL的整体框架包含以下几个主要阶段:1) 初始模型训练:使用少量RTL代码数据集对LLM进行初步微调。2) 迭代训练循环:a) 使用当前模型生成RTL代码样本;b) 使用数据过滤策略筛选高质量样本;c) 使用筛选后的样本对模型进行微调。3) 迭代停止:当模型性能达到预设阈值或达到最大迭代次数时,停止迭代。
关键创新:ITERTL最重要的创新点在于其迭代训练范式。与传统的固定数据集微调方法不同,ITERTL能够利用模型自身生成的数据进行训练,从而更有效地利用LLM的潜力。此外,即插即用的数据过滤策略也是一个重要的创新,它可以有效地提高训练数据的质量,从而提升模型的性能。
关键设计:数据过滤策略是ITERTL的关键设计之一。该策略旨在筛选出高质量、自包含的RTL代码样本。具体的过滤规则可能包括:代码的语法正确性、代码的功能完整性、代码的复杂度等。此外,迭代次数和每一轮迭代中使用的数据量也是重要的参数,需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
ITERTL在VerilogEval-human基准测试中取得了显著的成果,pass@1率达到了53.8%,超越了GPT4和现有的SOTA开源模型。在数据量和质量相似的条件下,ITERTL的性能明显优于基线方法,验证了迭代训练范式和数据过滤策略的有效性。这些实验结果表明,ITERTL是一种有潜力提升LLM在RTL代码生成方面性能的方法。
🎯 应用场景
ITERTL具有广泛的应用前景,可用于自动化硬件设计流程,提高硬件工程师的开发效率。通过自动生成RTL代码,可以缩短设计周期,降低开发成本。此外,该方法还可以应用于硬件教学和研究,帮助学生和研究人员更好地理解和掌握RTL代码的生成和优化。
📄 摘要(原文)
Recently, large language models (LLMs) have demonstrated excellent performance, inspiring researchers to explore their use in automating register transfer level (RTL) code generation and improving hardware design efficiency. However, the existing approaches to fine-tune LLMs for RTL generation typically are conducted on fixed datasets, which do not fully stimulate the capability of LLMs and require large amounts of reference data, which are costly to acquire. To mitigate these issues, we innovatively introduce an iterative training paradigm named ITERTL. During each iteration, samples are drawn from the model trained in the previous cycle. Then these new samples are employed for training in current loop. Furthermore, we introduce a plug-and-play data filtering strategy, thereby encouraging the model to generate high-quality, self-contained code. Our model outperforms GPT4 and state-of-the-art (SOTA) open-source models, achieving remarkable 53.8% pass@1 rate on VerilogEval-human benchmark. Under similar conditions of data quantity and quality, our approach significantly outperforms the baseline. Extensive experiments validate the effectiveness of the proposed method.