The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models
作者: Xinyi Chen, Baohao Liao, Jirui Qi, Panagiotis Eustratiadis, Christof Monz, Arianna Bisazza, Maarten de Rijke
分类: cs.CL
发布日期: 2024-06-28 (更新: 2024-10-03)
备注: EMNLP 2024 Findings
DOI: 10.18653/v1/2024.findings-emnlp.92
💡 一句话要点
SIFo基准:评估大型语言模型在顺序指令遵循方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 基准测试 顺序指令 自然语言处理
📋 核心要点
- 现有方法在评估LLM的多指令遵循能力时,面临指令连贯性差、位置偏差和缺乏客观验证等挑战。
- 论文提出SIFo基准,通过设计可由最终指令验证的任务,来评估LLM的顺序指令遵循能力。
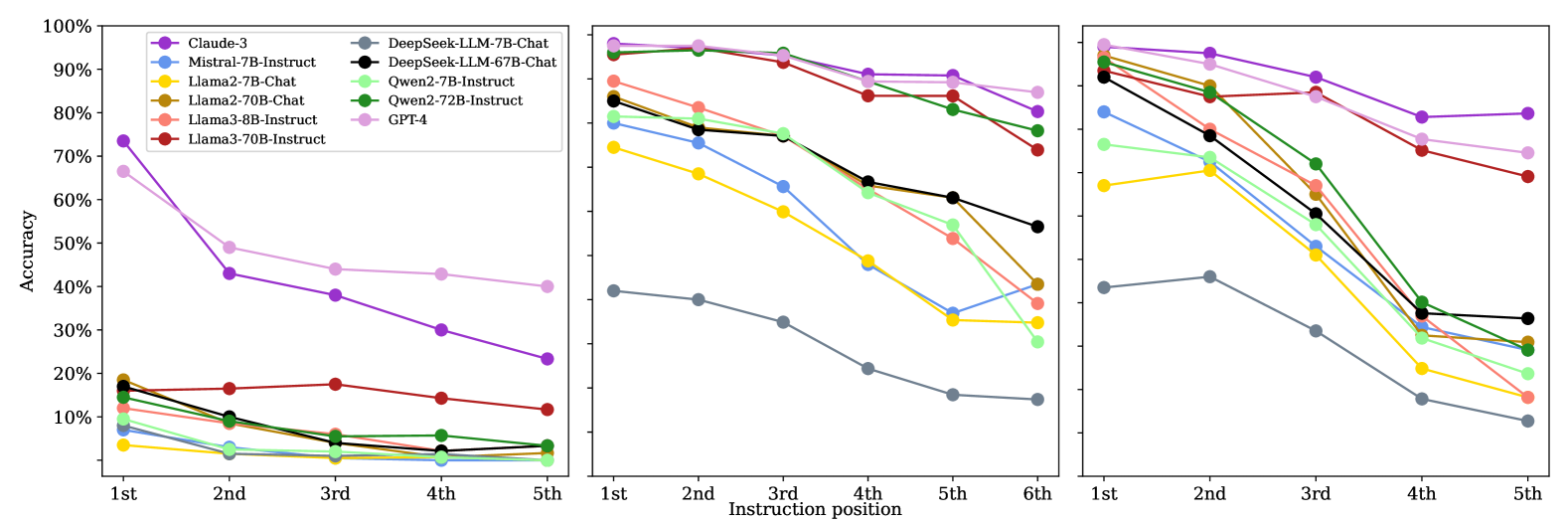
- 实验结果表明,规模更大、更新的模型在SIFo基准上表现更好,但所有模型在长序列指令上均表现不佳。
📝 摘要(中文)
遵循多重指令是大型语言模型(LLMs)的一项关键能力。评估这种能力面临着重大挑战:(i)多重指令之间的连贯性有限,(ii)位置偏差,即指令的顺序影响模型性能,以及(iii)缺乏客观可验证的任务。为了解决这些问题,我们引入了一个基准,旨在通过顺序指令遵循(SIFo)任务来评估模型遵循多重指令的能力。在SIFo中,只需检查最终指令即可验证多重指令的成功完成。我们的基准使用四个任务(文本修改、问题回答、数学和安全规则)评估指令遵循,每个任务评估顺序指令遵循的不同方面。我们对流行的LLM(包括闭源和开源)的评估表明,更新和更大的模型在SIFo任务上的表现明显优于旧的和更小的模型,验证了基准的有效性。所有模型都在遵循指令序列方面存在困难,这暗示了当今语言模型缺乏重要的鲁棒性。
🔬 方法详解
问题定义:现有方法在评估大型语言模型的多指令遵循能力时存在诸多痛点。首先,多个指令之间可能缺乏内在的逻辑联系,导致模型难以理解指令的整体意图。其次,指令的顺序可能会对模型产生影响,即位置偏差,使得模型对不同顺序的相同指令产生不同的结果。最后,缺乏客观可验证的任务,难以准确评估模型是否真正理解并执行了所有指令。
核心思路:论文的核心思路是设计一种顺序指令遵循(SIFo)任务,其中每个指令都依赖于前一个指令的结果,并且最终指令的执行结果能够客观地验证整个指令序列是否被正确执行。通过这种方式,可以有效地解决现有方法中存在的连贯性、位置偏差和可验证性问题。
技术框架:SIFo基准包含四个任务:文本修改、问题回答、数学和安全规则。每个任务都设计成一系列顺序指令,模型需要按照指令的顺序逐步执行。最终的输出结果会被用来验证模型是否正确地遵循了整个指令序列。基准的设计允许研究者评估模型在不同类型的任务中遵循顺序指令的能力。
关键创新:SIFo基准的关键创新在于其可验证性。通过设计特定的任务,使得最终指令的执行结果能够直接反映模型是否正确地遵循了整个指令序列。这种设计避免了主观评价,并提供了一种客观的评估方法。此外,SIFo基准还考虑了不同类型的任务,从而更全面地评估模型的顺序指令遵循能力。
关键设计:SIFo基准的关键设计在于指令序列的构建。每个指令序列都经过精心设计,以确保指令之间的依赖关系清晰明确,并且最终指令的执行结果能够准确地反映模型是否正确地遵循了整个序列。此外,基准还包含了不同难度的指令序列,以评估模型在不同复杂程度下的表现。具体的参数设置、损失函数和网络结构等技术细节取决于被评估的LLM,SIFo基准本身不限定这些细节。
🖼️ 关键图片


📊 实验亮点
实验结果表明,规模更大、更新的LLM在SIFo基准上表现显著优于规模较小、较旧的模型,验证了基准的有效性。然而,所有模型在处理长序列指令时都表现出明显的困难,这表明当前LLM在鲁棒性方面仍有很大的提升空间。具体性能数据未在摘要中给出,需要查阅原文。
🎯 应用场景
该研究成果可应用于提升智能助手、自动化流程和机器人控制等领域中,大型语言模型理解和执行复杂指令的能力。通过SIFo基准的评估和优化,可以显著提高LLM在实际应用中的可靠性和效率,从而更好地服务于人类生活和工作。
📄 摘要(原文)
Following multiple instructions is a crucial ability for large language models (LLMs). Evaluating this ability comes with significant challenges: (i) limited coherence between multiple instructions, (ii) positional bias where the order of instructions affects model performance, and (iii) a lack of objectively verifiable tasks. To address these issues, we introduce a benchmark designed to evaluate models' abilities to follow multiple instructions through sequential instruction following (SIFo) tasks. In SIFo, the successful completion of multiple instructions is verifiable by examining only the final instruction. Our benchmark evaluates instruction following using four tasks (text modification, question answering, mathematics, and security rules), each assessing different aspects of sequential instruction following. Our evaluation of popular LLMs, both closed-source and open-source, shows that more recent and larger models significantly outperform their older and smaller counterparts on the SIFo tasks, validating the benchmark's effectiveness. All models struggle with following sequences of instructions, hinting at an important lack of robustness of today's language models.