Single Parent Family: A Spectrum of Family Members from a Single Pre-Trained Foundation Model
作者: Habib Hajimolahoseini, Mohammad Hassanpour, Foozhan Ataiefard, Boxing Chen, Yang Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-06-28
💡 一句话要点
提出渐进式低秩分解(PLRD)方法,高效压缩并生成多种尺寸的大语言模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 低秩分解 模型优化 预训练模型 资源受限设备
📋 核心要点
- 现有大语言模型计算开销大、能耗高,难以在资源受限的平台上部署。
- 提出渐进式低秩分解(PLRD)方法,通过逐步降低模型张量的秩来实现压缩和加速。
- 实验表明,PLRD方法在显著降低计算资源需求的同时,保持了与传统训练模型相当的性能。
📝 摘要(中文)
本文提出了一种新颖的渐进式低秩分解(PLRD)方法,专门用于压缩大型语言模型。该方法利用预训练模型,然后使用逐渐降低的秩将其增量解压缩到更小的尺寸。这种方法显著降低了计算开销和能源消耗,因为后续模型是从原始模型派生而来,而无需从头开始重新训练。我们详细介绍了PLRD的实现,它策略性地降低了张量的秩,从而优化了模型性能和资源使用之间的权衡。通过大量的实验证明了PLRD的有效性,结果表明,使用PLRD方法仅在1B tokens上训练的模型,在使用0.1%的tokens的情况下,仍能保持与传统训练模型相当的性能。PLRD的多功能性体现在它能够从单个基础模型生成多种模型尺寸,从而灵活地适应不同的计算和内存预算。我们的研究结果表明,PLRD可以为LLM的有效扩展设定新的标准,使先进的AI在各种平台上更具可行性。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在部署时面临着巨大的计算资源和能源消耗挑战。传统的模型压缩方法,如知识蒸馏或剪枝,通常需要大量的重新训练,成本高昂。因此,如何高效地压缩LLM,使其能够在资源受限的设备上运行,同时保持其性能,是一个亟待解决的问题。
核心思路:本文的核心思路是利用预训练模型的信息,通过渐进式地降低模型的秩来进行压缩。这种方法避免了从头开始训练小模型的需要,从而大大降低了计算成本。通过逐步降低张量的秩,可以在模型大小、计算复杂度和性能之间找到一个最佳的平衡点。
技术框架:PLRD方法主要包含以下几个阶段:1) 选择一个预训练的大型语言模型作为基础模型。2) 对基础模型的权重矩阵进行低秩分解。3) 逐步降低低秩分解的秩,生成一系列不同大小的模型。4) 对生成的模型进行微调,以进一步提高性能。整个过程无需从头训练,而是基于预训练模型进行逐步压缩和优化。
关键创新:PLRD的关键创新在于其渐进式的低秩分解方法。与传统的低秩分解方法不同,PLRD不是一次性地将模型分解到目标大小,而是逐步地降低秩,从而更好地控制压缩过程中的信息损失。此外,PLRD能够从单个预训练模型生成多个不同大小的模型,从而灵活地适应不同的计算和内存预算。
关键设计:PLRD的关键设计包括:1) 低秩分解的具体实现方式,例如使用奇异值分解(SVD)。2) 秩降低的策略,例如线性降低或指数降低。3) 微调的策略,例如使用少量数据进行微调,或者使用知识蒸馏的方法进行微调。4) 损失函数的设计,例如使用交叉熵损失函数或对比损失函数。
🖼️ 关键图片

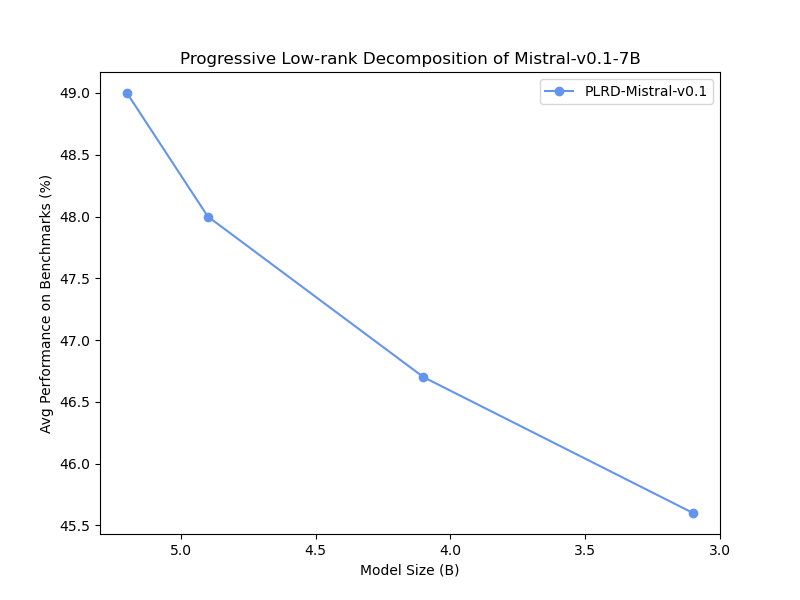
📊 实验亮点
实验结果表明,使用PLRD方法在仅1B tokens上训练的模型,在使用0.1%的tokens的情况下,仍能保持与传统训练模型相当的性能。这表明PLRD方法能够有效地压缩大型语言模型,并在显著降低计算资源需求的同时,保持模型的性能。
🎯 应用场景
PLRD方法可应用于各种需要高效部署大型语言模型的场景,如移动设备、边缘计算设备和嵌入式系统。该方法能够降低模型的计算复杂度和内存占用,使其能够在资源受限的平台上运行。此外,PLRD还可以用于生成多个不同大小的模型,以适应不同的应用需求。
📄 摘要(原文)
This paper introduces a novel method of Progressive Low Rank Decomposition (PLRD) tailored for the compression of large language models. Our approach leverages a pre-trained model, which is then incrementally decompressed to smaller sizes using progressively lower ranks. This method allows for significant reductions in computational overhead and energy consumption, as subsequent models are derived from the original without the need for retraining from scratch. We detail the implementation of PLRD, which strategically decreases the tensor ranks, thus optimizing the trade-off between model performance and resource usage. The efficacy of PLRD is demonstrated through extensive experiments showing that models trained with PLRD method on only 1B tokens maintain comparable performance with traditionally trained models while using 0.1% of the tokens. The versatility of PLRD is highlighted by its ability to generate multiple model sizes from a single foundational model, adapting fluidly to varying computational and memory budgets. Our findings suggest that PLRD could set a new standard for the efficient scaling of LLMs, making advanced AI more feasible on diverse platforms.