Mixture of In-Context Experts Enhance LLMs' Long Context Awareness
作者: Hongzhan Lin, Ang Lv, Yuhan Chen, Chen Zhu, Yang Song, Hengshu Zhu, Rui Yan
分类: cs.CL
发布日期: 2024-06-28 (更新: 2024-10-17)
备注: Accepted by Neurips2024
💡 一句话要点
提出MoICE,增强LLM在长文本中对不同位置信息的感知能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 上下文感知 大型语言模型 位置编码 RoPE 注意力机制 路由器 MoICE
📋 核心要点
- LLM在长文本处理中存在对不同位置上下文感知不均衡的问题,容易忽略关键信息。
- MoICE将RoPE角度视为上下文专家,通过路由器动态选择,使注意力头关注所需位置。
- MoICE采用仅路由器训练策略,冻结LLM参数,快速更新路由器,提升效率和性能。
📝 摘要(中文)
许多研究表明,大型语言模型(LLM)对不同上下文位置的感知能力不均衡。这种有限的上下文感知可能导致忽略关键信息,进而导致任务失败。虽然已经提出了几种增强LLM上下文感知能力的方法,但同时实现有效性和效率仍然具有挑战性。本文针对使用RoPE作为位置嵌入的LLM,提出了一种名为“上下文专家混合”(MoICE)的新方法来应对这一挑战。MoICE包含两个关键组件:集成到LLM每个注意力头中的路由器,以及轻量级的仅路由器训练优化策略:(1)MoICE将每个RoPE角度视为一个“上下文”专家,证明其能够引导注意力头的注意力到特定的上下文位置。因此,每个注意力头使用由路由器动态选择的多个RoPE角度灵活地处理token,以关注所需的token位置。这种方法降低了忽略重要上下文信息的风险。(2)仅路由器训练策略包括冻结LLM参数,并仅更新路由器几个步骤。当应用于包括Llama和Mistral在内的开源LLM时,MoICE在长文本理解和生成方面的多个任务中超越了先前的方法,同时保持了值得称赞的推理效率。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,对不同位置的上下文信息的感知能力存在差异,即并非所有位置的信息都能被平等地关注。这种不均衡的感知能力会导致模型忽略关键信息,从而影响其在长文本理解和生成任务中的表现。现有方法在提升长文本感知能力时,往往难以兼顾有效性和效率,需要大量的计算资源和训练时间。
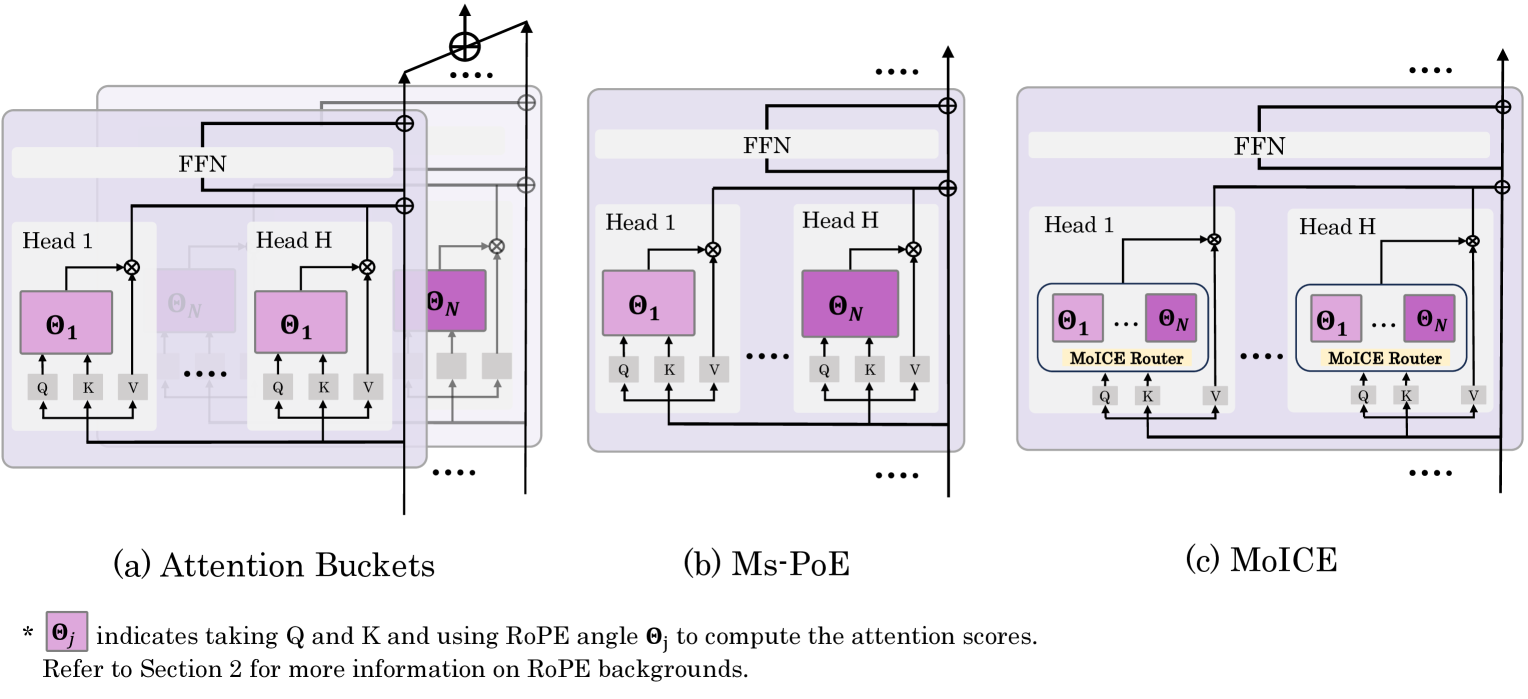
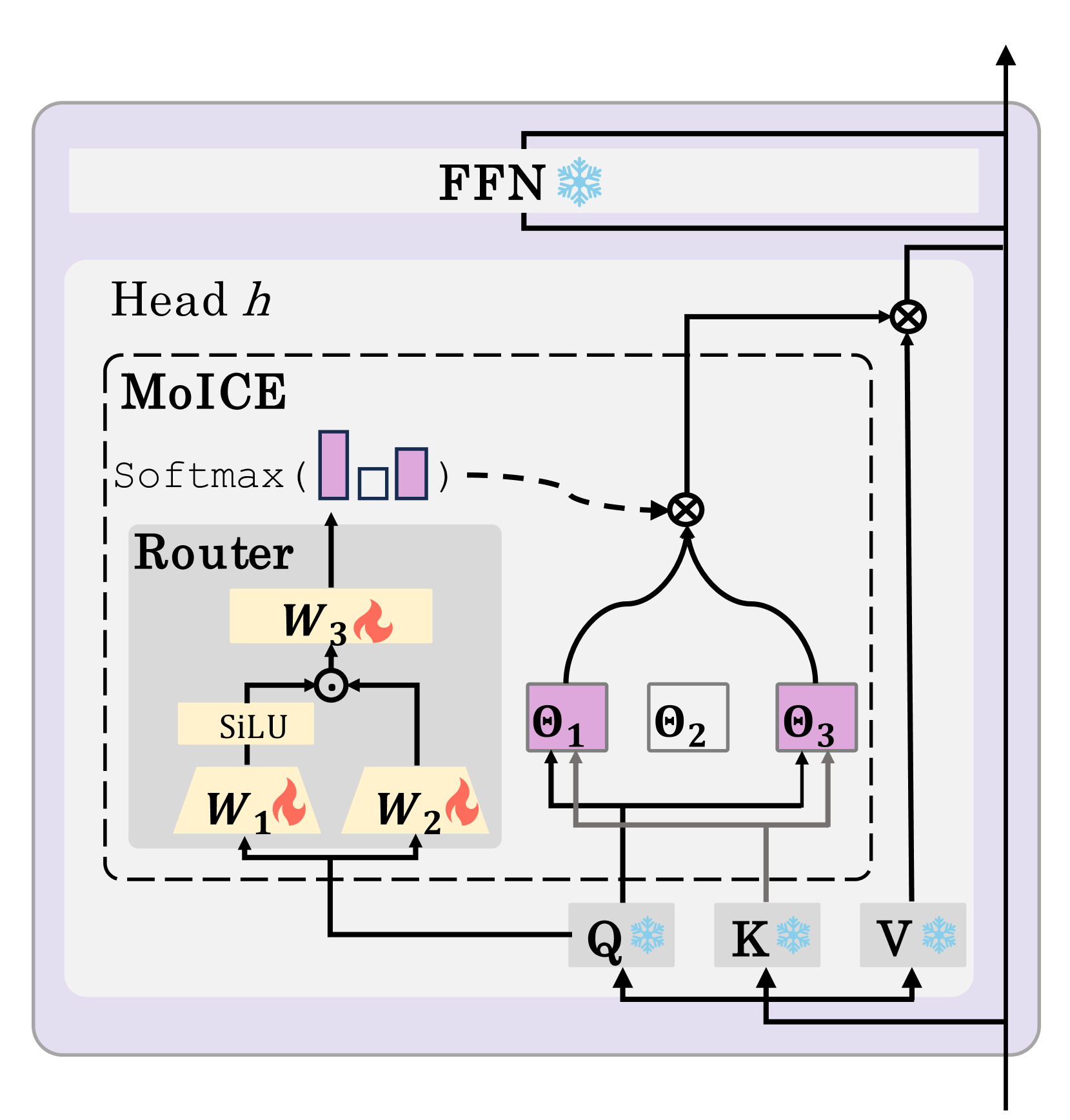
核心思路:MoICE的核心思路是将RoPE(Rotary Position Embedding)中的每个角度视为一个“上下文专家”,每个专家负责关注文本中的特定位置。通过一个路由器动态地选择合适的专家组合,让注意力头能够灵活地关注到文本中最重要的位置信息。这种方法旨在模拟人类阅读长文本时,会根据上下文动态调整关注点的行为。
技术框架:MoICE主要包含两个核心组件:一是集成在LLM每个注意力头中的路由器,二是轻量级的仅路由器训练优化策略。路由器负责根据输入token的上下文信息,动态地选择合适的RoPE角度(即上下文专家)组合。仅路由器训练策略则是在训练过程中冻结LLM的主体参数,只更新路由器的参数,从而大大降低了训练成本。整体流程是,输入文本经过LLM的embedding层后,进入Transformer层,在每个注意力头中,路由器根据当前token的表示选择RoPE角度,然后注意力头利用这些角度计算注意力权重,最终输出结果。
关键创新:MoICE最重要的技术创新点在于将RoPE角度视为上下文专家,并使用路由器动态选择专家组合。与现有方法相比,MoICE不需要修改LLM的主体结构,而是通过一个轻量级的路由器来增强其长文本感知能力。这种方法不仅提高了模型的性能,还降低了训练成本。
关键设计:MoICE的关键设计包括路由器的结构和仅路由器训练策略。路由器通常是一个小型神经网络,输入是当前token的表示,输出是每个RoPE角度的权重。仅路由器训练策略通过冻结LLM主体参数,只更新路由器参数,大大降低了训练成本。损失函数的设计目标是使路由器能够选择到对当前任务最有帮助的RoPE角度组合。具体参数设置和网络结构的选择可能因不同的LLM而异,但核心思想是保持路由器的轻量化和高效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MoICE在Llama和Mistral等开源LLM上取得了显著的性能提升。在长文本理解和生成任务中,MoICE超越了现有的其他方法,同时保持了较高的推理效率。例如,在某些长文本问答任务中,MoICE的准确率提升了超过5%。这些结果证明了MoICE在增强LLM长文本感知能力方面的有效性。
🎯 应用场景
MoICE具有广泛的应用前景,可应用于长文档摘要、长文本问答、代码生成、故事创作等需要处理长序列信息的任务。通过增强LLM对长文本的理解能力,MoICE可以提升这些应用场景下的性能和用户体验。未来,MoICE还可以与其他技术结合,例如知识图谱、检索增强等,进一步提升LLM在复杂任务中的表现。
📄 摘要(原文)
Many studies have revealed that large language models (LLMs) exhibit uneven awareness of different contextual positions. Their limited context awareness can lead to overlooking critical information and subsequent task failures. While several approaches have been proposed to enhance LLMs' context awareness, achieving both effectiveness and efficiency remains challenging. In this paper, for LLMs utilizing RoPE as position embeddings, we introduce a novel method called "Mixture of In-Context Experts" (MoICE) to address this challenge. MoICE comprises two key components: a router integrated into each attention head within LLMs and a lightweight router-only training optimization strategy: (1) MoICE views each RoPE angle as an `in-context' expert, demonstrated to be capable of directing the attention of a head to specific contextual positions. Consequently, each attention head flexibly processes tokens using multiple RoPE angles dynamically selected by the router to attend to the needed positions. This approach mitigates the risk of overlooking essential contextual information. (2) The router-only training strategy entails freezing LLM parameters and exclusively updating routers for only a few steps. When applied to open-source LLMs including Llama and Mistral, MoICE surpasses prior methods across multiple tasks on long context understanding and generation, all while maintaining commendable inference efficiency.