DIM: Dynamic Integration of Multimodal Entity Linking with Large Language Model
作者: Shezheng Song, Shasha Li, Jie Yu, Shan Zhao, Xiaopeng Li, Jun Ma, Xiaodong Liu, Zhuo Li, Xiaoguang Mao
分类: cs.CL, cs.AI
发布日期: 2024-06-27
备注: Published on PRCV24
🔗 代码/项目: GITHUB
💡 一句话要点
提出DIM方法,利用大语言模型动态融合多模态信息,提升实体链接性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态实体链接 大语言模型 知识库 视觉理解 ChatGPT BLIP-2 动态实体提取
📋 核心要点
- 现有方法在多模态实体链接中存在实体表示模糊和图像信息利用不充分的问题,限制了性能。
- DIM方法利用ChatGPT动态提取实体并增强数据集,同时利用大语言模型进行视觉理解,提取图像中与实体相关的信息。
- 实验结果表明,DIM方法在原始数据集上优于现有方法,并在动态增强数据集上取得了SOTA性能。
📝 摘要(中文)
本研究深入探讨了多模态实体链接问题,旨在将多模态信息中的提及项与知识库中的实体对齐。现有方法面临实体表示模糊和图像信息利用不足等挑战。因此,我们提出了一种使用ChatGPT的动态实体提取方法,该方法能够动态提取实体并增强数据集。此外,我们还提出了一种名为“动态融合多模态信息与知识库”(DIM)的方法,利用大语言模型(LLM)的视觉理解能力。像BLIP-2这样的LLM可以提取图像中与实体相关的信息,从而有助于改进实体特征的提取,并将它们与ChatGPT提供的动态实体表示链接起来。实验表明,我们提出的DIM方法在三个原始数据集上优于大多数现有方法,并在动态增强数据集(Wiki+、Rich+、Diverse+)上实现了最先进(SOTA)的性能。为了保证可重复性,我们的代码和收集的数据集已在https://github.com/season1blue/DIM上发布。
🔬 方法详解
问题定义:论文旨在解决多模态实体链接任务中,现有方法对实体表示不够清晰,以及对图像信息利用不足的问题。现有方法难以有效提取图像中与实体相关的信息,导致链接准确率不高。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大能力,一方面使用ChatGPT动态提取和增强实体表示,另一方面使用LLM(如BLIP-2)进行视觉理解,提取图像中与实体相关的信息,并将两者融合,从而提升实体链接的准确性。
技术框架:DIM方法主要包含两个核心模块:1) 动态实体提取模块,使用ChatGPT动态生成和增强实体表示;2) 多模态信息融合模块,利用LLM提取图像中的实体相关信息,并将视觉信息与动态实体表示进行融合。整个流程包括:输入多模态数据(文本提及和图像),ChatGPT生成候选实体及其描述,LLM提取图像特征,最后将文本和图像特征融合,进行实体链接。
关键创新:论文的关键创新在于动态地利用大语言模型来增强实体表示和提取图像信息。与传统方法相比,DIM方法能够更有效地利用图像信息,并生成更具区分性的实体表示。此外,动态实体提取模块能够根据不同的上下文生成不同的实体表示,从而更好地处理实体歧义问题。
关键设计:在动态实体提取模块中,使用了ChatGPT进行实体描述的生成和增强。在多模态信息融合模块中,使用了BLIP-2等LLM来提取图像特征。损失函数方面,可能采用了交叉熵损失或对比学习损失来优化实体链接的性能。具体的网络结构细节和参数设置在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

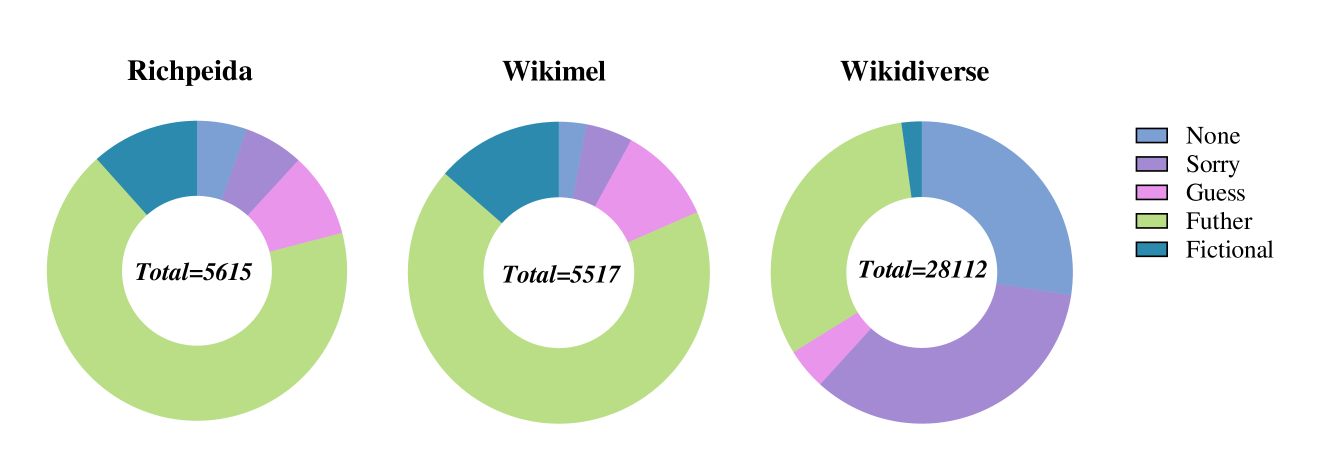
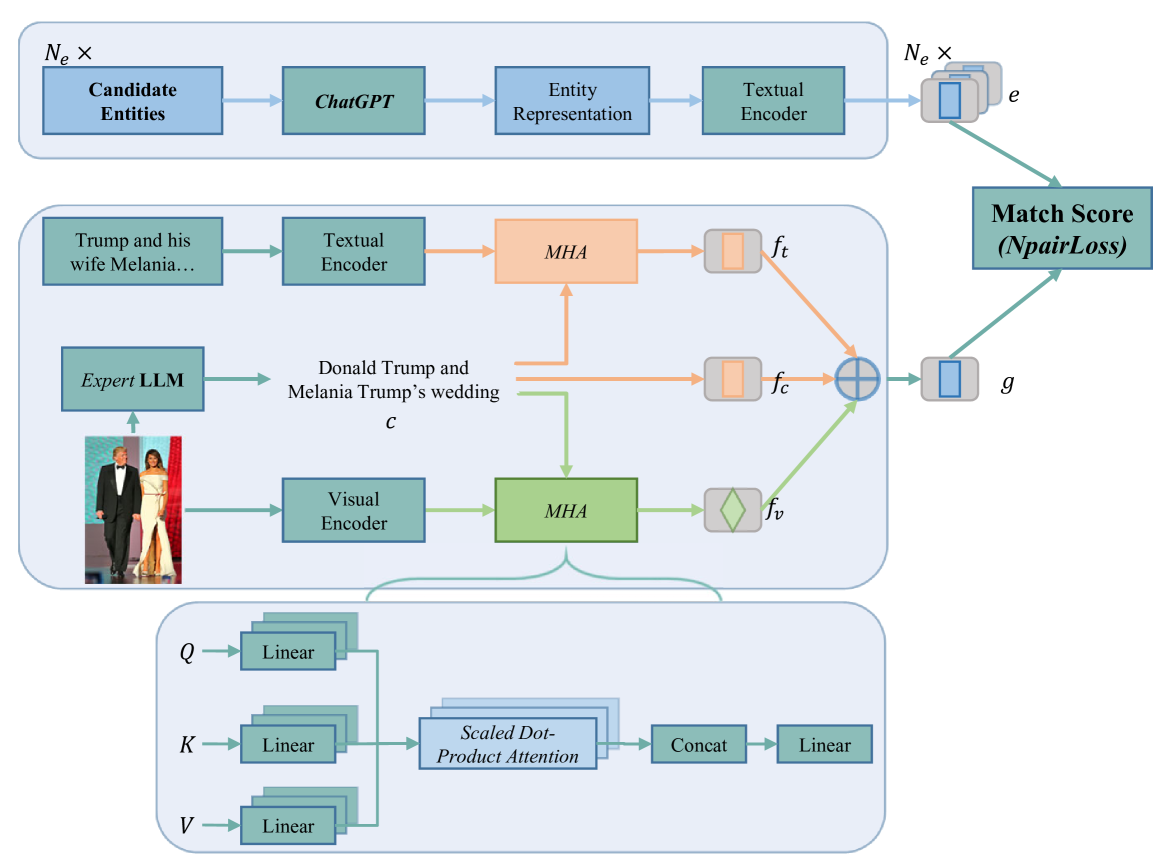
📊 实验亮点
DIM方法在三个原始数据集上优于大多数现有方法,并在动态增强数据集(Wiki+、Rich+、Diverse+)上实现了SOTA性能。这表明DIM方法能够有效利用大语言模型的能力,提升多模态实体链接的准确性。具体的性能提升幅度需要参考论文中的实验数据(未知)。
🎯 应用场景
该研究成果可应用于智能问答系统、知识图谱构建、多模态信息检索等领域。通过更准确地链接多模态信息中的实体,可以提升这些应用的用户体验和性能。例如,在智能客服中,可以更准确地理解用户通过文本和图像表达的需求,从而提供更精准的答案。
📄 摘要(原文)
Our study delves into Multimodal Entity Linking, aligning the mention in multimodal information with entities in knowledge base. Existing methods are still facing challenges like ambiguous entity representations and limited image information utilization. Thus, we propose dynamic entity extraction using ChatGPT, which dynamically extracts entities and enhances datasets. We also propose a method: Dynamically Integrate Multimodal information with knowledge base (DIM), employing the capability of the Large Language Model (LLM) for visual understanding. The LLM, such as BLIP-2, extracts information relevant to entities in the image, which can facilitate improved extraction of entity features and linking them with the dynamic entity representations provided by ChatGPT. The experiments demonstrate that our proposed DIM method outperforms the majority of existing methods on the three original datasets, and achieves state-of-the-art (SOTA) on the dynamically enhanced datasets (Wiki+, Rich+, Diverse+). For reproducibility, our code and collected datasets are released on \url{https://github.com/season1blue/DIM}.