Can Large Language Models Generate High-quality Patent Claims?
作者: Lekang Jiang, Caiqi Zhang, Pascal A Scherz, Stephan Goetz
分类: cs.CL
发布日期: 2024-06-27 (更新: 2025-05-25)
备注: Accepted to NAACL 2025. 16 pages, 2 figures, 12 tables
期刊: Findings of the Association for Computational Linguistics: NAACL 2025, pages 1272-1287
💡 一句话要点
探索大语言模型在专利权利要求生成中的能力,并分析其优劣势
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 专利权利要求生成 自然语言处理 文本生成 专利领域 GPT-4 微调 人工评估
📋 核心要点
- 现有方法在专利权利要求生成方面存在不足,尤其是在处理专利领域高度结构化和精确的语言时。
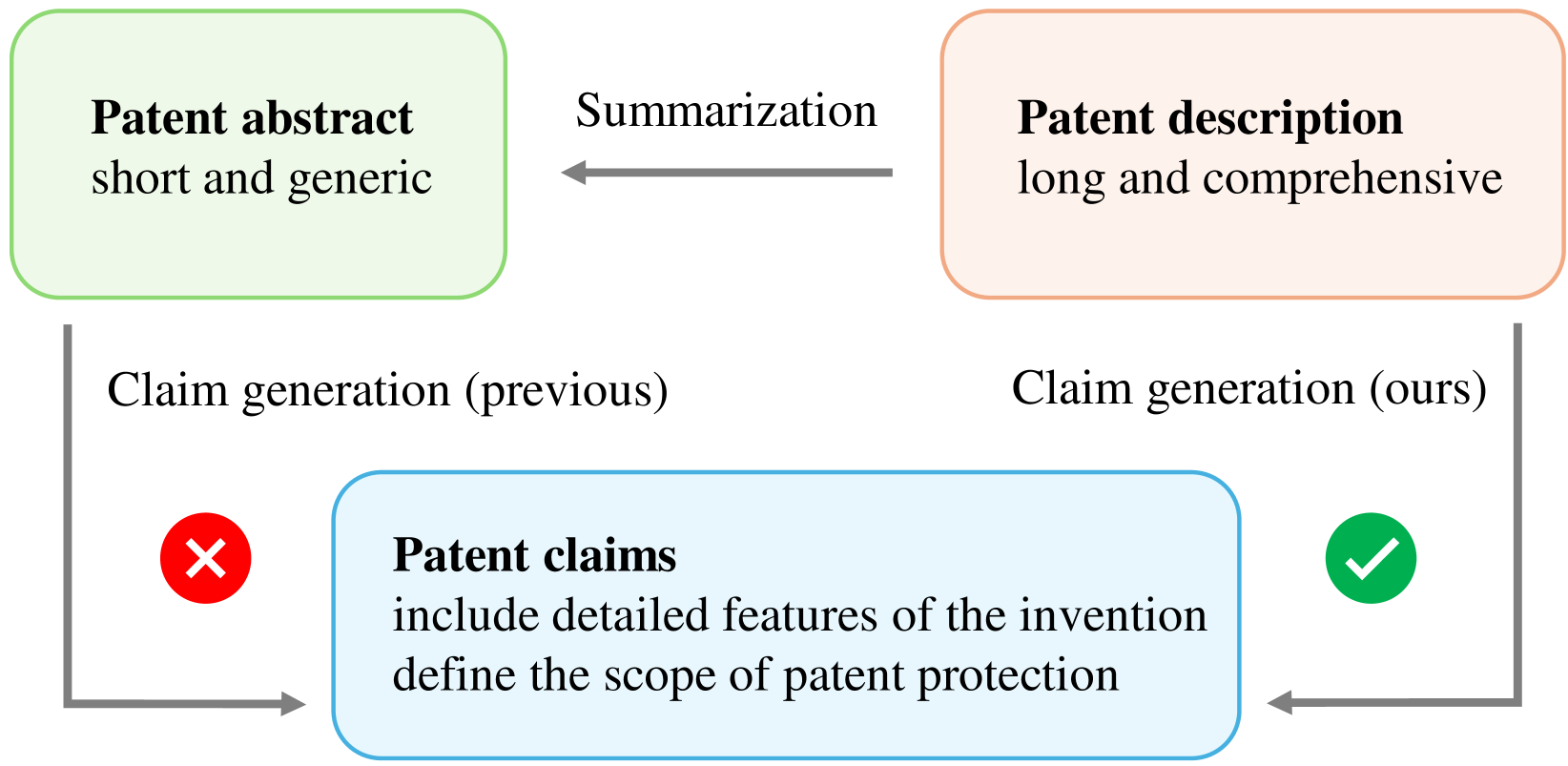
- 该研究探索了利用大型语言模型直接基于专利描述生成权利要求,而非以往常用的摘要。
- 实验结果表明,通用LLM优于特定领域的LLM,GPT-4在特征覆盖、概念清晰和技术连贯性方面表现最佳。
📝 摘要(中文)
大型语言模型(LLMs)在各种文本生成任务中表现出卓越的性能,但在专利领域的研究仍然不足,而专利领域提供了高度结构化和精确的语言。本文构建了一个数据集,以研究当前LLMs在专利权利要求生成中的性能。结果表明,基于专利描述生成权利要求优于以往基于摘要的研究。有趣的是,目前特定于专利的LLMs的性能远不如最先进的通用LLMs,突出了未来研究领域内LLMs的必要性。我们还发现,LLMs可以生成高质量的首次独立权利要求,但其在后续从属权利要求方面的性能明显下降。此外,微调可以提高发明特征的完整性、概念清晰度和特征联系。在测试的LLMs中,GPT-4在专利专家的全面人工评估中表现出最佳性能,具有更好的特征覆盖率、概念清晰度和技术连贯性。尽管具有这些能力,但仍需要进行全面的修订和修改,才能通过严格的专利审查并确保法律上的稳健性。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLMs)在生成高质量专利权利要求方面的能力。现有方法主要依赖于专利摘要进行生成,这可能丢失关键的技术细节,导致生成的权利要求质量不高。此外,针对专利领域的特定LLM发展不足,通用LLM在专利领域的应用潜力尚未充分挖掘。
核心思路:论文的核心思路是直接利用完整的专利描述作为LLM的输入,生成专利权利要求。这种方法旨在克服摘要信息丢失的问题,使LLM能够更好地理解发明的技术细节和范围。同时,论文对比了通用LLM和专利领域特定LLM的性能,并探索了微调对生成质量的影响。
技术框架:该研究主要包括以下几个阶段:1) 构建专利权利要求生成数据集,该数据集包含专利描述和对应的权利要求;2) 使用不同的LLM(包括通用LLM和专利领域特定LLM)生成权利要求;3) 对生成的权利要求进行人工评估,评估指标包括特征覆盖率、概念清晰度和技术连贯性;4) 通过微调LLM,提高其在专利权利要求生成方面的性能。
关键创新:该研究的关键创新在于:1) 首次系统性地评估了通用LLM在专利权利要求生成方面的能力;2) 提出了基于专利描述而非摘要的权利要求生成方法,提高了生成质量;3) 揭示了通用LLM在专利领域优于特定领域LLM的现象,为未来的研究方向提供了启示。
关键设计:论文的关键设计包括:1) 构建了包含独立权利要求和从属权利要求的数据集,用于全面评估LLM的生成能力;2) 采用了人工评估的方式,由专利专家对生成的权利要求进行评估,保证了评估的客观性和准确性;3) 通过微调LLM,探索了提高生成质量的有效方法,并分析了微调对不同评估指标的影响。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于专利描述生成权利要求优于基于摘要的方法。通用LLM(特别是GPT-4)在特征覆盖率、概念清晰度和技术连贯性方面表现优于专利领域特定LLM。微调可以显著提高LLM生成权利要求的完整性和清晰度。GPT-4在人工评估中表现最佳,但仍需人工修改以确保法律上的稳健性。
🎯 应用场景
该研究成果可应用于专利撰写辅助工具的开发,帮助专利工程师更高效地撰写高质量的专利权利要求。通过利用LLM自动生成初步的权利要求草案,可以显著减少人工撰写的时间和成本,并提高专利申请的成功率。此外,该研究也为未来开发更强大的专利领域专用LLM提供了指导。
📄 摘要(原文)
Large language models (LLMs) have shown exceptional performance across various text generation tasks but remain under-explored in the patent domain, which offers highly structured and precise language. This paper constructs a dataset to investigate the performance of current LLMs in patent claim generation. Our results demonstrate that generating claims based on patent descriptions outperforms previous research relying on abstracts. Interestingly, current patent-specific LLMs perform much worse than state-of-the-art general LLMs, highlighting the necessity for future research on in-domain LLMs. We also find that LLMs can produce high-quality first independent claims, but their performances markedly decrease for subsequent dependent claims. Moreover, fine-tuning can enhance the completeness of inventions' features, conceptual clarity, and feature linkage. Among the tested LLMs, GPT-4 demonstrates the best performance in comprehensive human evaluations by patent experts, with better feature coverage, conceptual clarity, and technical coherence. Despite these capabilities, comprehensive revision and modification are still necessary to pass rigorous patent scrutiny and ensure legal robustness.