Suri: Multi-constraint Instruction Following for Long-form Text Generation
作者: Chau Minh Pham, Simeng Sun, Mohit Iyyer
分类: cs.CL
发布日期: 2024-06-27 (更新: 2024-10-02)
备注: Accepted to EMNLP'24 (Findings)
🔗 代码/项目: GITHUB
💡 一句话要点
Suri:面向长文本生成的多约束指令跟随数据集与I-ORPO对齐方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 指令跟随 多约束 偏好学习 ORPO 数据增强 大型语言模型
📋 核心要点
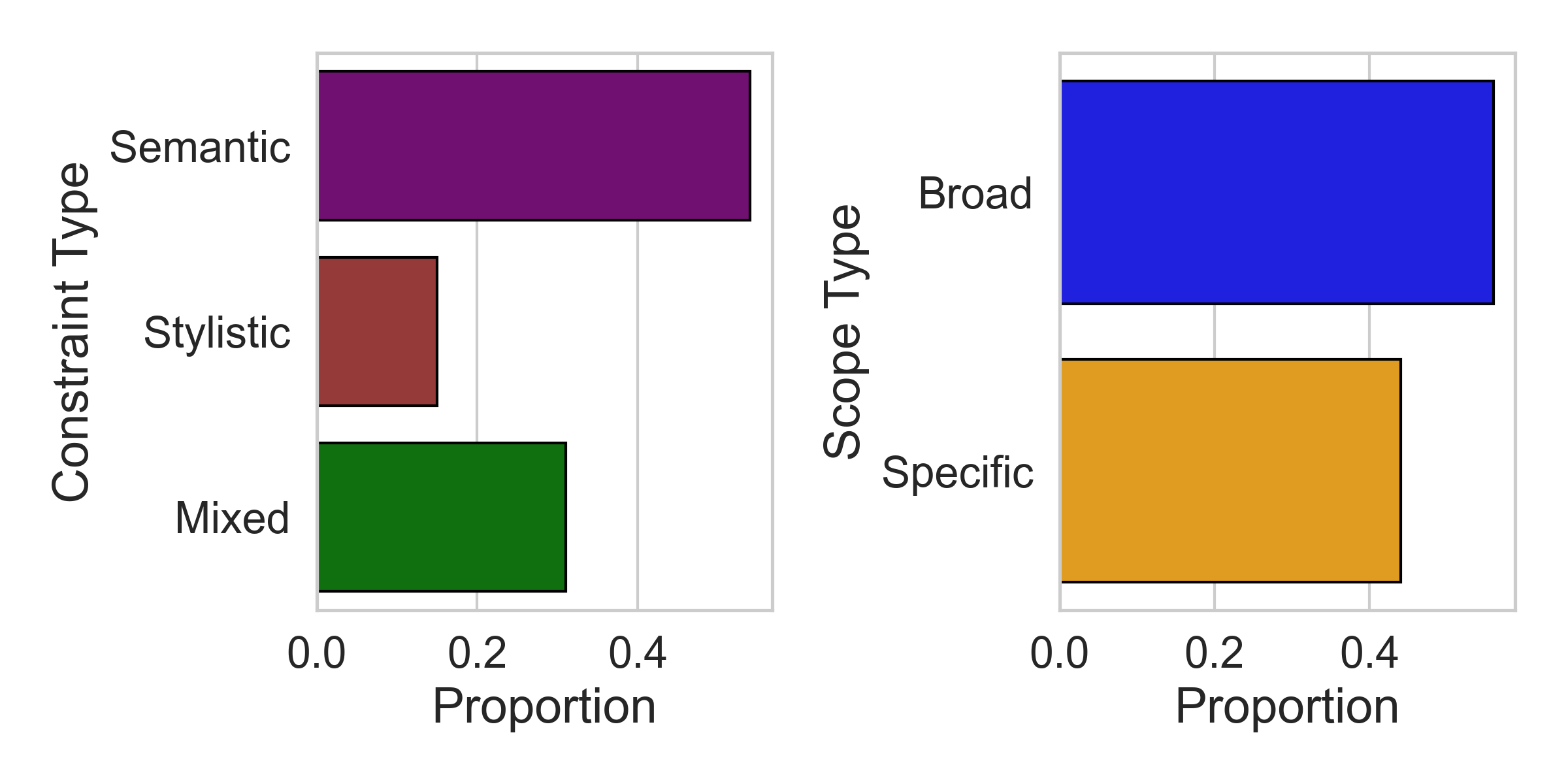
- 现有指令跟随研究主要集中在简单指令和短响应的任务上,缺乏对复杂约束下长文本生成的研究。
- 论文提出Instructional ORPO (I-ORPO) 方法,利用LLM生成的合成损坏指令作为负反馈,解决长文本偏好数据收集难题。
- 实验表明,Suri-I-ORPO模型能够生成更长(约5K tokens)且连贯性更好的文本,同时满足多重约束。
📝 摘要(中文)
本文探讨了用于生成长文本的多约束指令跟随任务。为此,作者构建了一个名为Suri的数据集,其中包含2万条人工撰写的长文本,并配以LLM生成的反向翻译指令,这些指令包含多个复杂约束。由于长文本上收集人类偏好判断的成本过高,导致DPO等偏好调整算法在此设置中不可行。因此,作者提出了一种基于ORPO算法的对齐方法,称为Instructional ORPO (I-ORPO)。I-ORPO不是接收来自非偏好响应的负反馈,而是从LLM生成的合成损坏指令中获取负反馈。作者使用Suri数据集,对Mistral-7b-Instruct-v0.2进行了监督微调和I-ORPO微调。由此产生的模型Suri-SFT和Suri-I-ORPO,生成了比基础模型显著更长的文本(约5K tokens),且没有明显的质量下降。人工评估表明,虽然SFT和I-ORPO模型都满足了大多数约束,但Suri-I-ORPO生成的文本在连贯性和信息量方面更受青睐。代码已开源。
🔬 方法详解
问题定义:现有指令跟随任务通常处理简单指令和短文本生成,难以应对包含多个复杂约束的长文本生成场景。直接应用偏好学习算法(如DPO)进行对齐,需要大量人工标注的长文本偏好数据,成本高昂且不切实际。因此,如何高效地训练模型,使其能够理解并遵循多重约束生成高质量长文本,是本文要解决的核心问题。
核心思路:论文的核心思路是利用大型语言模型(LLM)生成带有噪声的指令,作为负反馈信号,避免直接依赖人工标注的偏好数据。通过这种方式,可以有效地训练模型,使其能够区分正确的指令和错误的指令,从而更好地遵循指令生成长文本。
技术框架:整体框架包括以下几个主要步骤:1) 构建Suri数据集,包含人工撰写的长文本和LLM反向翻译生成的指令;2) 使用Suri数据集进行监督微调(SFT),得到Suri-SFT模型;3) 使用LLM生成带有噪声的指令,作为I-ORPO算法的负反馈;4) 使用I-ORPO算法对Suri-SFT模型进行对齐微调,得到Suri-I-ORPO模型。
关键创新:最重要的创新点在于提出了Instructional ORPO (I-ORPO) 算法,该算法利用LLM生成的合成损坏指令作为负反馈,避免了对人工标注偏好数据的依赖。与传统的ORPO算法相比,I-ORPO的负反馈来自指令层面,而不是响应层面,更适合于长文本生成任务。
关键设计:I-ORPO算法的关键在于如何生成有效的合成损坏指令。论文采用LLM对原始指令进行修改,例如删除、替换或添加约束条件,从而生成带有噪声的指令。损失函数的设计目标是使模型更倾向于遵循原始指令,而远离合成损坏指令。具体参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
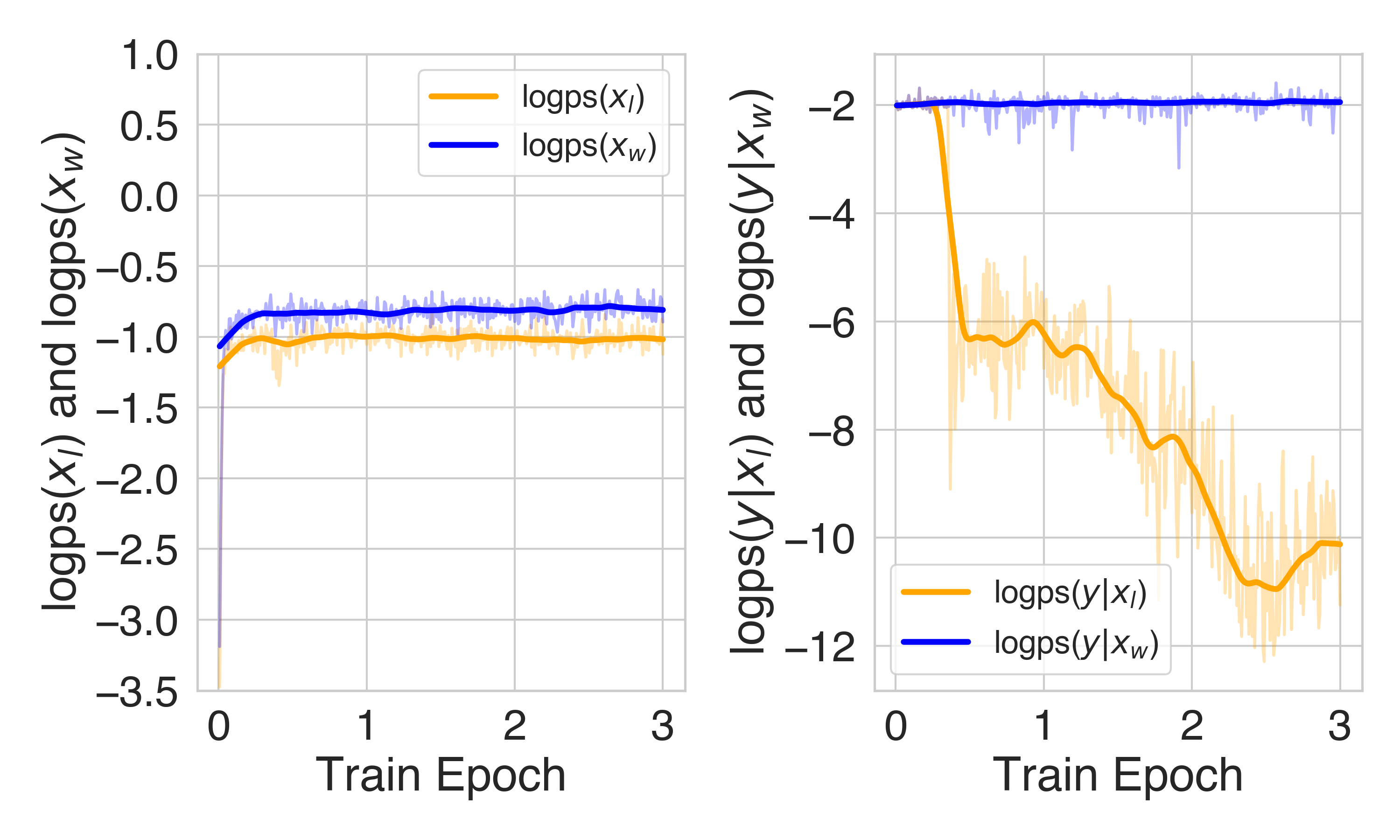
实验结果表明,Suri-SFT和Suri-I-ORPO模型能够生成比基础模型显著更长的文本(约5K tokens),且没有明显的质量下降。人工评估表明,虽然SFT和I-ORPO模型都满足了大多数约束,但Suri-I-ORPO生成的文本在连贯性和信息量方面更受青睐。这表明I-ORPO算法能够有效地提高模型生成长文本的质量。
🎯 应用场景
该研究成果可应用于多个领域,例如自动生成小说、剧本、报告等长文本内容。通过提供包含多个约束条件的指令,用户可以控制生成文本的主题、风格和内容,从而提高内容生成的效率和质量。此外,该方法还可以用于教育领域,例如自动生成练习题或作文题目,并根据学生的写作水平提供个性化的指导。
📄 摘要(原文)
Existing research on instruction following largely focuses on tasks with simple instructions and short responses. In this work, we explore multi-constraint instruction following for generating long-form text. We create Suri, a dataset with 20K human-written long-form texts paired with LLM-generated backtranslated instructions that contain multiple complex constraints. Because of prohibitive challenges associated with collecting human preference judgments on long-form texts, preference-tuning algorithms such as DPO are infeasible in our setting; thus, we propose Instructional ORPO (I-ORPO), an alignment method based on the ORPO algorithm. Instead of receiving negative feedback from dispreferred responses, I-ORPO obtains negative feedback from synthetically corrupted instructions generated by an LLM. Using Suri, we perform supervised and I-ORPO fine-tuning on Mistral-7b-Instruct-v0.2. The resulting models, Suri-SFT and Suri-I-ORPO, generate significantly longer texts (~5K tokens) than base models without significant quality deterioration. Our human evaluation shows that while both SFT and I-ORPO models satisfy most constraints, Suri-I-ORPO generations are generally preferred for their coherent and informative incorporation of the constraints. We release our code at https://github.com/chtmp223/suri.