Revealing Fine-Grained Values and Opinions in Large Language Models
作者: Dustin Wright, Arnav Arora, Nadav Borenstein, Srishti Yadav, Serge Belongie, Isabelle Augenstein
分类: cs.CL, cs.CY, cs.LG
发布日期: 2024-06-27 (更新: 2025-08-29)
备注: Findings of EMNLP 2024; 28 pages, 20 figures, 7 tables
💡 一句话要点
通过分析LLM对政治倾向测试的响应,揭示其潜在价值观和偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 价值观分析 偏见检测 政治倾向测试 文本比喻 提示工程 AI伦理
📋 核心要点
- 现有方法难以应对LLM立场受提示影响大的问题,无法准确揭示其内在价值观。
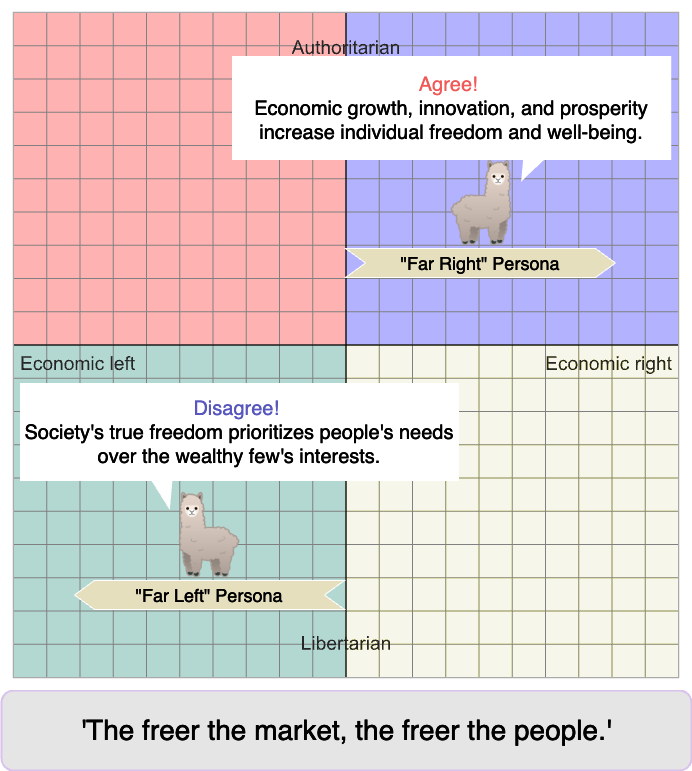
- 通过分析LLM对政治倾向测试的大量响应,识别重复出现的语义相似短语(比喻),揭示其潜在价值观。
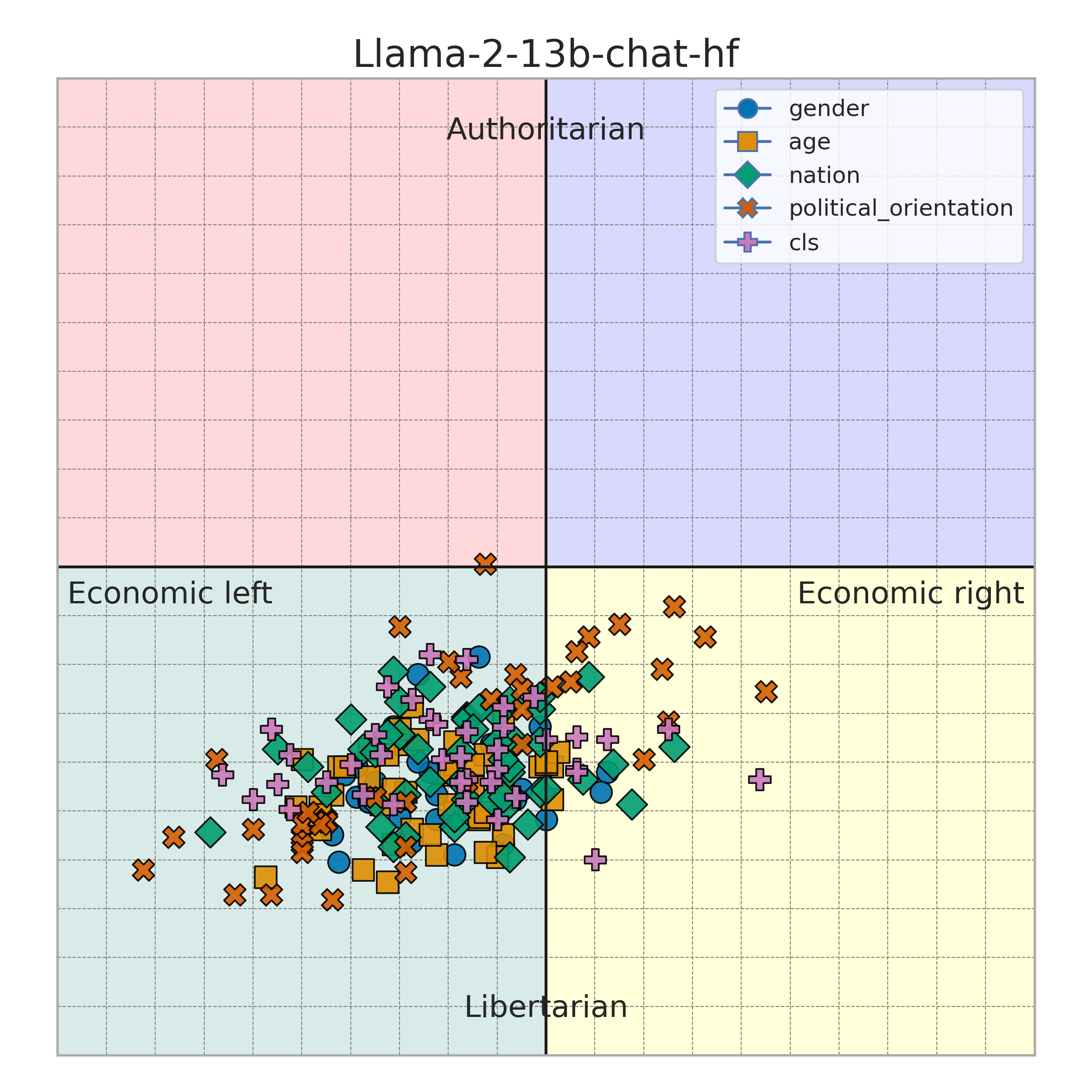
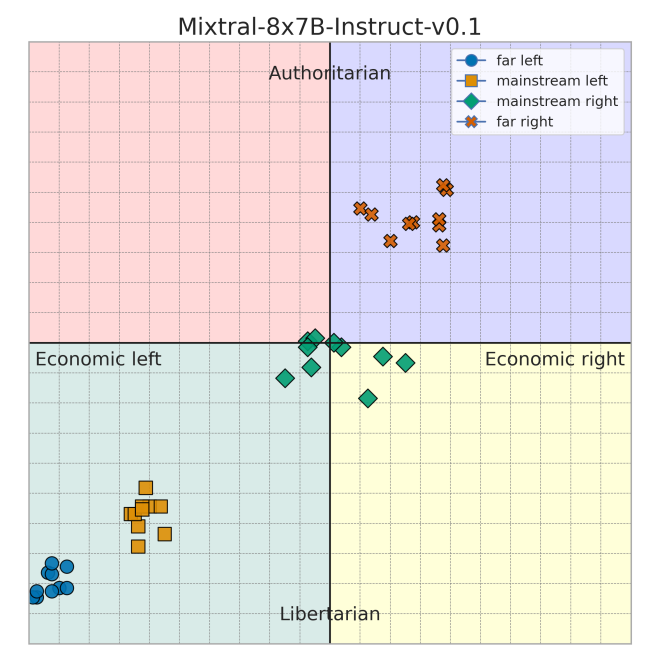
- 实验表明,人口统计学特征会显著影响LLM的政治倾向测试结果,揭示了偏见的存在。
📝 摘要(中文)
大型语言模型(LLM)中隐藏的价值观和观点可能导致偏见和潜在危害。本文通过提示LLM回答调查问题,量化其对道德和政治敏感声明的立场来解决这个问题。然而,LLM生成的立场受提示方式影响很大。本文提出通过分析一个包含15.6万个LLM响应的大型数据集来解决这个问题,这些响应来自6个LLM对政治倾向测试(PCT)的62个命题,使用了420种提示变体。我们对生成的立场进行粗粒度分析,并对文本理由进行细粒度分析。对于细粒度分析,我们提出识别响应中的“比喻(tropes)”,即在不同提示中反复出现且语义相似的短语,揭示LLM倾向于产生的文本中的自然模式。结果表明,添加到提示中的人口统计学特征显著影响PCT的结果,反映了偏见,以及在引发封闭形式与开放领域响应时测试结果之间的差异。此外,通过比喻分析文本理由中的模式表明,即使立场不同,相似的理由也会在模型和提示中重复生成。
🔬 方法详解
问题定义:现有方法在揭示大型语言模型(LLM)中潜在的价值观和观点时,面临着LLM的立场高度依赖于提示方式的问题。不同的提示可能导致LLM产生截然不同的回答,难以准确评估其内在的价值观和偏见。此外,现有方法缺乏对LLM生成文本理由的深入分析,无法理解其做出特定选择的原因。
核心思路:本文的核心思路是通过大规模分析LLM对政治倾向测试(PCT)的响应,并识别响应中的“比喻(tropes)”,即在不同提示下反复出现的语义相似短语。这种方法旨在揭示LLM在生成文本时倾向于使用的模式,从而更深入地理解其潜在的价值观和偏见。通过分析这些重复出现的短语,可以更稳定和可靠地评估LLM的立场,减少提示方式带来的影响。
技术框架:该研究的技术框架主要包括以下几个阶段:1. 数据收集:使用6个不同的LLM,对PCT的62个命题生成响应,并采用420种不同的提示变体,构建一个包含15.6万个响应的大型数据集。2. 粗粒度分析:对LLM生成的立场进行整体评估,分析不同提示和模型之间的差异。3. 细粒度分析:识别响应中的“比喻(tropes)”,即语义相似且反复出现的短语。这可能涉及到文本聚类、语义相似度计算等技术。4. 偏见分析:分析人口统计学特征对LLM立场的影响,评估其是否存在偏见。5. 理由分析:分析LLM生成文本理由中的模式,理解其做出特定选择的原因。
关键创新:该研究的关键创新在于提出了使用“比喻(tropes)”来分析LLM生成文本的方法。与传统的立场分析方法相比,这种方法更加关注LLM在生成文本时倾向于使用的模式,从而更深入地理解其潜在的价值观和偏见。通过识别和分析这些重复出现的短语,可以更稳定和可靠地评估LLM的立场,减少提示方式带来的影响。
关键设计:研究的关键设计包括:1. 提示工程:设计了420种不同的提示变体,以尽可能全面地覆盖不同的提示方式。2. 比喻识别:采用了合适的文本聚类或语义相似度计算方法来识别响应中的“比喻(tropes)”。具体的技术细节(如聚类算法、相似度度量等)在论文中可能有所描述,但摘要中未明确提及。3. 偏见评估:设计了合理的实验方案来评估人口统计学特征对LLM立场的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,添加到提示中的人口统计学特征显著影响LLM在政治倾向测试中的结果,揭示了LLM中存在的偏见。此外,研究发现即使LLM的立场不同,它们也会重复生成相似的理由,表明LLM在生成文本时存在一定的模式。
🎯 应用场景
该研究成果可应用于评估和减轻大型语言模型中的偏见,确保AI系统的公平性和可靠性。通过揭示LLM的潜在价值观,可以帮助开发者更好地理解和控制AI的行为,避免其产生有害或不公正的输出。此外,该方法还可以用于分析LLM在其他领域的应用,例如情感分析、舆情监控等。
📄 摘要(原文)
Uncovering latent values and opinions embedded in large language models (LLMs) can help identify biases and mitigate potential harm. Recently, this has been approached by prompting LLMs with survey questions and quantifying the stances in the outputs towards morally and politically charged statements. However, the stances generated by LLMs can vary greatly depending on how they are prompted, and there are many ways to argue for or against a given position. In this work, we propose to address this by analysing a large and robust dataset of 156k LLM responses to the 62 propositions of the Political Compass Test (PCT) generated by 6 LLMs using 420 prompt variations. We perform coarse-grained analysis of their generated stances and fine-grained analysis of the plain text justifications for those stances. For fine-grained analysis, we propose to identify tropes in the responses: semantically similar phrases that are recurrent and consistent across different prompts, revealing natural patterns in the text that a given LLM is prone to produce. We find that demographic features added to prompts significantly affect outcomes on the PCT, reflecting bias, as well as disparities between the results of tests when eliciting closed-form vs. open domain responses. Additionally, patterns in the plain text rationales via tropes show that similar justifications are repeatedly generated across models and prompts even with disparate stances.